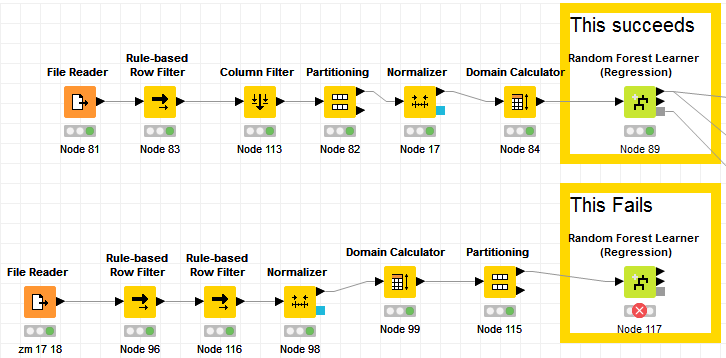
My Random Forest regression learner is failing at 10% because of this
ERROR Random Forest Learner (Regression) 2:117 Execute failed: java.lang.StackOverflowError
I believe this is happening with one particular file, as another table is successful, even though they are derivatives of the same dataset and contain the same features (22) and similar number of rows (~60,000). I’m attempting to understand why this one file seems to always produce this error UNLESS I take it down to 3 or 4 features, but I can’t find anything on this error to understand why it’s happening on this file. Any ideas? Attached is a screenshot of the two basic workflows, which are not the neatest, but I’m curious what is causing this, even if it’s upstream related.
In this case the successful RFL (top) has almost 2x more rows than the unsuccessful RFL.
I have not seen this error until after I updated to 3.7 (today), but admittedly I hadn’t tried it on the problematic table before updating.
Note: The problematic file is a .tsv, and the successful file is a .csv. Could it really be that simple? I am converting to test and will update.
Update: a .csv of the file did not fix the error.
Second update: Attempting from the base files also produces the same error pattern. I’m really looking for what the stack overflow error could mean and why my one file is causing it!
You could try to apply missing values and see how that goes, and also check if there are not strange NaN values, then the question is if it is with every 3-4 variables that the tree fails or can you nail down the column that is causing it. And you could check the domain calculator and see if it covers every value.
Thank you, I feel like this makes sense and now I know what to look for if I receive this error again. So happy to have this solved, I was pulling my hair out for a few hours
would it be possible for you to share the workflow with me, so I can debug the code and find out what is happening.
If that is not an option, could you please post the entry in the KNIME log that relates to the error (it should contain a stacktrace).
Both normalization and missing values should not pose a problem to the RF Learner, as it is invariant to normalization and has built-in means to deal with missing values.
If possible in this thread although I fear that the workflow might exceed the upload limit.
Could you otherwise send me a private message with a link to a dropbox/google drive folder containing the workflow?