Hello how are you?
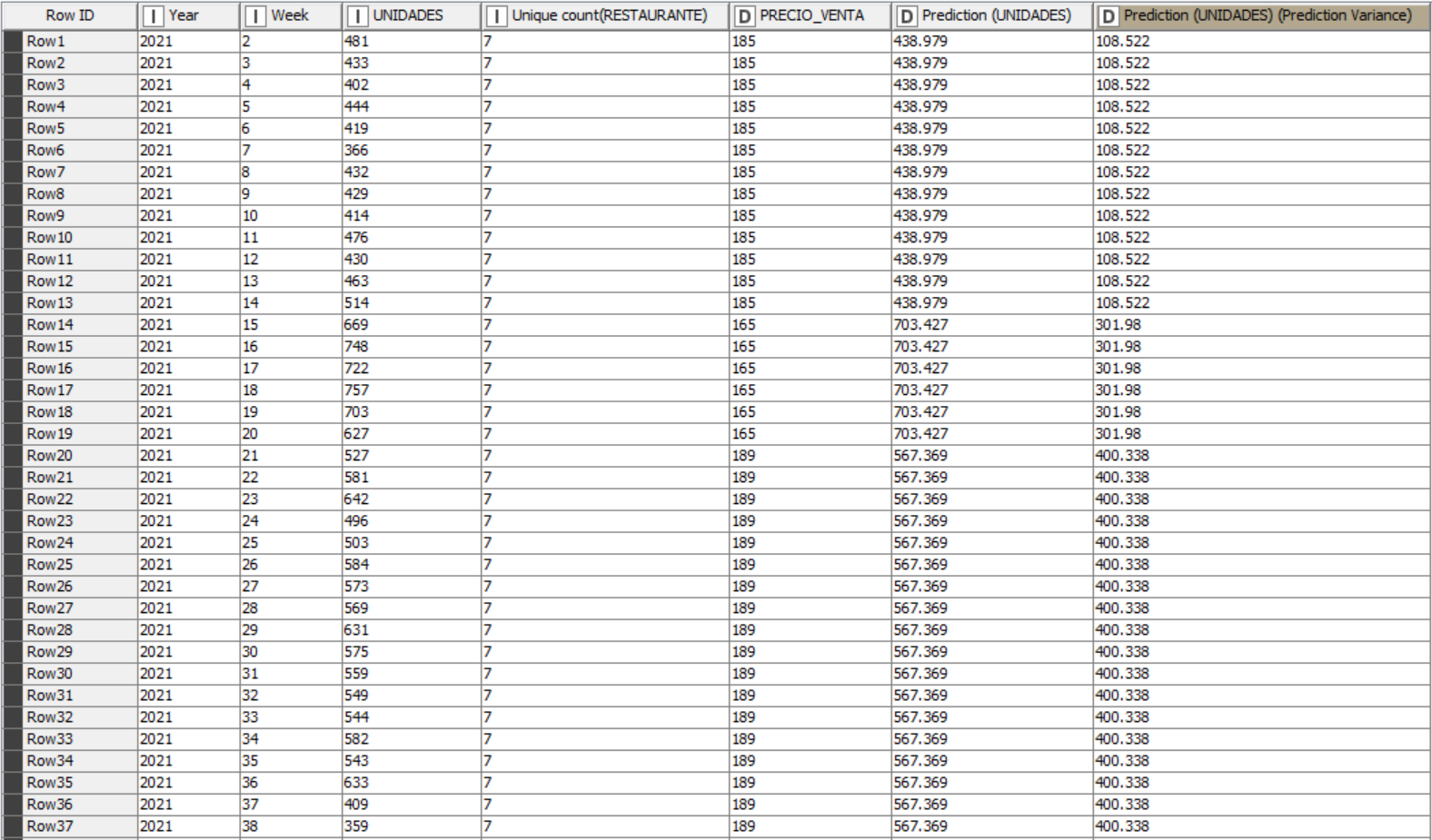
I worked in a flow that allows us to see the price-demand elasticity of the products of the company where I work. Use two paths to have the option of two different models, the first was a logarithmic regression and the second was a random forest regression.
The model that worked the best for my data set was the random forest regression, I am working with a history of units sold and prices from 2021 to date, however now the objective is for the model to predict how many units will be sold at the new price that I indicate and with this I can verify if that price would suit me or not. But I don’t know how to inform the model of that new price and using the random forest predictor to tell me the units that will be sold.
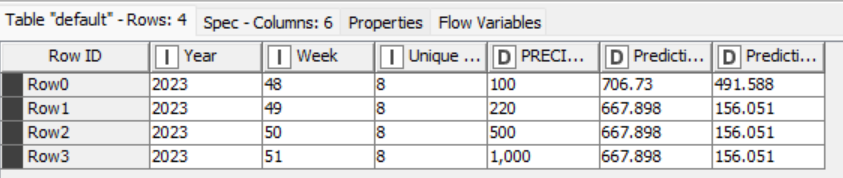
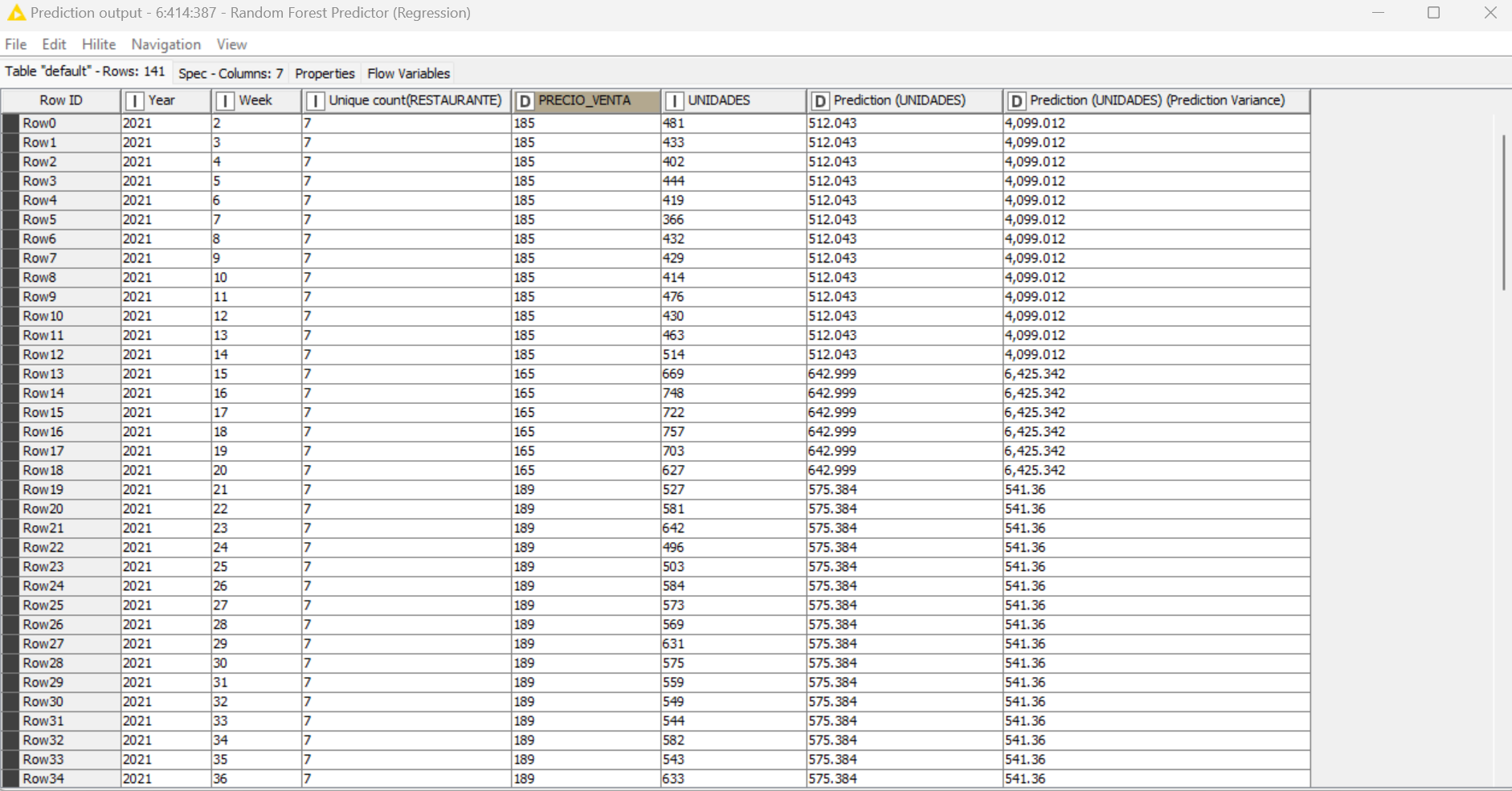
These are my predictions and my r2 went very well, now I just need the step of adding a new price and having it predict the units that are going to be sold.
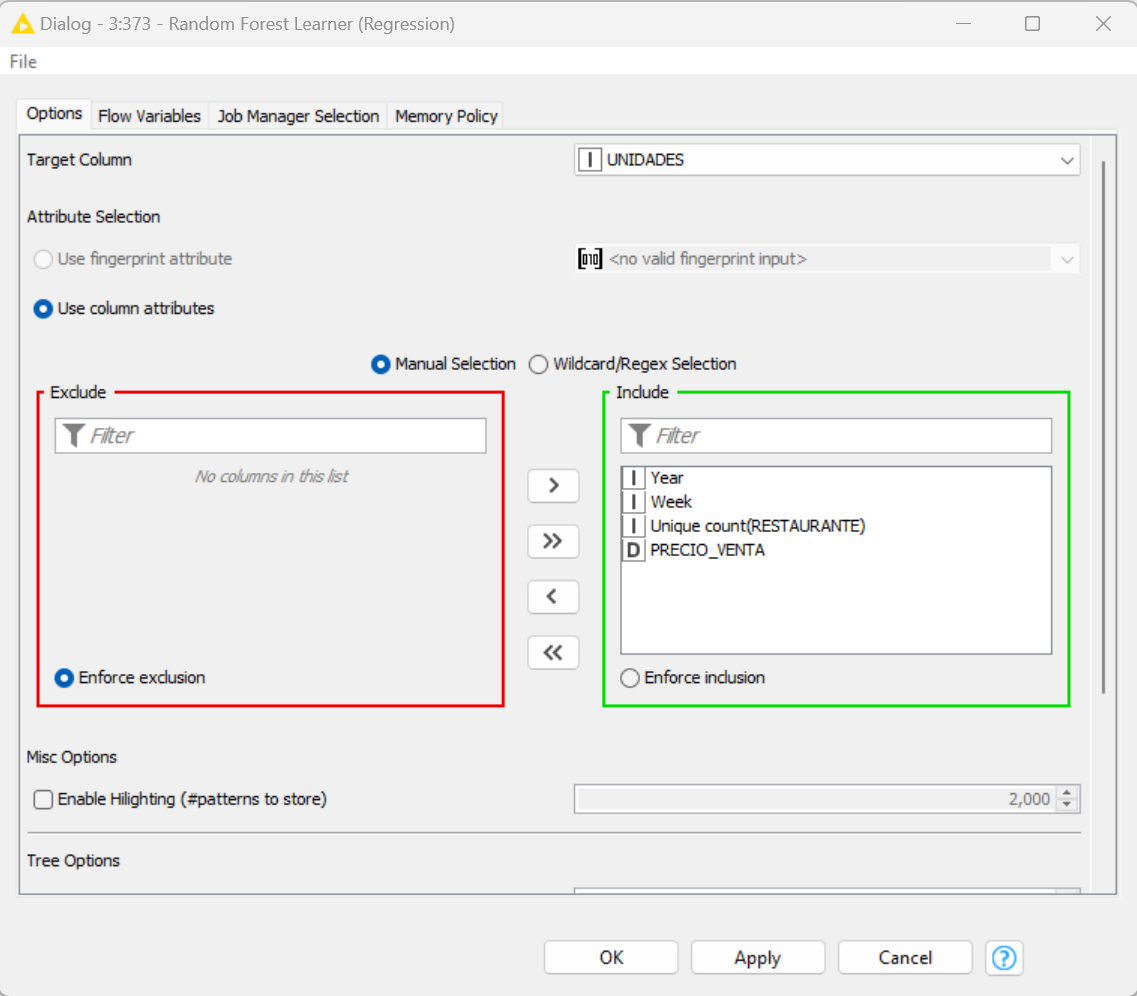
It appears that the only attribute (predictor) you’re using is price. Write your model out from the Learner node and feed it and a new set of price data to a new Predictor node. Is there any possible seasonality that a regression model won’t account for well?
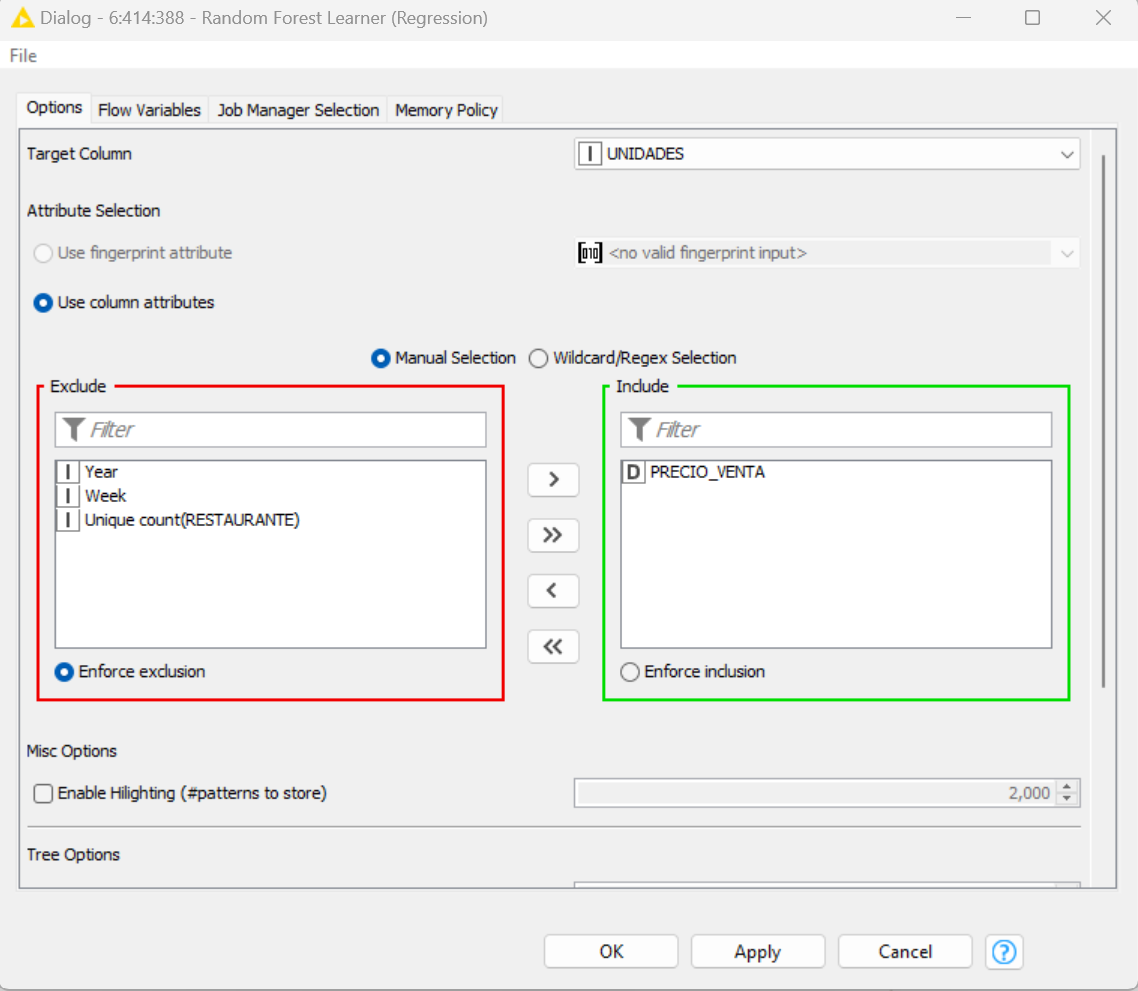
Hello! This is the final part of my model, I have already made the partition to train it and do the respective tests, before it only included the price and it went well, now I included everything else and it improved a lot. However, I don’t know how to make the model indicate how many units will be sold at a price of 250, for example. I want it to predict the units that will be sold at a new price with the information I am giving it.
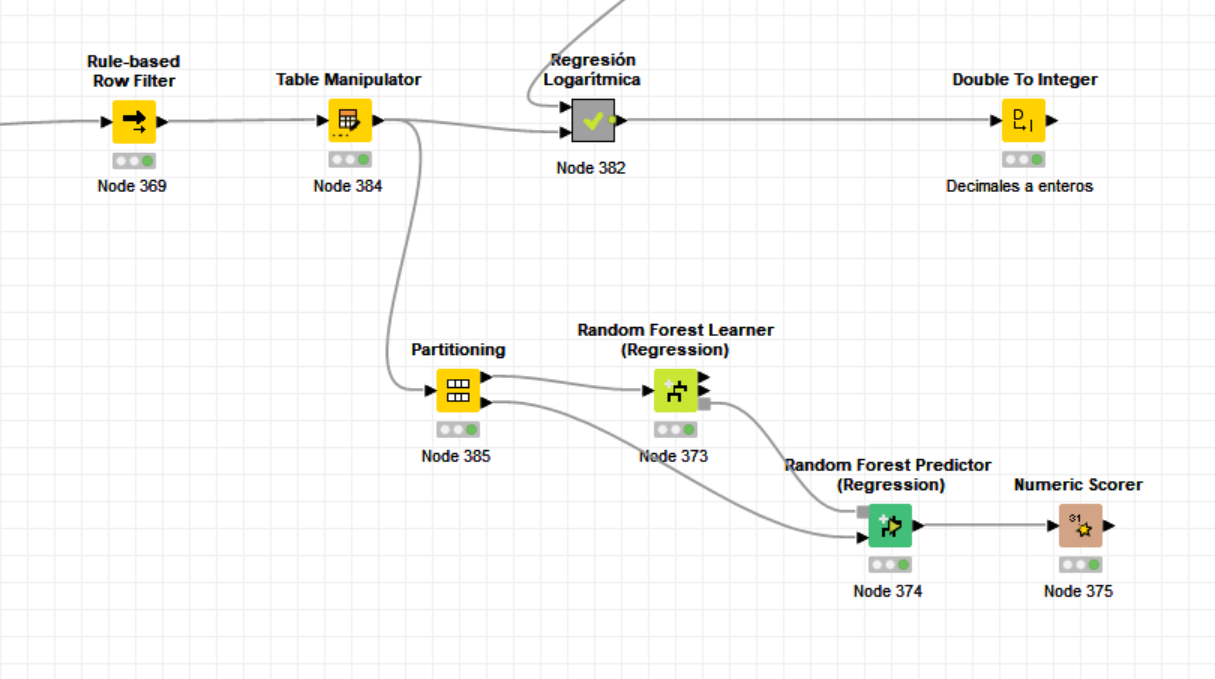
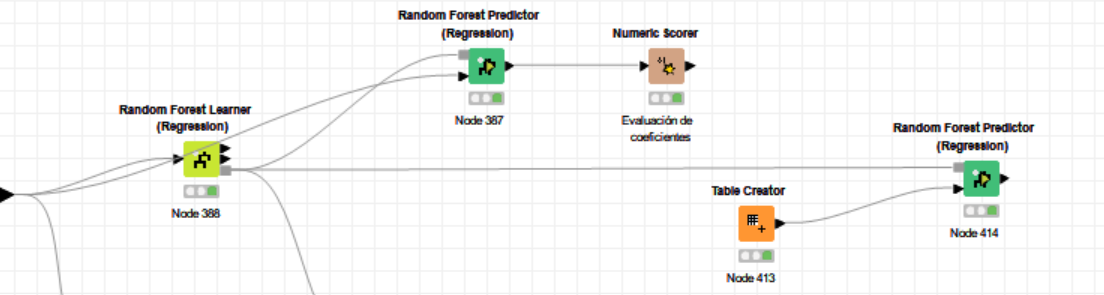
They are images of the final part of the flow, the random forest learner (regression) and the table that returns the random forest predictor (regression). Now I want the model to predict how many units will be sold at a price of 250, for example.
@jose_giron
You can save your model using Model writer node and load it into a new workflow. (Model reader)
To make predictions you need new data which has the same columns as your training data. So if your model predicts units then price is one of the features I guess so you have new data where the price column contains e.g. 250
br
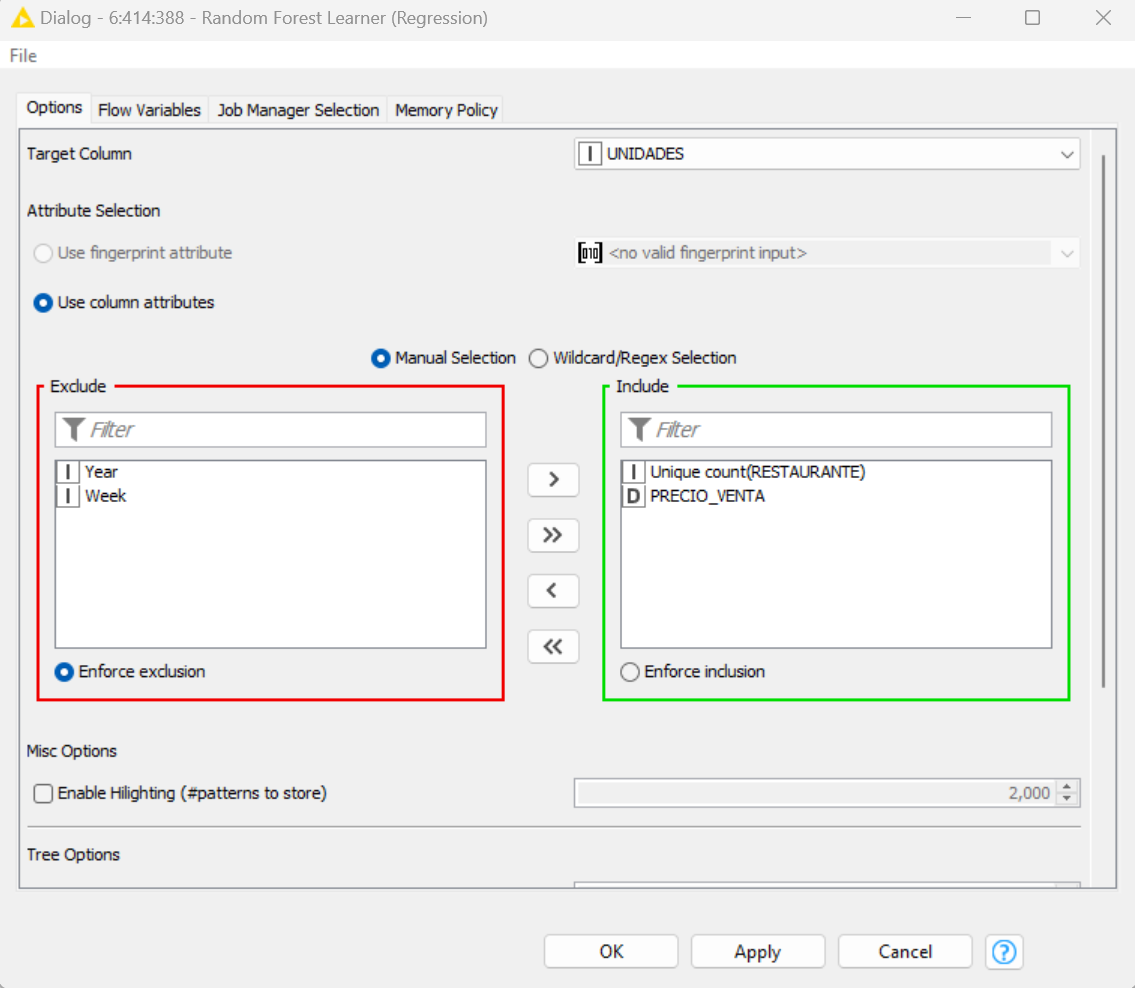
Thank you for your help and your comments. The model improved according to what I have been told, however, now I want it to predict how many units will be sold at a price of 250, I am going to create a new data set but obviously I will not be able to include the units sold, since that is what I want to predict , instead of having five columns my new data set would have four columns, correct?
You need a new data set with the same attribute columns as used in the model learner. In your case the number of restaurants and price. You don’t need a target column as this will be provided by the learned model. As both @Daniel_Weikert and I previously said write out the model with the a Model Writer node fed from the model port in the Model Learner. Then feed your new data to the data port of a new predictor node. Use a Model Reader node to read the learned model you previously saved and feed this to the model input port of the the new predictor. These three nodes are not connected to your original model and can be an entirely separate workflow.
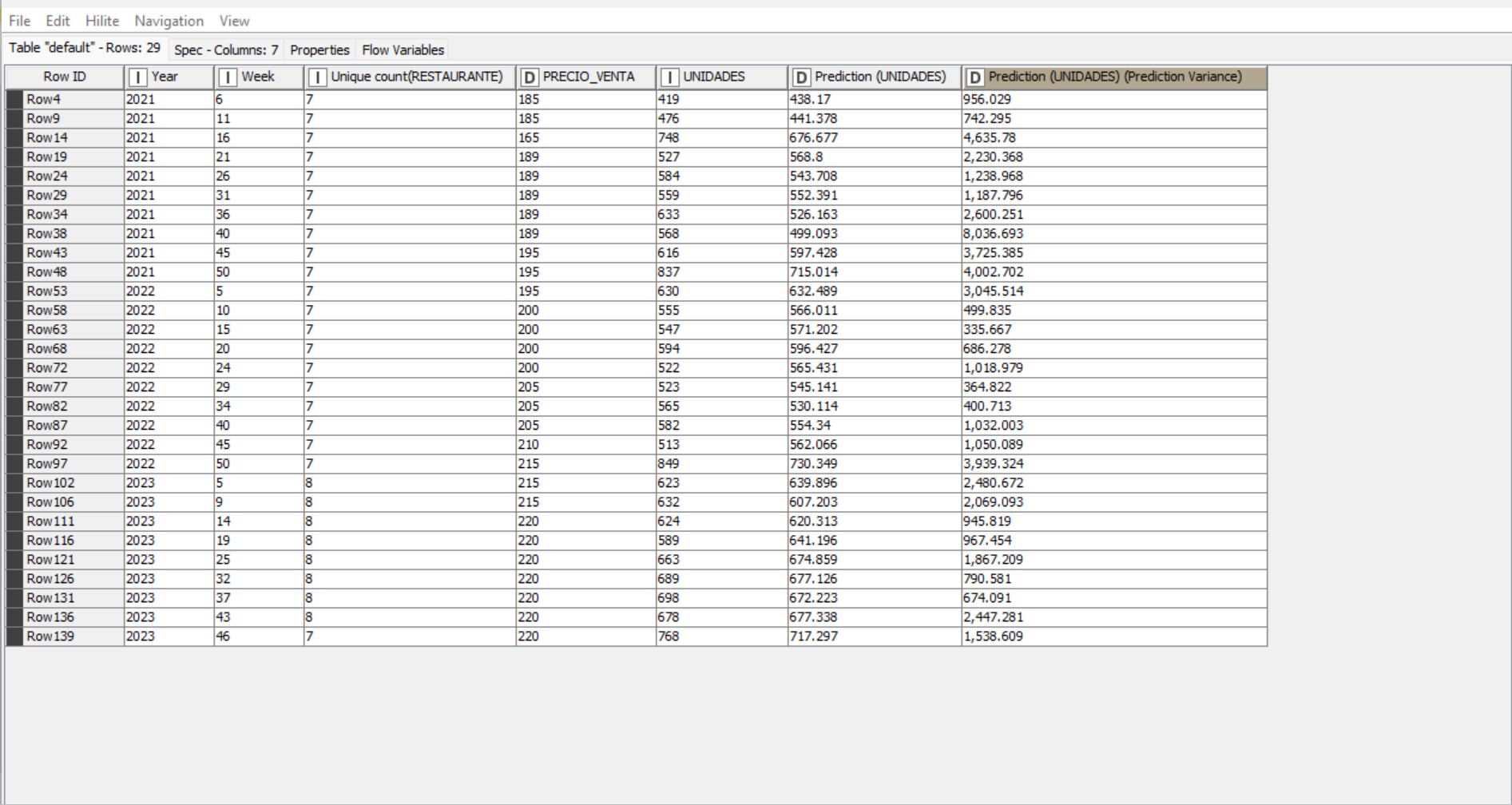
Thank you all for your help, it was very useful. Could I ask you why, even if I considerably increase or decrease the price, the quantity that the model predicts remains the same?
Sorry, I’m working with a DB Connector and a DB Query Reader and the head of data governance would have to authorize me permissions to be able to view the data warehouse tables.
I don’t know if it’s too much to ask, but I could explain what I did in some virtual meeting just if you had the time.
In the meantime add # restaurants to the second predictor node. Your screenshot shows you’re using a learner node. Reread my earlier instructions post.
@jose_giron may recommendation would be to think about what it is you want to predict and what data you have that might be relevant for thec task.
The the question is what method would be suitable. Just a regression model or is it some sort of simulation or is it the willingness to pay prices. These might require different settings and methods. Also some relations might not just be linear.
Then in the screenshot you seem just to use the same data for training and validation which is not a good setup.
If your business is dependent on seasons you might have to include this information. During holidays more people might visit (or not).
My recommendation would be to invest more in research understanding and planning.
What could help is find a dataset or Kaggle challenge that matches your case.
Can’t tell whether you’ve properly partitioned the original data set. @mlauber71 appears to be correct, i.e. you’re using the same data for training and testing, but without the complete workflow its hard to tell what’s going on. Study some models on the Hub to learn how to construct a proper model. Like @mlauber71 I’m skeptical that a linear regression without considering other relevant factors will produce useful results. Its dangerous to believe a model simply because it runs and seems to “make sense.”