This is not an issue but rather some guidance requested. I have tried a few things but this must be too advanced for my current understanding.
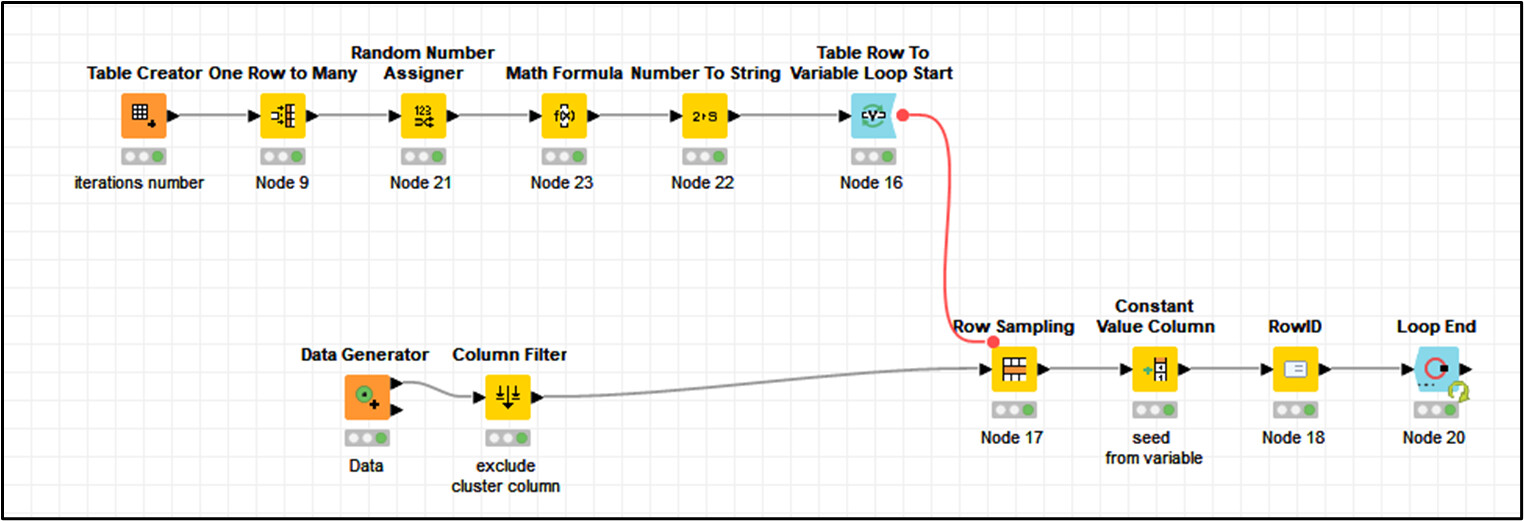
Say we have a flat file with a 100 columns and millions of rows. How does one create a workflow that, with use of a random seed, selects 1 value from each column, iteratively, for a stated amount of iterations. The number of rows in the final output will be equal to the stated amount of iterations. Each one of them labelled with an iteration number.
And for each iteration, the random seed used must be populated in its own column. So there will be 102 columns (100 columns + iteration number + random seed number) with x rows equal to the amount of iterations.
I think with partioning node within a loop you could select with random seed. However if I understand correctly you also want to have a random row for each column so you would probably need to wrap this in a column list loop start too
Other option might be code snippets
br
@Daniel_Weikert
I have a doubt in this point. If you use a seed for each column in loop, and you want to save the output seeds; then you need a seed matrix with a value for each cell.
However the description request one seed per row.
To achieve a seed per column as well, the idea would be a nested Column List Loop Start and a loop end with two ports. (values, seeds).