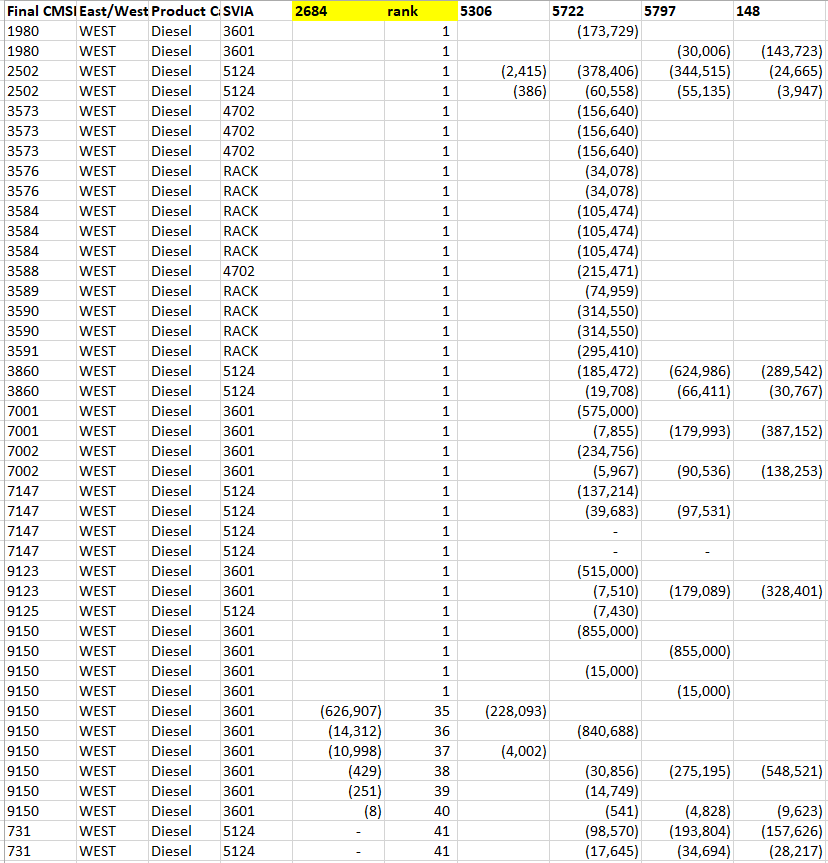
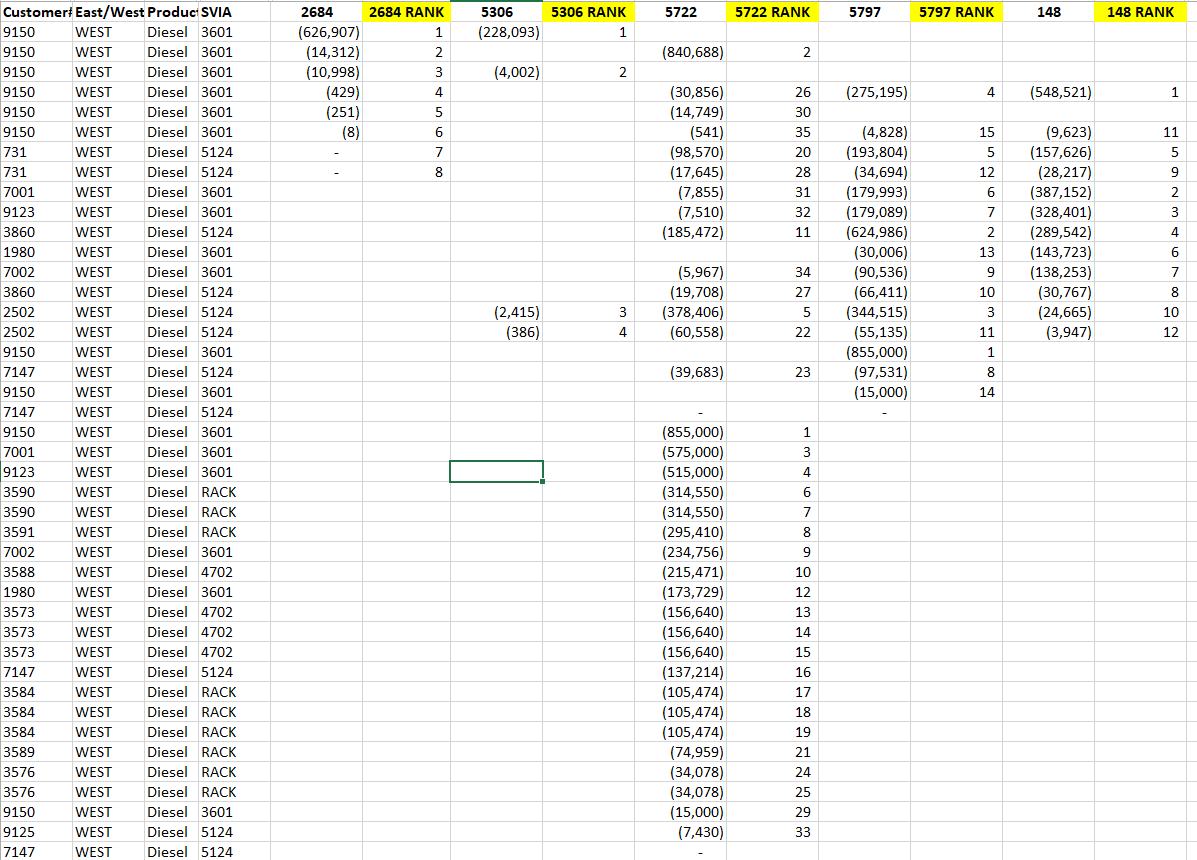
Hello, can someone suggest a solution for this: I need to rank the dataset shown here by lowest value as 1 and ignoring blank cells. You can see here that I’ve tried to do it with a simple rank for column “2684” after sorting it.
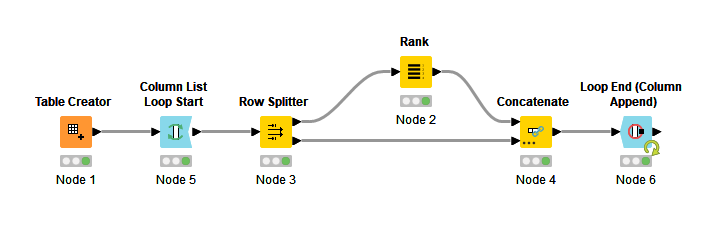
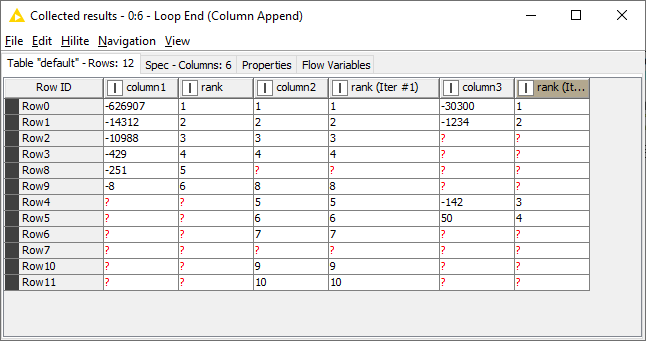
One approach is to use a row splitter to remove the rows with missing values, then conduct your ranking, then concatenate the rows with the ones you split earlier to reproduce the table.
If you sandwich this sequence of nodes between a Column List Loop Start node and a Loop End (Column Append) node (and adjust some settings to use flow variables to specify the column names to be split and ranked) you can iterate over multiple columns.
Hi @elsamuel and @MJRIOUX,
it looks like you talk at cross-purposes about upload off an example workflows. If i understood @MJRIOUX correct he/she asked you @elsamuel if you could kindly upload/share your example workflow.
@MJRIOUX
my Interpretation of the workflow from @elsamuel is.
1.) loop over columns
2.) exclude the rows with missing data from ranking via row splitter.
3.) combining ranked rows with previous excluded missing value rows to achieve the final table.