Hi,
I am using RDKit to transform SMILES strings into SDF representations of Molecules. The problem is, that for compounds containing heteroaromatic cycles with one or more Nitrogens the conversion fails.
I tried it with direct conversion from SMILES via the RDKit to Molecule node, there he creates empty input cells.
Using the RDKit from Molecule node he fails to create RDKit Molecules if for the sanitization “reperceive aromaticity” is ticked. Unfortunately the conversion with the RDKit to Molecule node still fails for the 20 molecules.
I am not sure if there is something going wrong in RDKit itself or if its just the KNIME nodes, I would love to use RDKit in the future as it is open source and has amazing functionality, so it would be great to get some advice on how to handle such structures.
I have attached the Structures along with the Error column.
Otherwise I am using KNIME 3.5.2 with Ubuntu 16.04 LTS
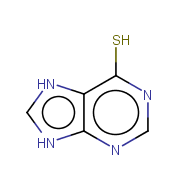
Looks like there might be a problem with some of your SMILES. For example the first SMILES, Sc1ncnc2[nH]c[nH]c12 is rendered in MarvinSketch as:
If you look, you can see that one of the explicit [nH]s is surplus to requirements. The second SMILES has an explicit [nH] on a quinoline nitrogen atom. RDKit is rejecting these because they are incorrect - either could be made correct by either removing one of those explicit H’s ([nH] becoming n), or by setting the nitrogen to have a positive charge ([nH] becoming [nH+])
Thank you very much for pointing this out. It seems RDKit just sees more than I do
Any idea or pro-tip how to get rid of such errors? Dismissing this compounds or annotating by hand does not seem to be a satisfactory solution.
I would suggest doing exactly what you have done with the explicit conversion to RDKit, and then use a row filter node to removed missing values in the converted molecules column. I suppose whether that is satisfactory depends on the size of your dataset - if it is a few compounds out of several thousand or 10s of thousands, then that might not be a big deal, but if it is a much bigger proportion then you will need to look at where those SMILES are coming from, and whether there is something you can do to fix them upstream / at source.