I would need your suggestions for the subject I have never worked with.
I have access to raw data with clients’ opinions and to the platform that turns those opinions into sentiment analysis, tags, tag cloud, and the dashboard. Sentiment analysis looks OK (ratings are in line with the sentiment), however I have some doubts regarding tagging.
The key raw data are:
OPINION descriptive clients’ feedback. A couple of languages are present here.
RATING of 1, 2, 3, 4 or 5 where 1 stands for the lowest rate and 5 stands for the highest one.
SENTIMENT with positive, neutral, or negative values assigned.
TAG # - multiple columns dedicated for tags. The thing here is that there are non-blank opinions with no tags assigned.
Other data refers to products, distribution channels, clients’ details, etc.
Unfortunately, I can’t share sample dataset and – therefore - I can’t use public AI platforms while building the workflow.
I would need your suggestions on what the logic/sequence of nodes should be used to achieve two main goals:
Re-assign tags based on OPINION.
Identify areas requiring improvements.
Then, I could start building my tool based on your suggestions.
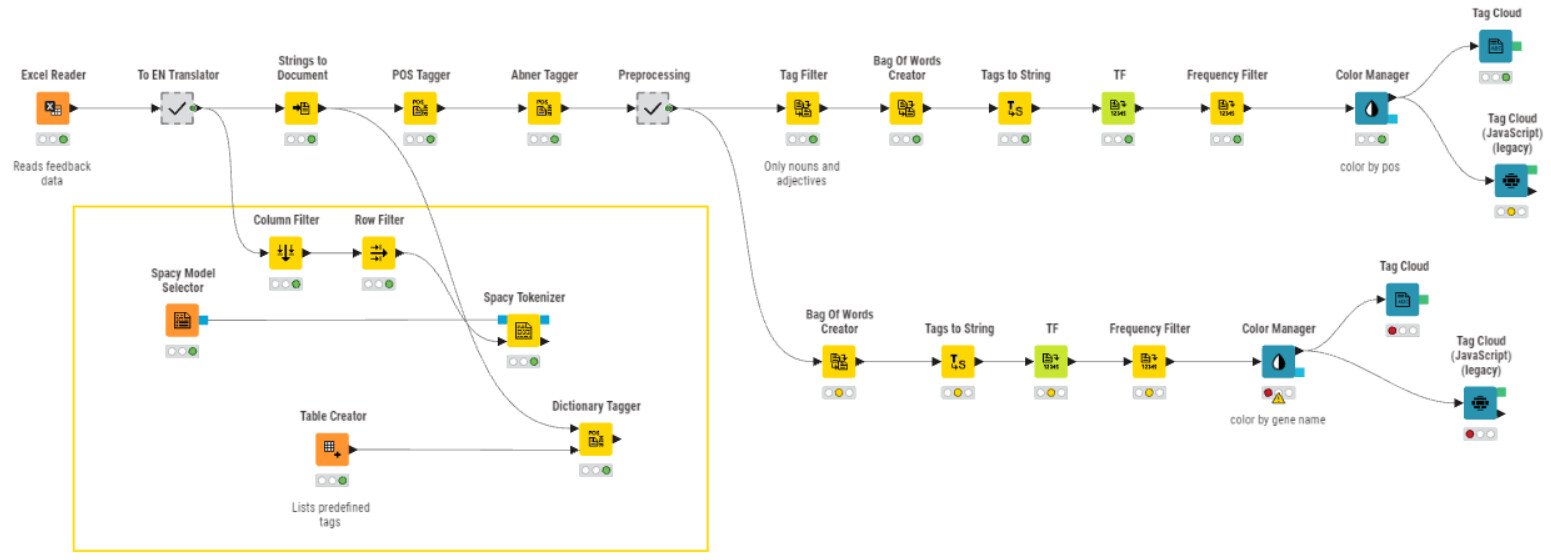
I have added metanode to translate OPINION col to English (depending on source language of course).
I have run the workflow specified above to generate tag cloud.
The challenge: tag cloud contains one-word tags only while phrases would be expected. Tag ‘product’ is neutral while there is huge difference between ‘good product’ and 'bad product’.
I have tried other tagging options with no positive results (see yellow annotation below).
Any suggestions to get identify phrases present in OPINIONs as tags?
OK, I’ve gone through proposed solutions and discovered that:
They don’t refer to tagging.
They use sentiment confidence index that is available in entry dataset. No such index in my dataset, so I would need to calculate it – and this is beyond my capabilities today.
In addition to the above, you could give simple BERT a try, specifically, the zero shot classification models in case you don’t have a labelled set to fine-tune. For simple classification problems, llms might be overkill , but both are worth giving a shot (e.g. you could compare results on a small sample)
Unfortunately, I must admit that I won’t follow up with this topic. This a kind of side task, not a priority at all, and I would need to invest a looooot of efforts to grab the necessary knowledge. Not now.
We could treat this topic as closed with no solution.