An interesting challenge @kowisoft, and it’s always interesting to see some great ideas for solving problems like this. I enjoy reading them, as sometimes it gives a different angle on methods to use in the future for related (and even unrelated problems).
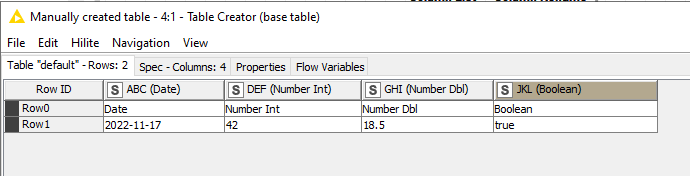
Some time back I wrote myself a component for setting the types according to a “template” table, so not quite the same challenge as yours but there are parallels. The problem I was trying to counter was where data was being read in from a data file, but there was no guarantee that on a given occasion, all columns would necessarily contain data, and so sometimes KNIME did not know the type of a particular column. My solution was to provide a “template” table containing a single row, and in that row would be sample data of the correct type, so for example… the “template” table would look like this:
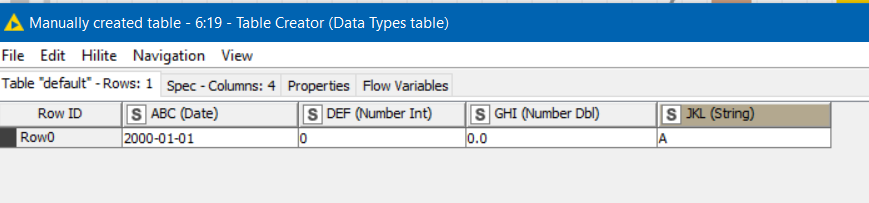
(and I’m purposely changing your example to a String in the 4th column instead of the Boolean for now. More on that in a moment)
The component would then concatenate this row to the data set, making this the first row of the table
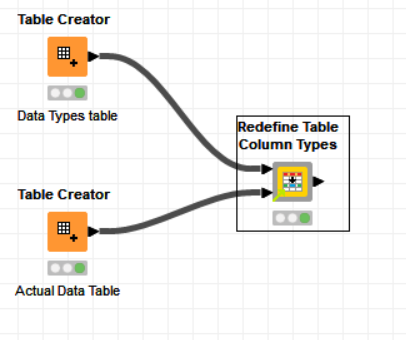
And (assuming the theory was sound  ) out of the other end would pop the table with the required data types.
) out of the other end would pop the table with the required data types.
To achieve this, I made use of the Column Auto Type Cast node, so I didn’t have to know much about the individual data types, or do any special treatment. I’d just let Column Auto Type Cast handle it, and specifically I would tell Column Auto Type Cast to scan only the first row (which of course would be the template table row). Once it had set the data types, it would return rows 2 onwards back to the output data port.
So it meant there was no looping through columns, but there was the odd flaw in the plan… isn’t there always? 
… Which brings me back to the Boolean. I didn’t find a way to force Column Auto Type Cast to treat “true” or “false” as a Boolean. It frustratingly always returned it as a String. However, the workaround in that situation was to ensure that the column on the template table had the correct data type (Boolean) in the first place, which rather defeated my plan for world domination (!) but it mostly achieved my objective.
I’ve uploaded a sample using your workflow.
Define Column Types.knwf (79.3 KB)