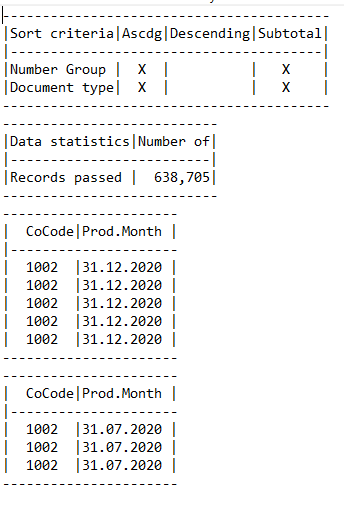
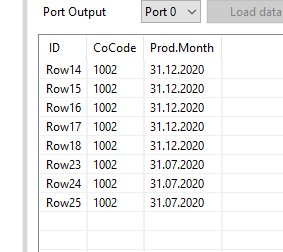
As u can see in the image there are several tables. The first two are information about format and download. The third is the information separated into multiple pages.
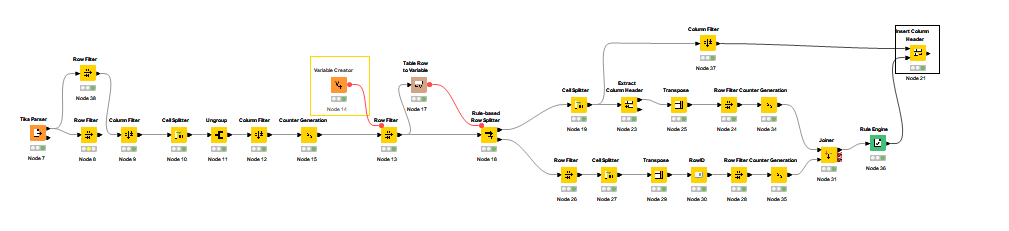
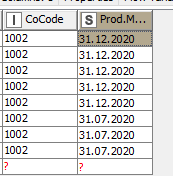
I used TikaParser for reading and after a long workflow I got the the third part as I wanted but I feel like there must be a better way.
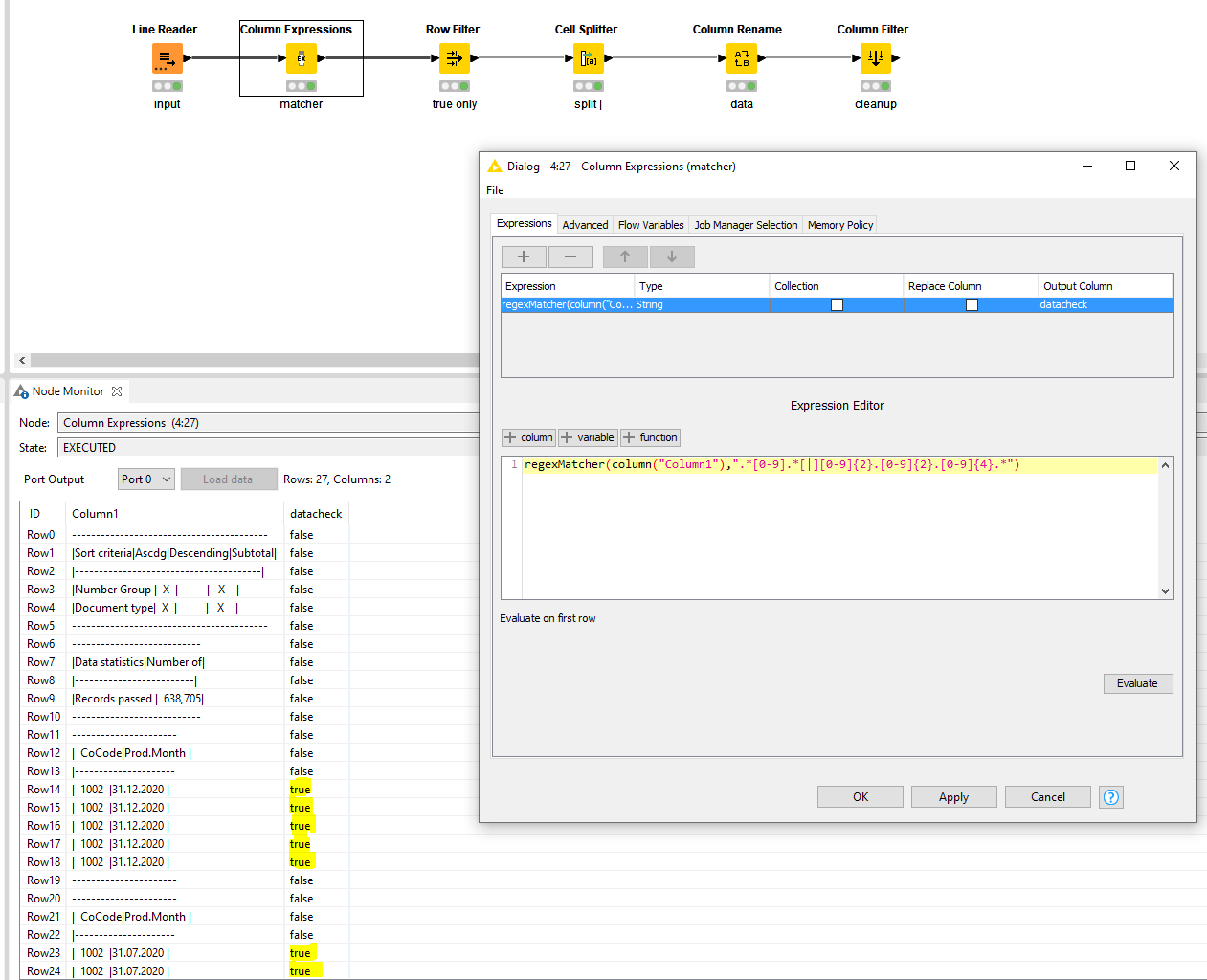
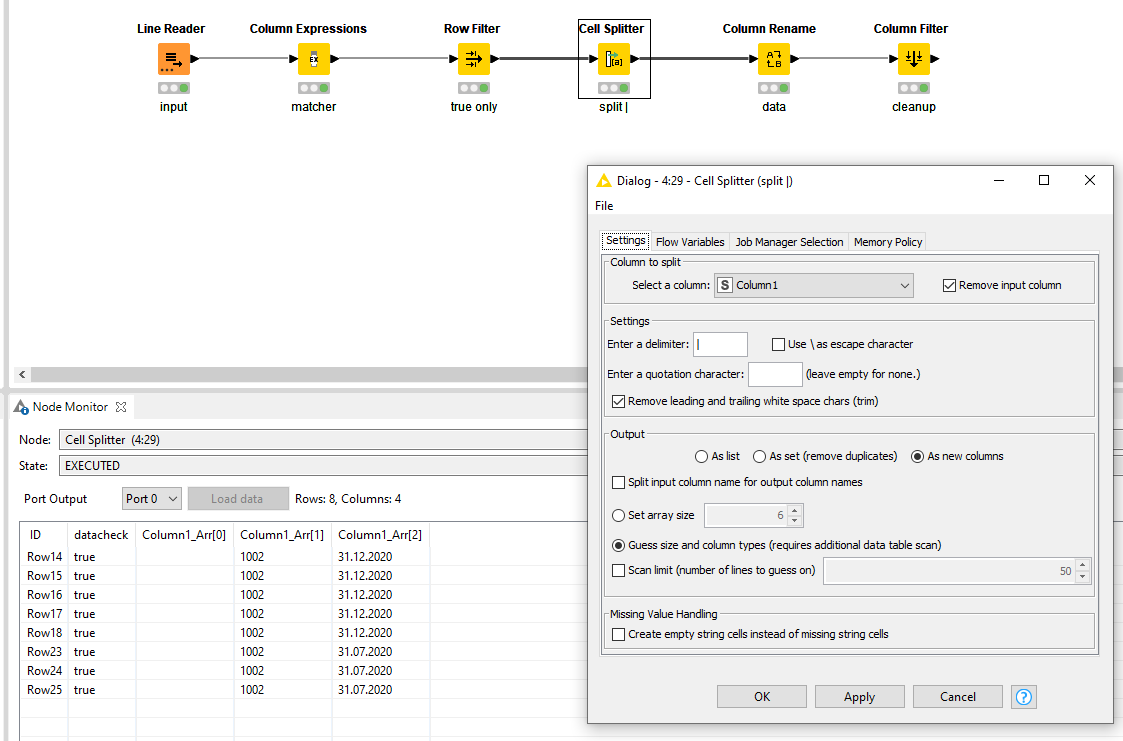
This is my workflow:.
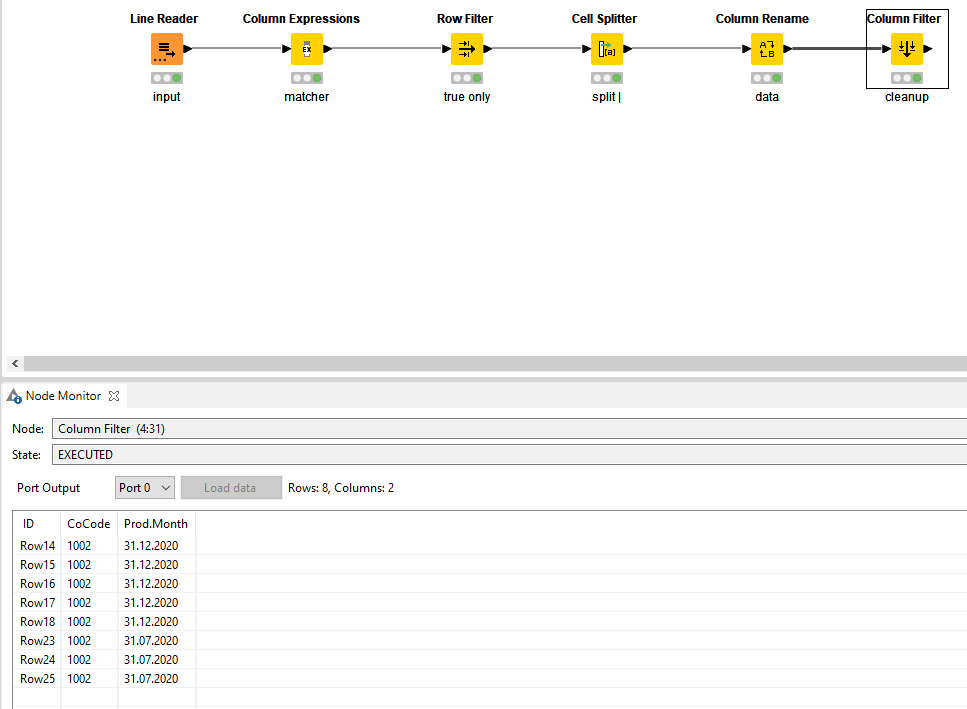
A Line Reader is a bit more suitable than Tika Parser in this case. The former process the file already row by row avoiding having to manipulate the single cell with all the content that the Tika Parser creates.
Main working principle here is to evaluate each row for the type of content that you need (in its raw format).
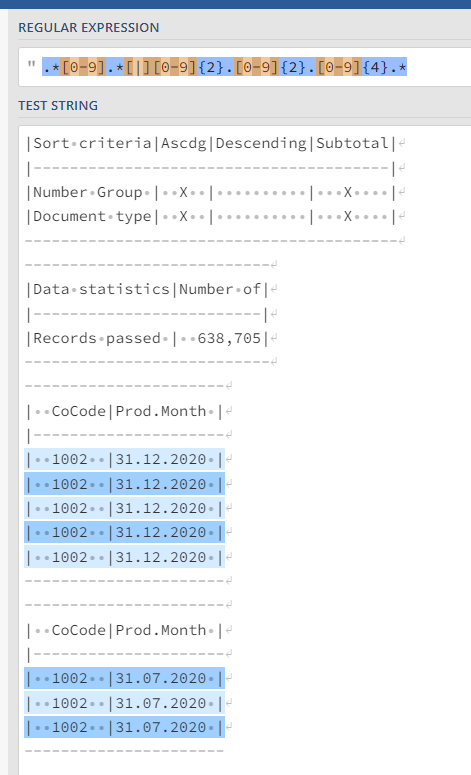
In this case that’s a number, pipe, and date in that particular order. You can check this with a RegexMatcher (available in the Column Expression node) by using .*[0-9].*[|][0-9]{2}.[0-9]{2}.[0-9]{4}.*
Note that you need to match the entire row in KNIME which is arranged by the leading and trailing wildcards. The disclaimer applies to this, if you have different data formats within the same file the Regex needs to be expanded to captures those cases as well.
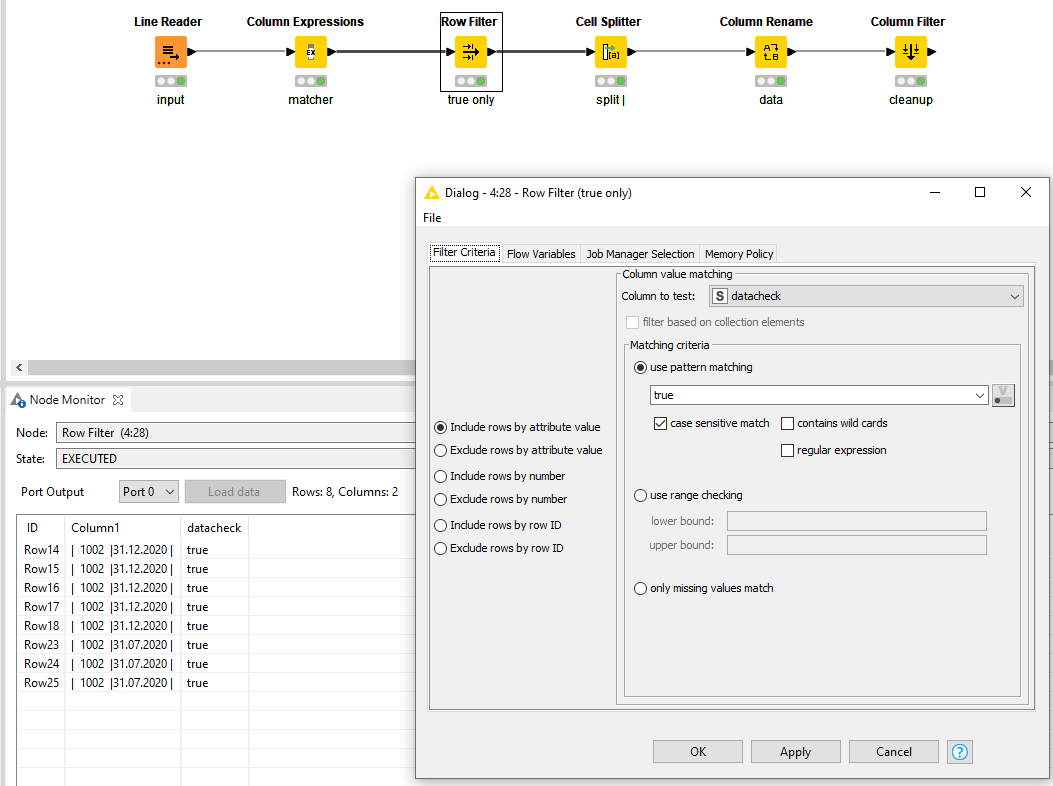
The RegexMatcher will generate a true/false output which you can subsequently filter on.
The data is 1.3 Million million aprox.
I am downloading from GJLI in this format.
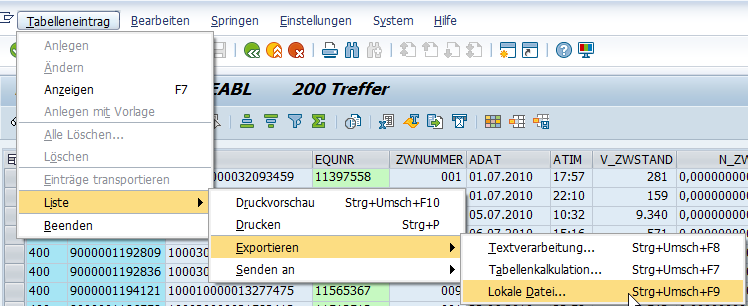
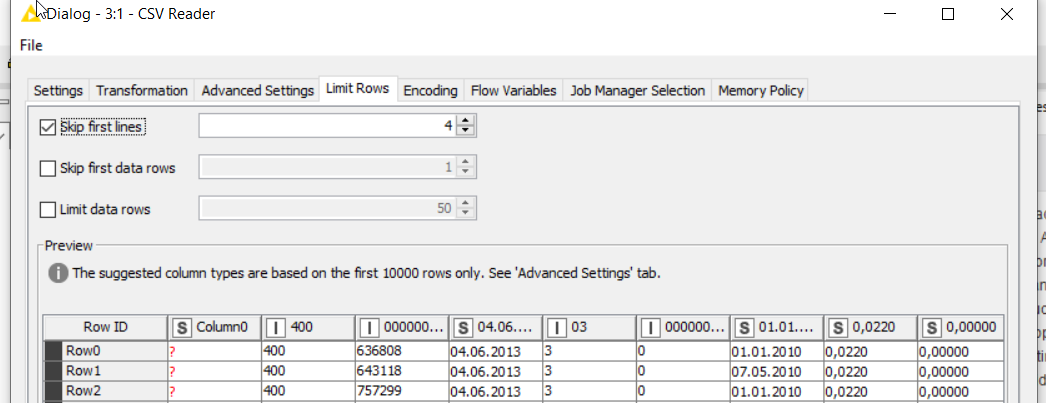
I tried to use the CSV Reader like you said but I think the lines that separate headers from table are causing some error. Is there any further configuration that I can add to make it work?
Thanks!
Hi @goodvirus,
I tried text with tabs but I was having a similar issue, I’ll try again tomorrow.
About the sample of the text, It is uploaded in the initial question, let me know if it’s corrupted or you are havind difficoulties opening it
I implemented a similar solution toArjenEX but I feel like there is an easier way.