I’m experimenting with
knime://EXAMPLES/04_Analytics/14_Deep_Learning/02_Keras/08_Sentiment_Analysis_with_Deep_Learning_KNIME_nodes
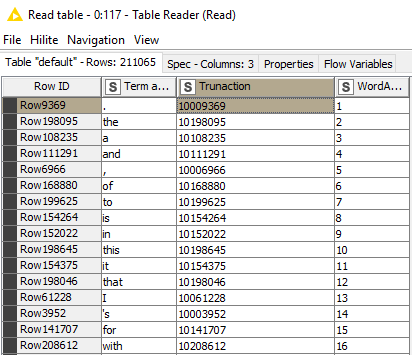
I’m trying to understand where the Truncation in the “Read Dictionary table” comes from as well as how the Terms were assembled? I have searched the forum and web with out success. If anyone could point me in the right direction it would be greatly appreciated.
Hi @JRL -
The idea in the preprocessing section of the workflow is that we want to create a numerical representation of each document that encodes the words into integers, and retains their order.

There are a couple of other things we need to do, though. First of all, the vocabulary space for these documents is over 200,000 words. We’d like this to be a little more manageable, so the Reduce Dictionary metanode shrinks the provided dictionary down to the most common 20,000 words, with an additional catch-all bin for the remaining words. (This reduced size is defined in a different meta node, and passed using flow variables.) Then each of the words is assigned an integer.
Second, in order to fit the documents in the Keras network, we want all the documents to have the same dimension. The same metanode that defines the maximum document size also sets the initial dimensions of the Keras Input Layer - we default to 80 words here. Any documents with more than 80 words are truncated at 80, and documents with fewer than 80 are padded out with zeros until they reach the appropriate size.
Does that help explain the preprocessing bettter?
3 Likes
Hi @ScottF
Thank you for the explanation! I was very confused by the “read document Dictionary” see attached image. I incorrectly though it was somehow setting the truncation leading to a lot of confusion. I’m new to KNIME with about 4 months experience coming from a background in SPSS. This has been a satisfying learning experience.
So if I am trying to build something similar, for semantic analysis, that I could simply drop data into as Excel file so using the CVS reader node. I would have to create a dictionary of words contained in the CVS file. I would then use this dictionary to filter out everything but the top 200,000 most utilized words as in the example. I would then truncate the word limit as necessary, I will have to look through my data to determine the appropriate length. Is that about right?
My goal is to be able to create models from different samples of data and test how much they very from one another when tested on a large data set.
As you’ve surmised, the dictionary provided in the workflow is a bit of a shortcut. I believe it was created by counting words in the IMDB corpus, and sorting according to frequency. If you want to use a different input corpus other than IMDB, you’d need to make your own corresponding dictionary.
Choices for the dictionary size and truncation length will definitely be informed by your knowledge of the data. You may have to use a bit or trial-and-error to identify the best parameters, but all in all I think you are on the right track.
I’m still struggling with the Truncation issue. it appears that the truncation column is tired to the model some how, and I’m not sure where or how it was generated in the table in the first place. I might be missing something obvious, if so can you please show me how the truncation was created in the table used for the dictionary?
Thank you,
Justin
Hi @JRL -
Sorry, all I know about how the dictionary was created is what I described in my previous post. The person who made this workflow is on an extended leave at the moment.
There’s a good chance that a separate workflow used to create the dictionary is available, it just hasn’t been publicly posted yet. Perhaps we can do that in the future to make things more clear.
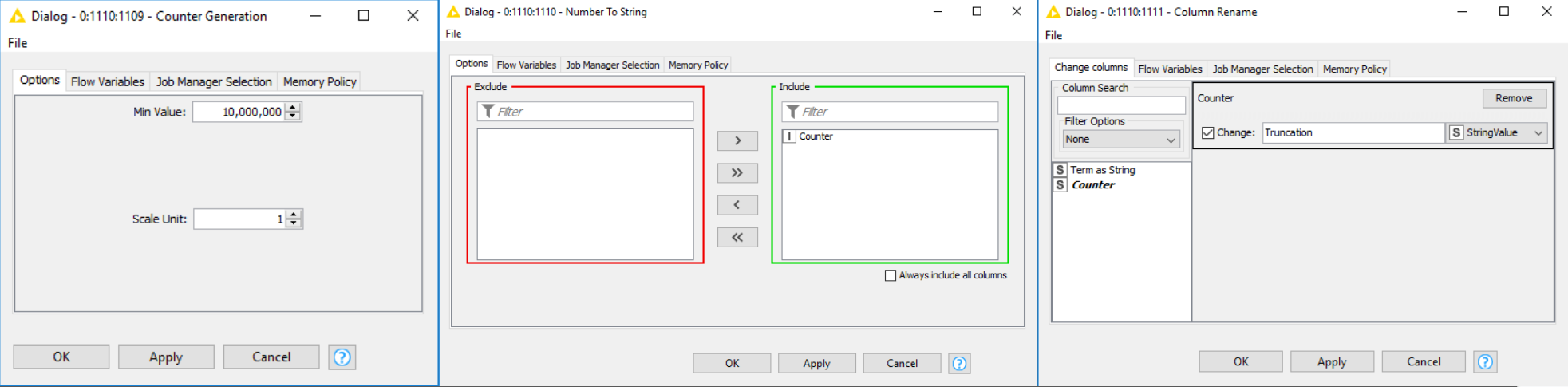
I figured out how truncation was created for the workflow and why. I wanted to share the solution for anyone else struggling with it. The Truncation was likely generated using a Count Generator set to 10,000,000 as the Min Value. This was done so it would be impossible for a dictionary to cause the count to roll over to a larger value; which is important considering the length of the digit representing the words are utilized to set the number of characters per document. i.e. If the value was to roll over the character limit would no longer function correctly and the number of neurons (the shape) would be wrong causing the Keras Network Learner to fail. I have attached an image showing how to create the “Truncation” for a custom library.
Thank you again for your help @ScottF
3 Likes
Fantastic! I’m glad you were able to work through it. Thanks for posting your method.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.