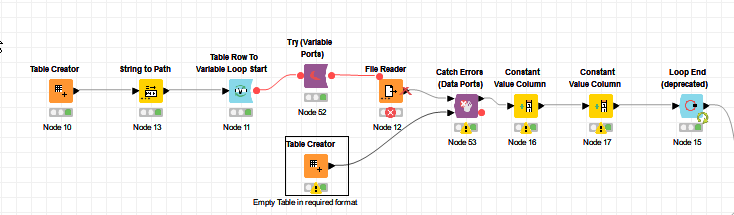
Hi @rolandnemeth , thank you for uploading your workflow. Obviously I cannot run the parts that connect to the database, and I have modified the list of files using some test files I have added to the workflow data area, but hopefully this gives an idea for a possible course of action.
I’m assuming that the data files you read are all of the same format so that they can be processed uniformly by the workflow.
So what I have done here is placed your File Reader inside a Try-Catch. The lower port of the Catch Errors node takes an input to be used when the File Reader attempts to open a file that doesn’t exist. In this case, my Table Creator returns a dummy table with no rows.
For demo purposes I have supplied a set of CSV files with headings Name, Age.
I modified the initial Table Creator to point to my sample files:
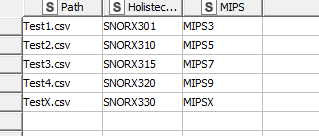
In the workflow’s data area, though, I have supplied only the following files:
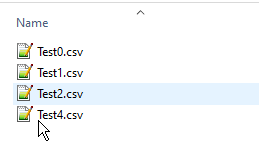
When it runs, it cannot find Test3.csv or TestX.csv, and in each of these cases it continues by processing the “empty table” supplied by the lower data port on the Catch Errors node.
I hope that gives a possible idea for how to make your flow work.
For the purposes of finding the demo files I included, I have also added a “convenience” component to the sample workflow.
Execute this to get quick access to the workflow data folder. This component is not necessary for the running of the workflow, but it just makes it easy to find the data folder
Xray_CT_v2 -takbb.knwf (121.4 KB)
(edit: Depending on what you need to do in the loop following the File Reader, you could also add an Empty Table switch downstream of the Catch Errors node, so that you only perform that part of the processing in the event of having a non-empty table from the Try-Catch block)