I have a requirement of reading the PDF file and updating the data as mentioned in the 1st screen shot . I have tried with PDF Parser, Tika Parser, but was not successful. I am able to read the data using R programming and converted to text file. I read the same text file using file reader and used some manipulation nodes to filter the required data. I need only 13 columns, but i have around 149 columns created in this process. some have blanks and some have question marks. Could some one help me in removing or deleting those unwanted columns. Below is the screenshot of the few columns having blanks/empty/??. Also what node should i use to run the R script or is there any node though which i can extract the data from pdf?
I am successful in removing missing values with Missing Value Column Filter node.
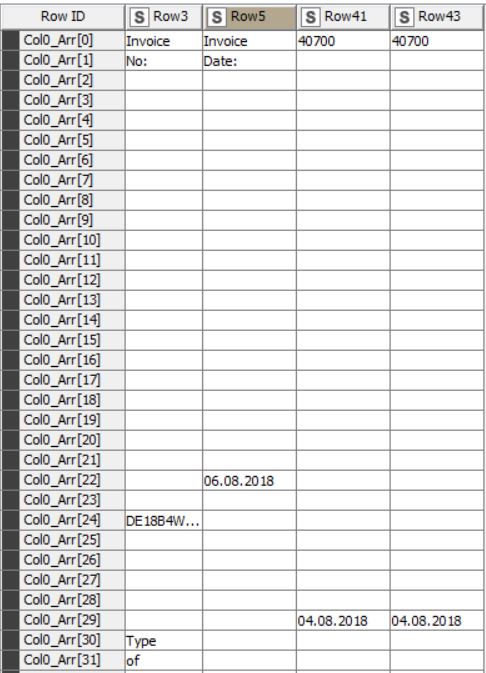
I have transposed the data also, but i couldn’t forward with the Row Filter, below are the screen shots of how the data looks like and the Row Filter node configuration.
is it correct, that I could describe your task by: delete all columns where Row 41 has either a missing value or is empty?
If yes, you can change the column to test on in the configuration window to Row 41. Next, we have to find out what is actually in your empty cell, it could be either really empty or also a space. Therefore, I would copy one of the cells and paste it into the pattern matching input field.
I did copy the cell and pasted into the pattern matching input field, i could find no change, i believe that it is really empty cell. Could you please suggest how to proceed.
Sorry, that this idea of mine didn’t work. Two other things that you can try:
If the empty columns are also constant columns AND all the columns you still need are not constant columns, you could use the constant value column filter node.
You can use the String Manipulation node after the Transpose node and replace the empty strings for example with 1. Therefore you can use the following function in the string manipulation node: regexReplace($test$,"^$" ,“1” ). Then you filter out all rows with value 1.
I hope one of both works for you. If not, please let me know and maybe share part of your workflow, so I can look into it.
As mentioned by @izaychik63, we can do this in multiple ways as per the convenience. If you are still unable to do, please share some samples or dummy data, so that you can get the helping hand from the community.
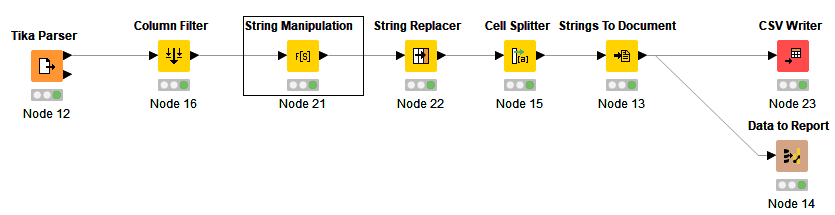
Yes I was able to read the data using Tika Parser. After that most of my time was spent manipulating the data. See attached workflow. Let me know if that helps you.