Hi All,
I’m wondering if it’s possible with Knime to read something like a complex log file, in which an ‘entry’ might span across multiple lines, and extract the entries as rows via a regex?
Many thanks,
Mirri
Hi All,
I’m wondering if it’s possible with Knime to read something like a complex log file, in which an ‘entry’ might span across multiple lines, and extract the entries as rows via a regex?
Many thanks,
Mirri
The idea being to grab meaningful sections out of a log file and then to perform further subprocessing via other nodes.
Mirri
It’s probably possible, but the specifics matter. Do you have any more details you can share?
You can use the “Load Text Files” node to download the log file (see enclosed small log file):

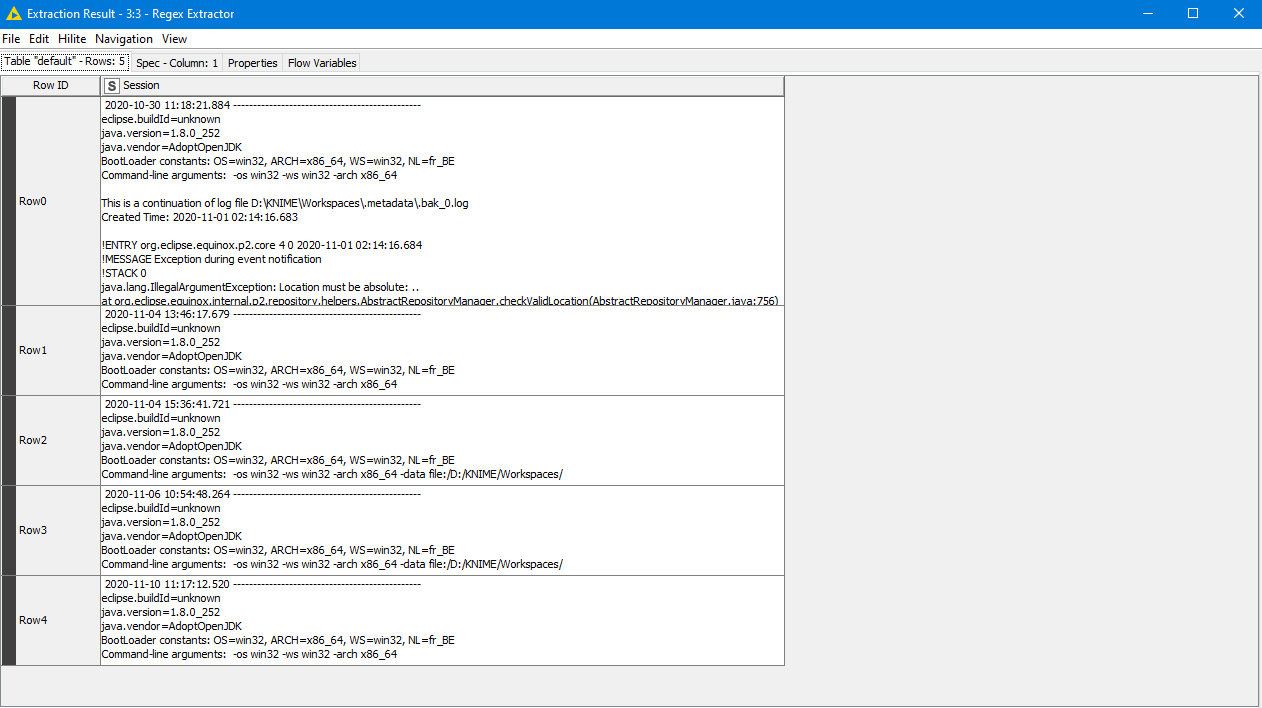
And use the “Regex Extractor” node (from Palladian extensions) to split the file for each “!SESSION” chunk.
Note: The configuration (open configuration window) take a large amount of memory and time to open on large log files (it’s an new issue with the palladian “Regex Extractor” node and the previsualisation showss new troubles).
And the result table:
new 13.txt (71,2 Ko)
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.