Hello,
When i execute a query in sql Developer it is taking less than 30s for the query to execute.
When i am trying to do the same in knime, it is taking 4-6 hours to extract the 2.5 M rows. I know there is a difference between executing and extract records.
But i was wondering is there any specific configuration/process i need to follow so that i can extract the records faster.
Thanks
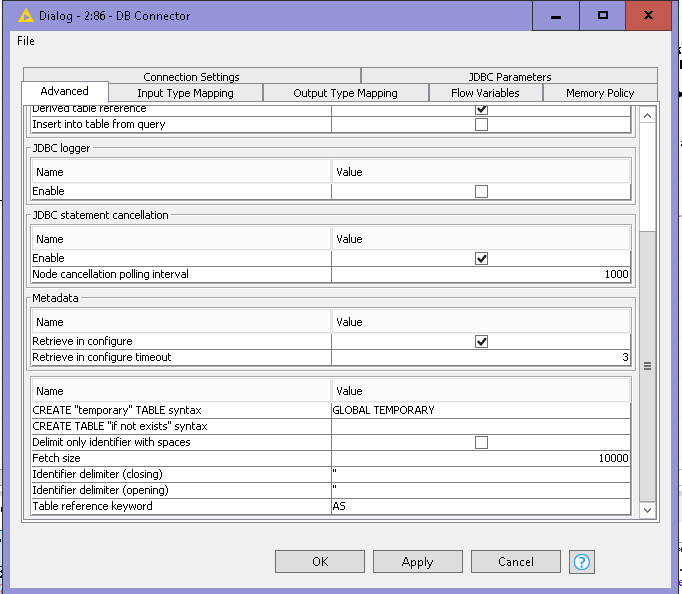
Hello @izaychik63
Thanks for the node. But I don’t see this node. Can you please put the link to that specific node.
I don,t see the fetch size option in database connector node(available in my knime 3.7) and does it work for Oracle DB or only mysql?
Thanks in advance.
Hi there @pruthvi1286,
print screen @izaychik63 posted is from new database nodes available in KNIME 4.0 version.
As for legacy database nodes you are using there is no fetch size option that can be configured inside node. Instead fetch size can be configured in knime.ini configuration file. Check this topic: Poor performance in Database Reader Node
Additionally network connection can be bottleneck so check that as well.
What database are you using? I suggest updating to newest KNIME version as there are new database integration nodes with improved features and performance 
Br,
Ivan
1 Like
dowloaded the knime 4.0 and saw this node. Thanks @izaychik63.
but the previous jdbc workers which worked are not working now and i am seeing this error: Selected JDBC driver does not support given JDBC url.
what is the protocol value for oracle database in databse url ? jdbc:oracle:?
can u please help me with this.
Thanks
Edit:
sorry , it worked. Thanks
2 Likes
Hello @izaychik63
The new DB connector node in combination with DB sql executor is really fast.
My purpose is to run a sql query and then load it to a csv and schedule it 4 time as day with knime server.
But i don’t see i can connect the output from these new nodes to a legacy node anything else and I see the output in the DB Table selector needs to be mentioned the number of cache rows on after the execution and not on run time.
Can you please let me know what nodes will suit my purpose and it would be great if you can provide a sample wf with new nodes where I can directly pull the output of the query to csv .
1 Like
You need to use DB Query Reader instead of DB sql executor. Also, legacy DB nodes could not be used together with new one.
Thanks @izaychik63
So i was wondering if there is any limit on maximum fetch size ? does it depend any on type of db ?
Thanks.
Hi,
if not wrong fetch size depends on jdbc driver which again depends on db type. So check how this works for your db type. In my experience you should play around with this number and measure performance for different values.
Additionally I recommend this blog post for workflow optimization: https://www.knime.com/blog/optimizing-knime-workflows-for-performance
Br,
Ivan
Hi,
let me clarify this comment. With KNIME 4.0 we introduced a new framework and renamed all existing database nodes to end with legacy. In general you can use both frameworks together. Only if you are using Microsoft SQL Server with native authentication (NTLM) you can not use the legacy and the new Microsoft SQL Server Connector node in parallel. We are working on a solution for this limitation which is caused by the requirement to register a native library. If you have further questions about this please don’t hesitate to contact me.
Bye
Tobias
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.