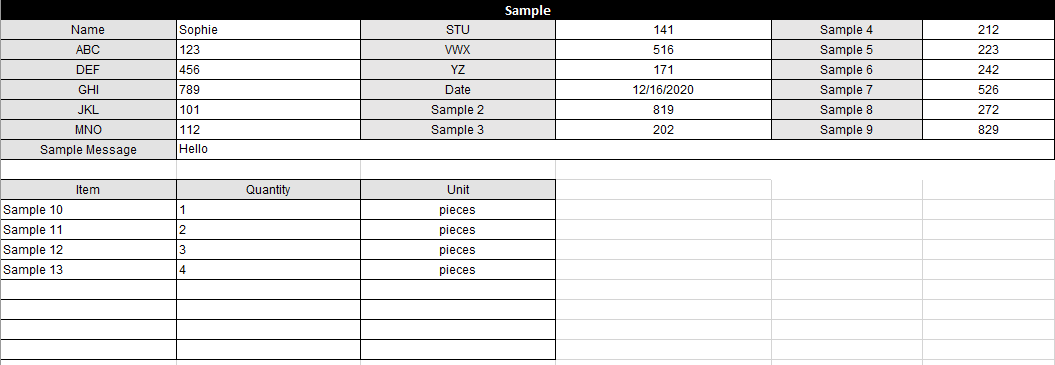
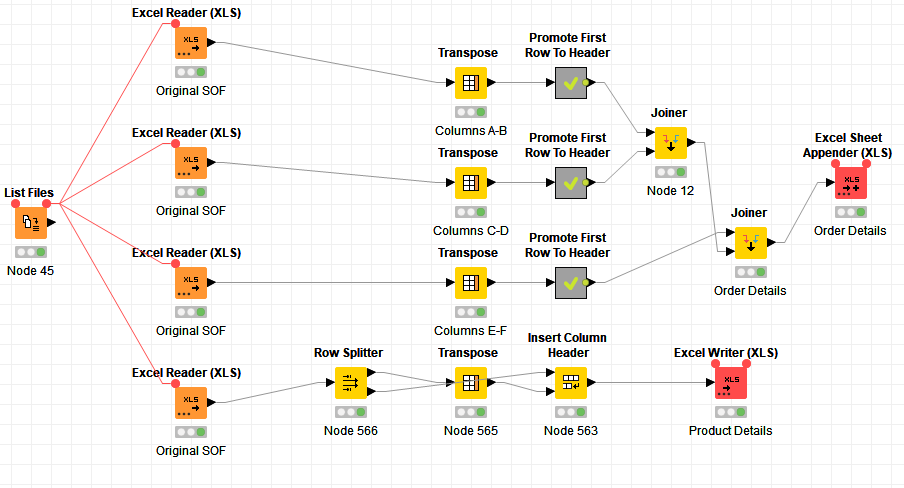
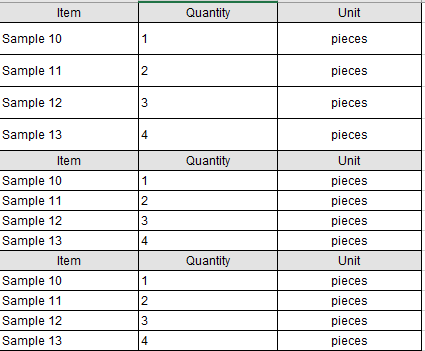
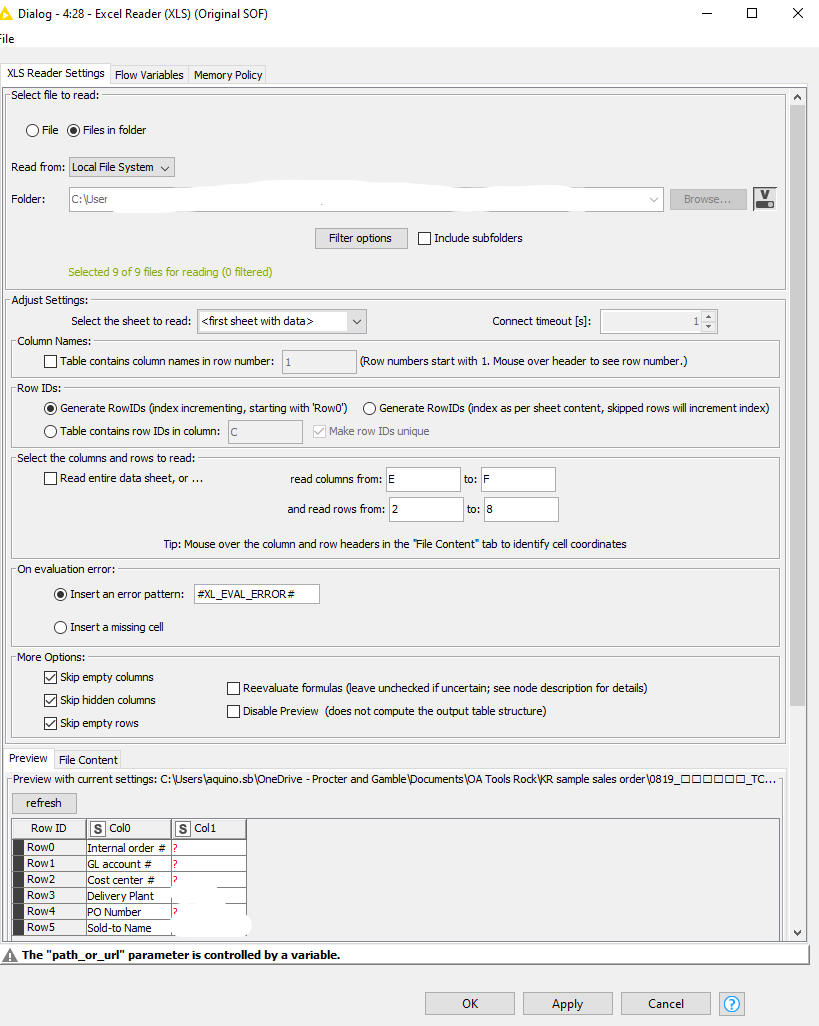
I got good news for you, with the new excel reader this is super easy, you can tell it to read all files in a folder and apply the same filtering to all of them:
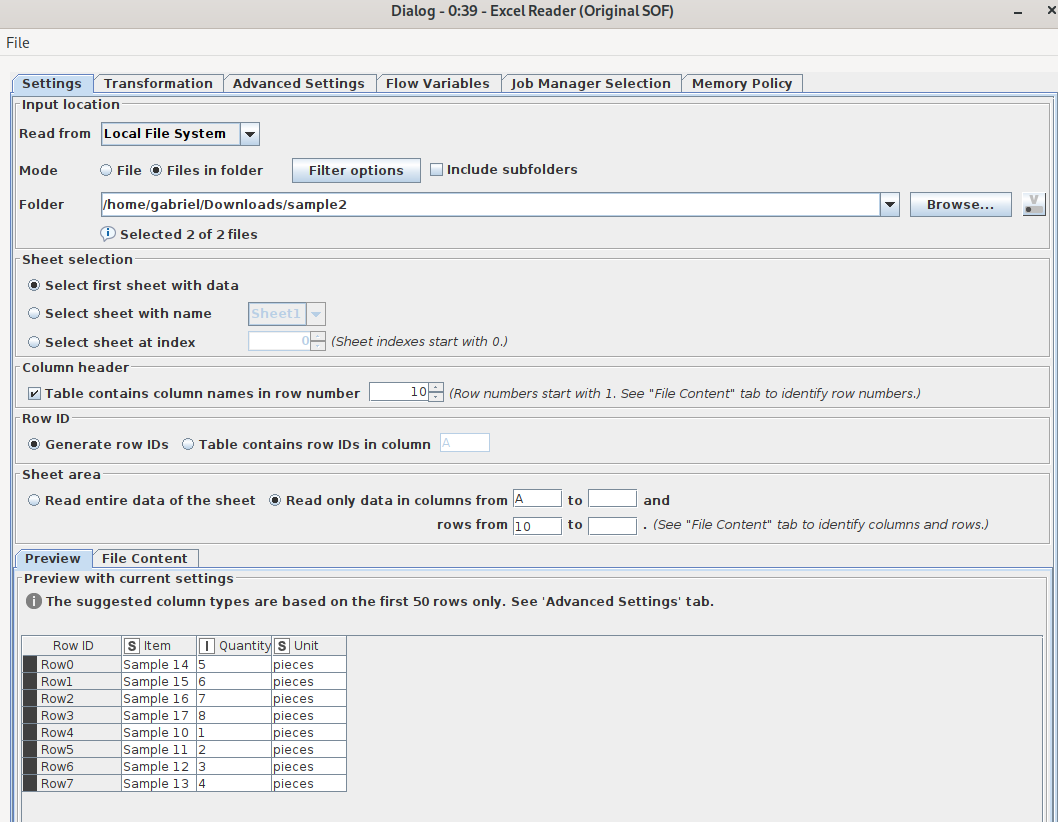
I am currently running on Knime 4.1.1 since it is the version required by our organization. This is how my excel reader node looks like. Any tips on how to still make it work?
Hi @sophieee
this error occurs while in section Row IDs 'Table contains row IDs in column " is enabled. If you dont have unique ID information “Generate row IDs” must be enabled. Otherwise the import fails at the first frequently content in your data.
If your data are an offset (not starting in Row 1) you should also consider it in the section “select the column and rows to read”.
The preview shows you if you have the correct settings. If you have further trouble i recommend to share your worfklow or a sample file with us.