OK, I built something since the mentioned examples are not straightforward (if you want to play around with them further in a subfolder of the workflow there is a /script/ folder containing some tests with R and Python scrips mentioned in the links but the results are insufficient if you have more complex INSERTS statements).
As an example I use the Mondial MySQL dump mentioned here:
https://blog.twineworks.com/converting-a-mysql-dump-to-csv-files-b5e92d7cc5dd
(which is also included in the workflow subfolder /data/)
A fair warning: it ain’t pretty and may not be for the faint-hearted, and depending on your dump some modifications might be necessary and if your data gets very big you might have a problem since KNIME Flow variables might not be able to handle it. For this example, it does work, however.
So what this workflow does is it identifies the 4 components of the SQL statements needed to (re-)build a database. The numbers will be represented in the no_marker/no_marker_orig columns.
- DROP TABLE IF EXISTS - initiates a clean start and makes sure the table has been dropped
- CREATE TABLE statement initiating the (empty) structure
- a row about primary keys and more informations specific to MySQL which H2 and other simple DBs might not understand. This No 3 will be replaced by a dummy line closing the CREATE statement (the construction with the dummy variable and ALTER table is not pretty at all - might just have removed the comma and added a bracket - but hey over-engineering is my thing)
- The INSERT statement filling the structure with the data. This is a tricky part since the data can contain quotes, pairs of information and other quirks. And the statement can be quite long. We would have to do with restrictions of memory and limitations of flow variables.
This is an overview of what you get. Fill in the MySQL dump and (re-)create the databases in H2.
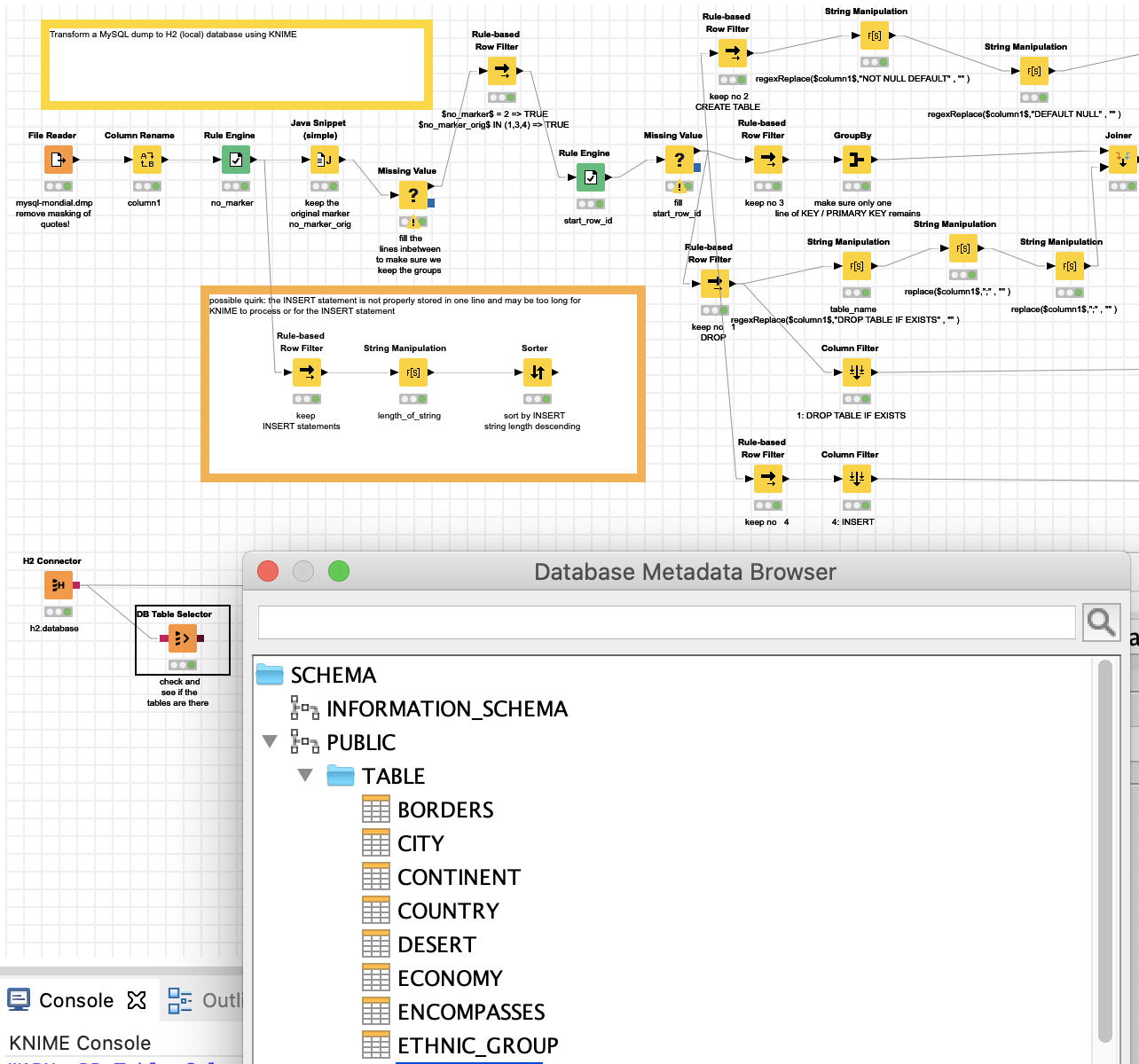
This is what it looks like in a detail with the 3 steps:
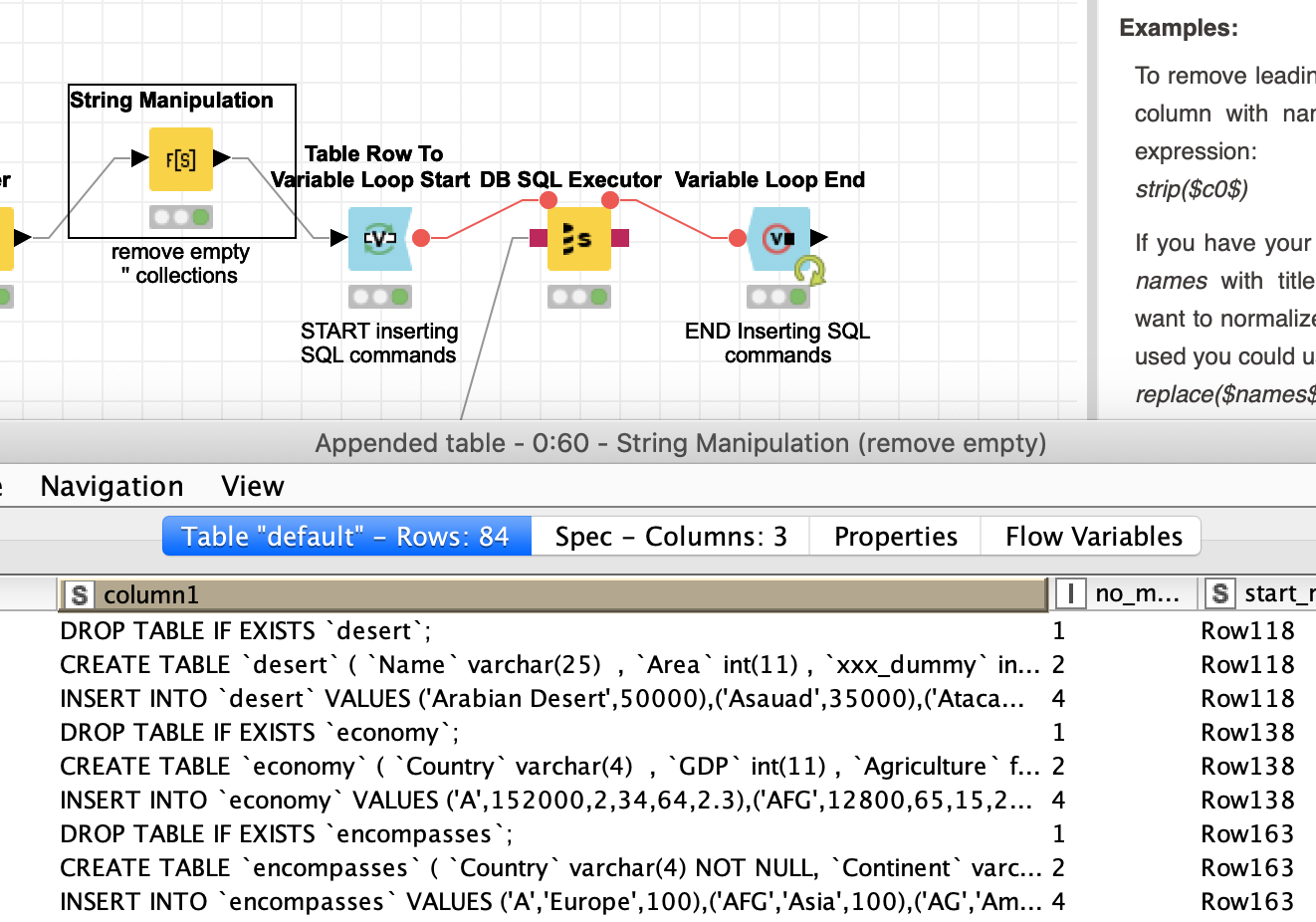
Here are the three (remaining) steps in their glory:
DROP TABLE IF EXISTS `sea`;
CREATE TABLE `sea` ( `Name` varchar(25) , `Depth` int(11) ,
`xxx_dummy` int(1) );
ALTER TABLE `sea` DROP COLUMN `xxx_dummy`;
INSERT INTO `sea` VALUES ('Arabian Sea',5203),('Arctic Ocean',5220),('Atlantic Ocean',9219),('Baltic Sea',459),('Black Sea',2211),('Caribbean Sea',7240),('East China Sea',2370),('Gulf of Aden',5143),('Gulf of Mexico',4375),('Indian Ocean',6400),('Irish Sea',272),('Mediterranean Sea',5121),('North Sea',200),('Norwegian Sea',3860),('Pacific Ocean',11034),('Persian Gulf',102),('Red Sea',2635),('Sea of Azov',100),('Sea of Japan',4036),('South China Sea',5420),('Sunda Sea',7440),('Yellow Sea',200);
This might be used as an inspiration how such a problem might be handled since various dumps might have varying structures.