Hello all,
I am still new to the KNIME world and am trying to achieve the following. I have a large XML file with any number of XML tags. I would like to read this. So far I have read in the XML file with the XML reader and walked over it with XPath. Unfortunately, this always returns the value of the XML tag and not the tag itself. Do you have any idea what I am doing wrong here or how I can achieve this?
Hi @jgawin,
The following XPath will extract all values:
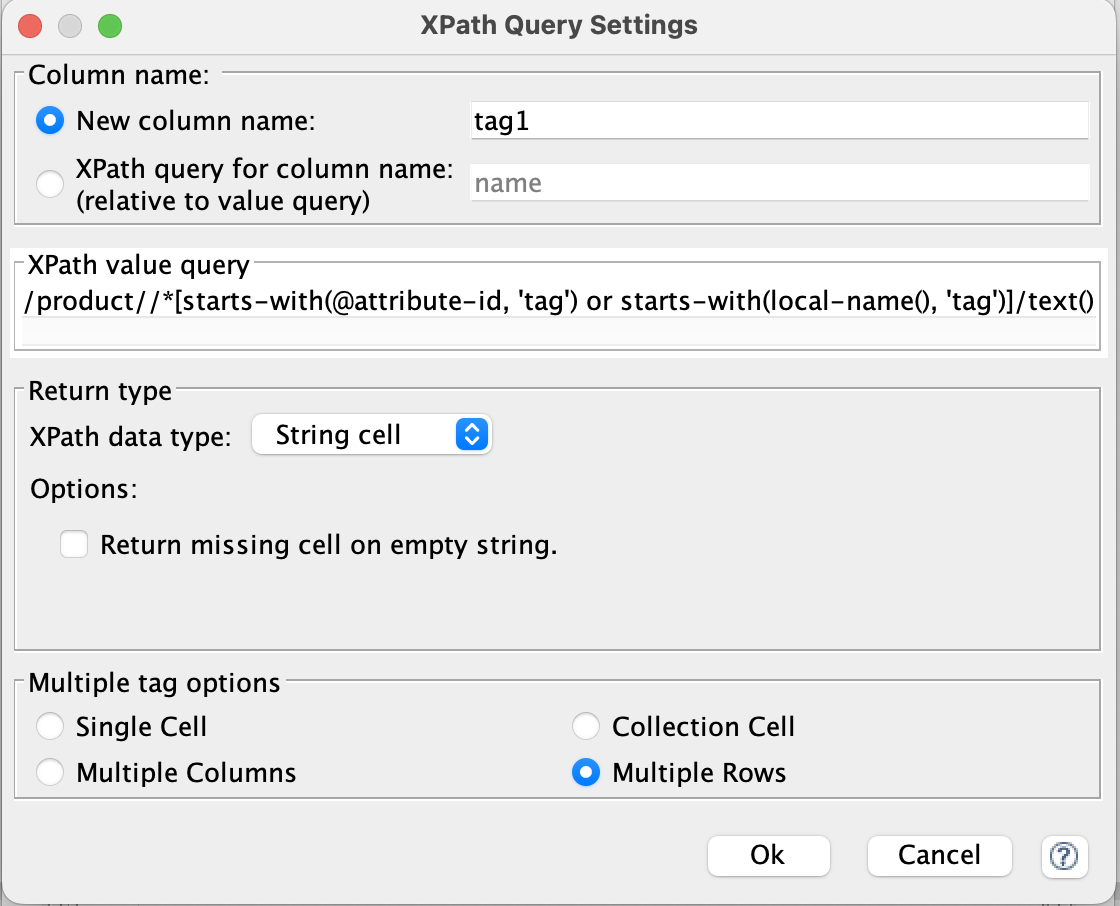
/product//*[starts-with(@attribute-id, 'tag') or starts-with(local-name(), 'tag')]/text()
The return type must be String Cell and you need to check “Multiple Rows” at the bottom of the XPath’s configuration, as seen in the attached screenshot.
Thank you for the quick answer. Does this also work if I don’t know the tag names? The XML file is very large and I just want to read out all the tags that could be contained there.
Hi,
Well, you need to know something about them. If you want to get all the leaf elements in your structure, that is all elements without children, you can use the following XPath query:
Unfortunately, the solution doesn’t quite work for me yet. But maybe I’m still doing something wrong. I’ll try to define it more clearly again.
I have a very large XML file with any number of nodes, as in the example above. Unfortunately, I don’t know the names of the nodes. I only know the top node product. I would like to read out everything below it. If I look again at the first example of mine and I run XPath over it, I get these results:
value1
value2
value3
value4
value5
but I need the result:
tag1
tag2
tag3
tag4
tag5
Is there a way to retrieve this via some kind of wildcard? I hope that was more understandable
Hi,
You need to figure out some rules to apply. The problem is that you have some nodes and some attributes that you want to extract. How do you know that is not a tag element? Do they all start with “tag”? Then you can just enter 2 queries in the XPath node:
The first one finds all attributes named “attribute-id” with a value that starts with “tag” and extracts their value, and the second one finds all nodes where the name starts with “tag” and extracts their node name. Once you got those two lists, you can join them back together in KNIME, e.g. using Ungroup, Column Splitter, Column Rename, Concatenate.
Kind regards,
Alexander