Hi there!
I’m trying to figure out how to read data from a not delimited file. I can do it from SAS, R or even Oracle. But cannot see any Node to do this task.
Just to example: There are 2 files: 1) with the data itself and 2) with the metadata about how the data is arranged inside the data file.
Something like:
from column 1 to 4 seq;
from 5 to 8 year;
from 9 to 10 month
and so on!
Hi @EduardoRio , I’m presuming the file is still divided into “records”, delimited by a carriage return and/or line feed, but from what you are describing is fixed format (the type of thing that an old cobol system might produce perhaps?)
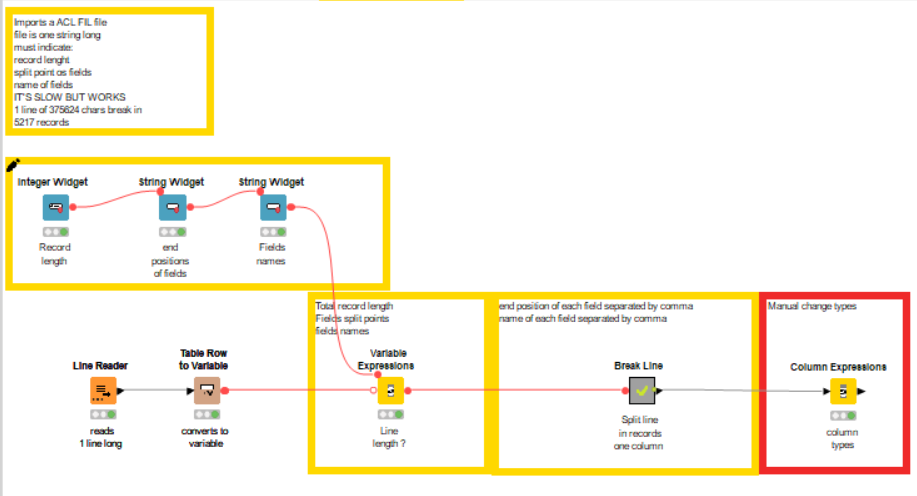
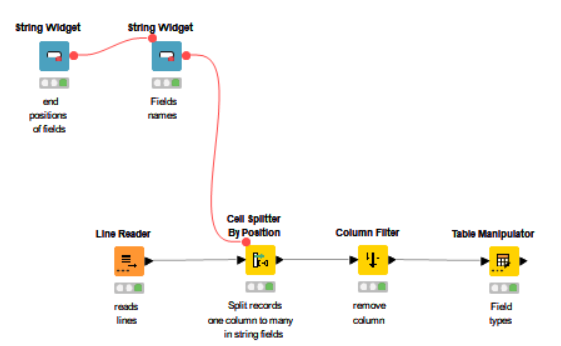
If that’s the case there is a Line Reader node
You could combine this with a Cell Splitter by Position.
If you have varying record types you would probably need to split these out based on a record type identifier first.i
Hello Takbb
Great, I think you’ve got the point precisely. The data file come from a mainframe, we’re used to call those type of datasets as “positional”. A bit hard to use, but very economic and fast on the other hand.
Yes, each line has a carriage return, so Line Node should be able to handle with it
And Cell Spliter should do the other task.
And, yes I have a file with record for types and columns names . In fact, created for data import for SAS. But I think that with some workaround I could use it.
But I’m sorry I can’t get it " probably need to split these out based on a record type identifier first.i"
But Thanks a lot I’ll have a lot to do from know!!
Regards!
Hi,
Another question:
Since the data file has no header line with the name of the columns and there’s another file with the names and types.
So, I would ask: is there some Node to this kind of job to use these information and put it on the data file structure?
Example: Using SAS The import feature allow to point to de data file, specify the type of data and use either a file with data structure information as types, names and sizes/positions on the process. They mix the information in the import procedure to create a structured file with the data.
You could take a look at the variable configurations of the line reader. Depending on what it support you could create variables from the config and then use them in the line reader for configuration.
br
Sorry @EduardoRio , it looks like I didn’t quite finish the line! What I meant to say was that if you have multiple record types, then the Cell Splitter would need to be configured differently for each. So I’d therefore assume you’d need to split your flow (e.g. using a series of row splitters) so that there would be different branches for each record type.
You’d then have a Cell Splitter on each branch to create the required columns for the records contained within that branch. As per @Daniel_Weikert 's comment, you could probably configure each Cell Splitter using variable values derived from whatever configuration file you have.
If you can upload some sample (dummy) examples of the “data file” and “structure file”, we could possibly give some additional hints on how you might be able to define the config for the Cell Splitter.
I do agree!
BTW, Thank you guys for the support.
I’ll put an example of the data and the "structure created for SAS import procedure.
And let me explain why I’m doing it. I’m used to create information on Oracle (BI tools) and SAS, some little in Tableau as well.
About 1 year ago I’ve Discovered Knime and became very well impressed. So, I’m learning how it works. I can understand(I think) the workflow and the Nodes structure. Already create a complete flow reading Oracle database, several tables, joins, etc and, as output created some Excel tables and graphics.
The data I’m trying to manipulate came from the Our census bureau, we call it as PNAD that stands for “National Program for domiciliary Sample” This kind of research is done every year in opposition of the census done each 10 years. It is open data and very actual with a lot of good information about the families work, health, wealth, etc.
But you have 2 ways of getting that data: 1) gross data (my case) or, 2)Final data - spreadsheets, already filtered, aggregated. But the second doesn’t allow you to do many of the simulations we probably shall do to stress the data and come up with more interesting information.
So, that it !! The bad is the primary effort to convert the text file on something more friendly is huge.The good is one time done you’ll use it for each new set of data.!!
Bellow the structure example. Please, note this one is used by SAS. With some work the it can be changed to allow Oracle importation.
Where:
“@0000 #” - is the initial position of the field;
" V0101" - is the column name on the file/database;
“$#” - is the type(string) and length - “#” - Type(number) and length;
“/Reference year/” - column name description data.txt (1.5 KB) srtucture.txt (1.9 KB)
Hello,
Half of the problem is already solved. The reading of the data.
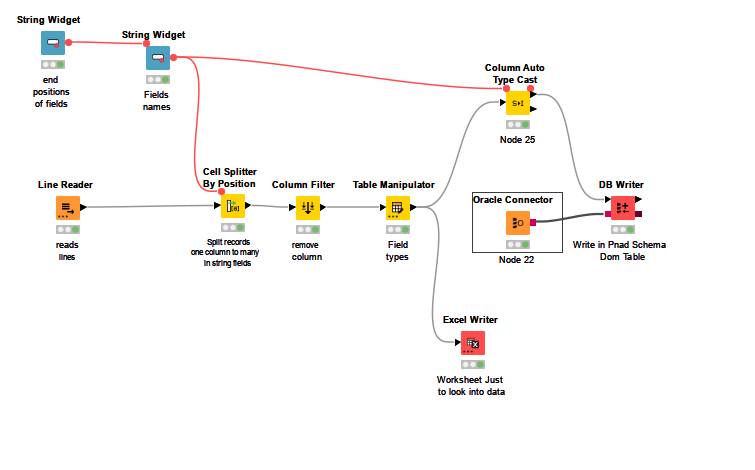
Now I’m going to wonder how to put the data into a Oracle schema, with the same structure and columns names.
I know about the Oracle’ connector, DB Table Creator.
So, Just want to ask you guys: if it’s possible to use the same “String Widget” to “pass” the names and types (maybe size either) to the Table Creator??
That’s it
Thanks again for the support!
Eduardo
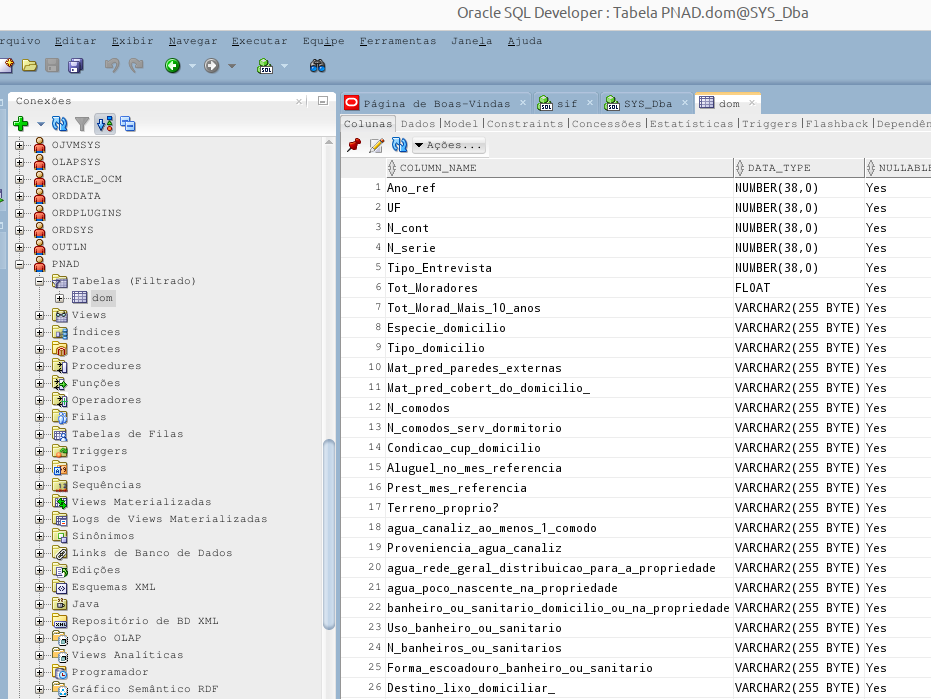
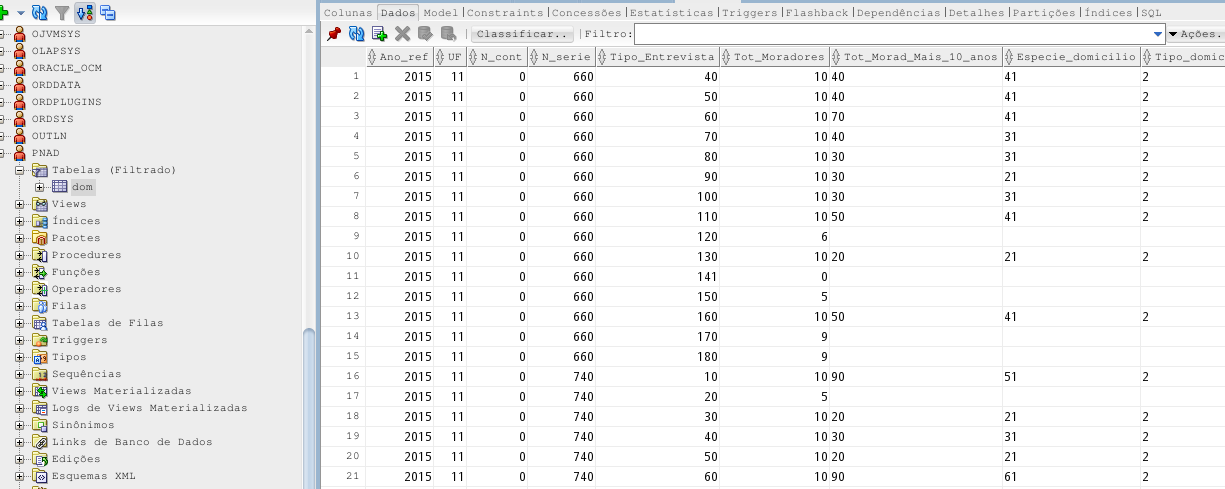
Here to say that I’ve done it. Successfully create the table and import the data.
Btw, the table has been created with whole columns as string with 255 positions. I’m now trying to figure out how to set the types and lengths before the table creation.