Looks like @duristef has already provided an interesting possible solution. You could also take a look at the Fixed Width File Reader node as another approach.
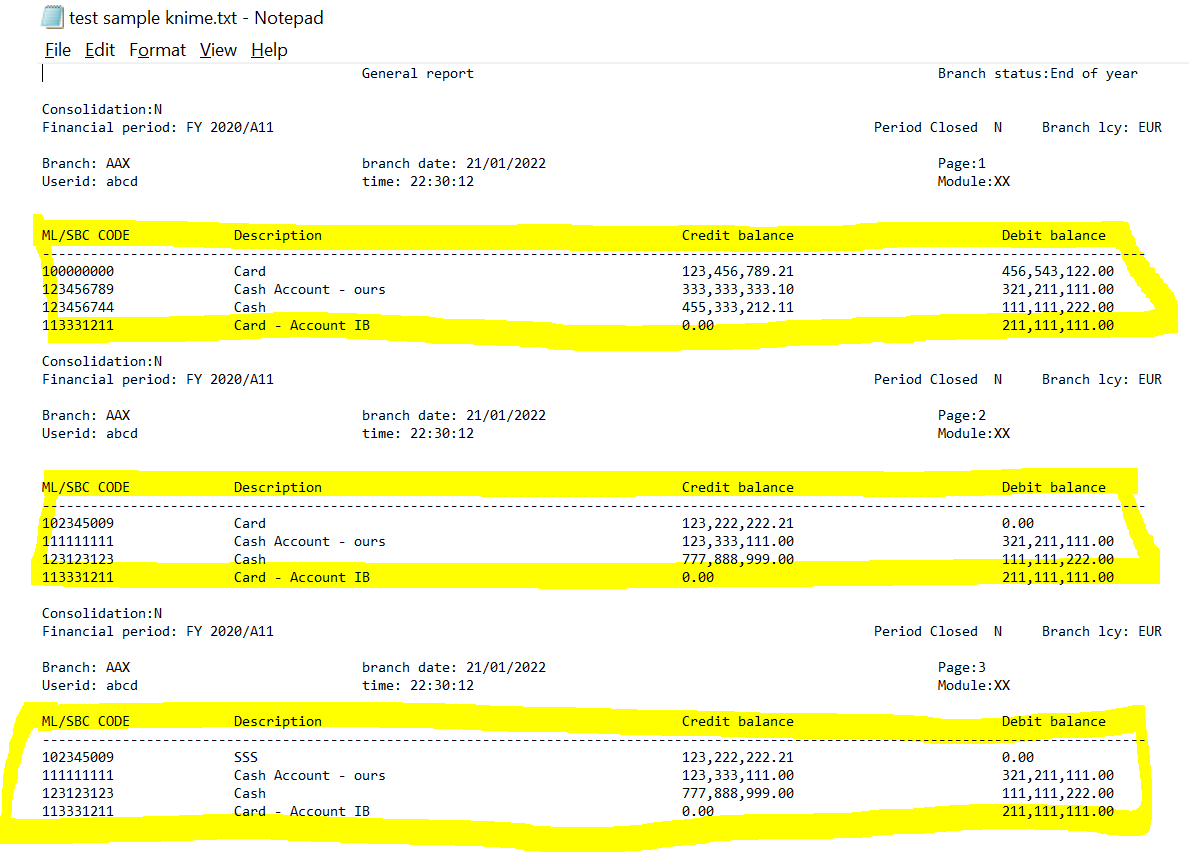
“^\d+.+$” matches rows beginning with at least one digit (^\d+), followed by at least one character (.+$). This is used to filter out all the rows that do not contain data.
The main problem I see in the file is that columns are right/left filled with both tabs and spaces, which makes it difficult to split them by position. That’s why I didn’t use the Fixed Width File Reader node myself
One of the problems here, as @duristef has already pointed out is the mix of tabs and spaces as delimiters. Clearly the report was designed to be read with fixed width spacing and if viewed in Notepad, all of the columns that you are interested in line up. Converting the white space into a delimiter character is therefore going to be problematic under some circumstances.
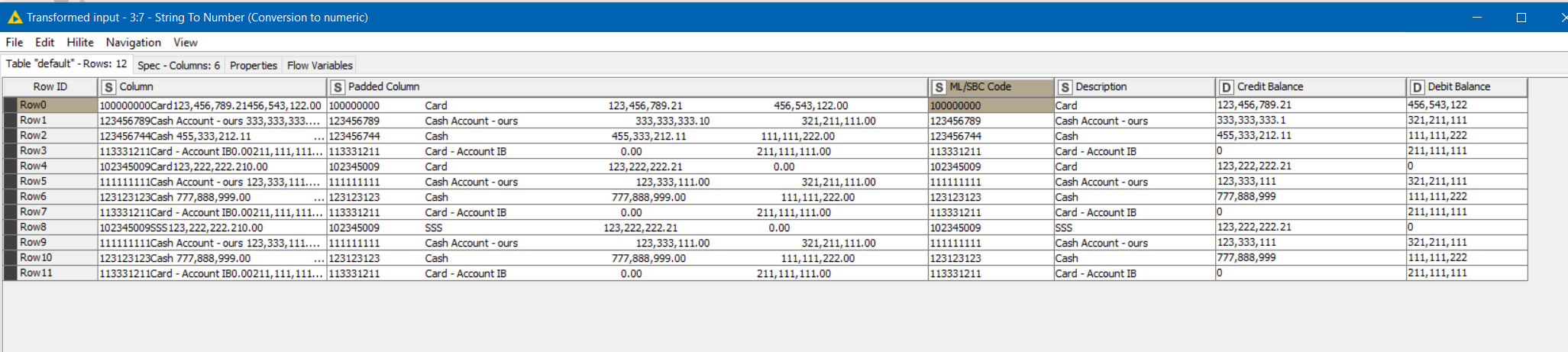
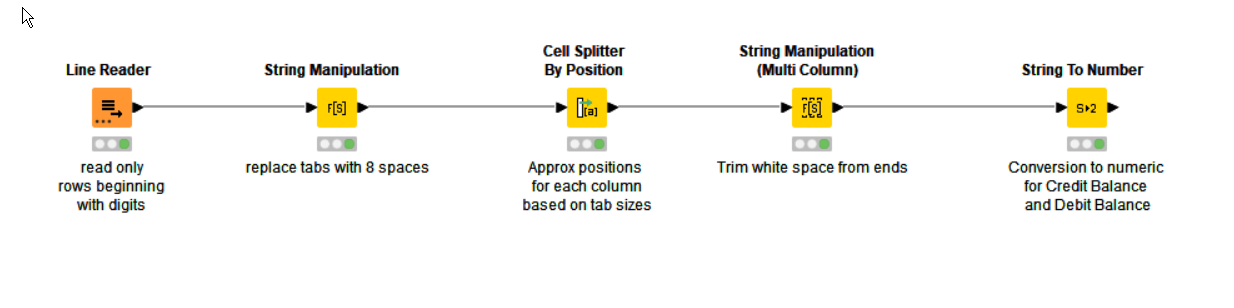
So, instead of trying to convert the white space into column “delimiters”, you might therefore get a better result if you convert tabs into a specific number of spaces (as an approximation to what Notepad does), and then attempt to split the columns positionally. I found that for the sample data, converting each tab into 8 spaces provides sufficient “wiggle room” that a positional cell split can then occur. After then trimming white space and converting to numerics, you get a reasonable result. Maybe this will work with your “real” data.
I borrowed from @duristef’s Line Reader but removed the regex and opted for a straight replacement of tabs with the “Cell Splitter By Position” replacing the “Cell Splitter”