Hello
I am new here and have not found a solution to my problem, but it is probably obvious for experienced users.
My students have created several surveys and now I would like to get the received mail addresses from the received tables (xlsx). Unfortunately, these surveys were all individually designed and the columns are named differently or not at all. So I can only recognize by the format of the content (xyz@mail.com) whether there are mail addresses in a column (using regex) or not.
How can I use a node to recognize the desired column based on the existing content and then only use this column in the next node?
Hi @STLR,
I have uploaded a workflow to the hub
I’m assuming that there is supposed to be only one column containing emails addresses. The workflow above is simplistic in that it simply looks for the wildcard pattern "*@*" within any string columns. This could be adjusted to a much more complex regex pattern if you wished.
I’ve a also assumed that it is possible for more than one column to (by chance) also contain strings with @ signs in them.
Take this demo data:

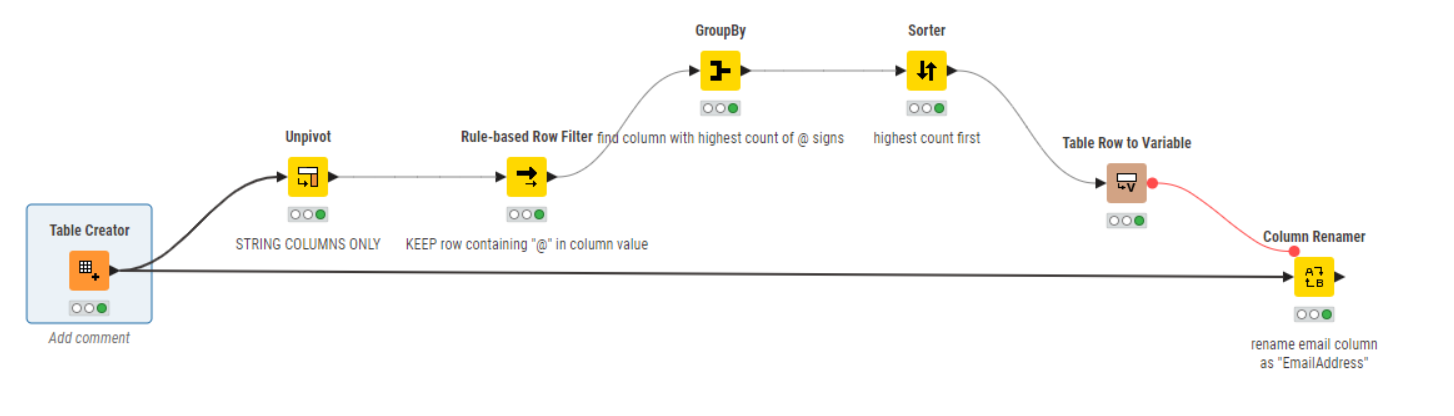
What it does is first unpivot all of the String columns, so we get this table:

A rule based row filter then keeps only rows where the ColumnValue contains an @ sign.

GroupBy is used to determine which of the “ColumnNames” is the best candidate, by counting the number of rows per Column Name. Sorting by the count in descending order, and then taking the top ColumnName as a flow variable, this can then be used to rename the candidate column to “EmailAddress” on the original table.

You could of course then use a Column Filter, or other column selection method to keep only the EmailAddress column for processing in the next node.
btw. Welcome to the KNIME Community Forum! ![]()
2 Likes
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.