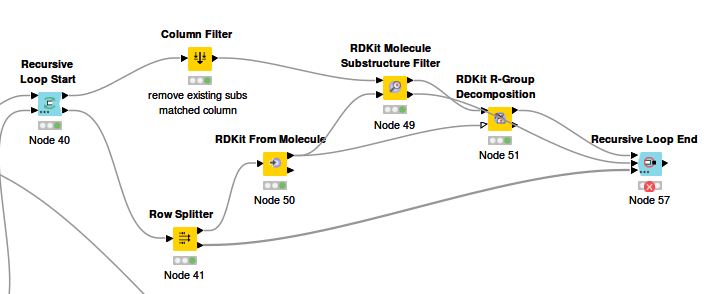
In this workflow I would like to do R-group decomposition based on a set of scaffolds used as MCS, which sounds like a very easy task. The problem arises from the different ring size of the utilized scaffolds (4-,5- or 6-membered rings for example). The node R-group decomposition will generate a number of columns corresponding to the number of attachment points where the substituents could be. This number will be different for the different ring sizes, therefore also the number of columns at the end of the loop will be different. The Recursive Loop End doesn’t allow for varying table specifications unlike the Loop End.
For now I have solved by filtering all the additional columns but I would like to know why does this happen. What could the bad outcome be? It would be nice if the collector port would concatenate the tables adding a missing value where no value is encountered for some iterations. Could someone please explain me this?
Cheers,
Hi @ChineS
As you already figured out, loop end nodes only can concatenate identical rows in terms of column names and format types.
Meanwhile some more flexible functionalities are developed and released for these family nodes and alternatively; you can preprocess your data aiming to identify and shape your output report.
If you want to keep all the additional columns in your output table. An inner join of the final processed row with the reporting (output) format, just before send the row to the loop end, can handle the null/empty values.
I can’t anwer why this is not implemented yet but I am sure it will be available in the future as well. Till then I could also think of Table Validator or extract table specs as helpful nodes to adress this issue.
br
Hi @gonhaddock, thanks for the reply I am not sure I understood this solution, could you please provide more details? @Daniel_Weikert , sadly I have tried this strategy but it could not work because the table specs will always concern the current iteration. As far as I know there is no way of addressing the previous iterations or do you have suggestions about this? Could you provide more details in case?
I really hope that the Recursive Loop End node with variable table specs will be implemented soon as it has already been done with the Loop End.
Cheers,
Hello @ChineS
Just a small correction on my previous post: the join is always an outer join to match the template. At some point before the joiner, you will have to unpivot the current row in loop.
I have few examples already posted in the forum, let’s focus in 2 of them:
Tis WF is a good example because the size of the report isn’t fix. The starting date rolls with the WF execution and the length (number of columns) can be any depending on the displayed projects (items), as in your use case.
Weekly data has to be aggregated on an irregular grouped bins as well, defined in 'Reporting Format ’ meta-node $Period$, increasing complexity.
The ‘Processed INPUT Data’ meta-node preprocess the data, and argues with ‘Basic INPUT Data’ about reporting logics, then populating: the length ($Life left (weeks)$), first efective financial day on Monday basis, reporting start (next Monday from workflow execution) ; shaping the reporting format.
You will find a an outer join within the loop to extend the columns all over the empty values; the result can be inspected in ‘OUTPUT 01’ end node
This WF has a format support section for the loop (Sort Reporting Columns Ordered by Chronology). This is a good example on how to handle missing values. As you see it can handle null values in any column position.
The shaded joiner in “Missing Handling” can give you an insight; The ‘Sales Counts Report’ shows the results with the blanks()
In this case preprocessing is not needed, as the ‘Custom Report’ is predefined.
Out of the boxI could only think of storing the table specs as variables in an additional table and save them this way or sth like "only overwrite if number is < X otherwise keep prior.
br