@Brotfahrer I had another look at the data and I would like to point you to another systematic approach. Using the underlying structure of the files to mark and split the relevant data.
the big blocks seem to be defined by parts marked ECU. With the help of row numbers, you can identify and mark these blocks as “Level1” value pair. You would have to deal with the header values separately and maybe add the file name as constant column.
The new LevelB is formed by Blocks that can be identified by Keywords Like “Software Block*”
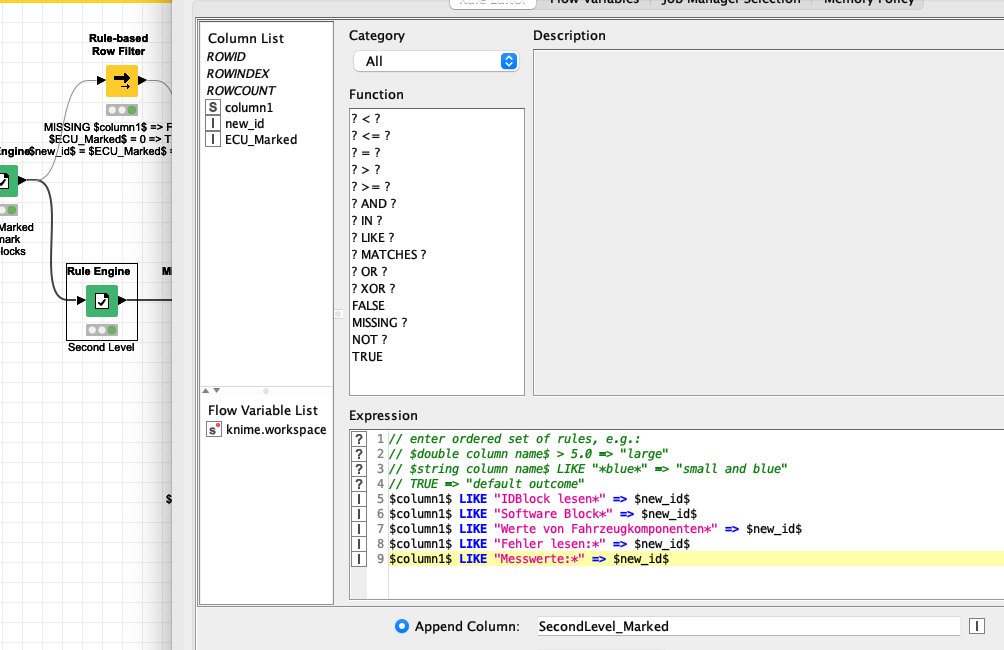
The remaining lines would be value pairs with
Key : value
The result is some sort of a flexible hierarchy of 3 elements which you would now be able to further manipulate (extract numbers and dates based on keywords or something).
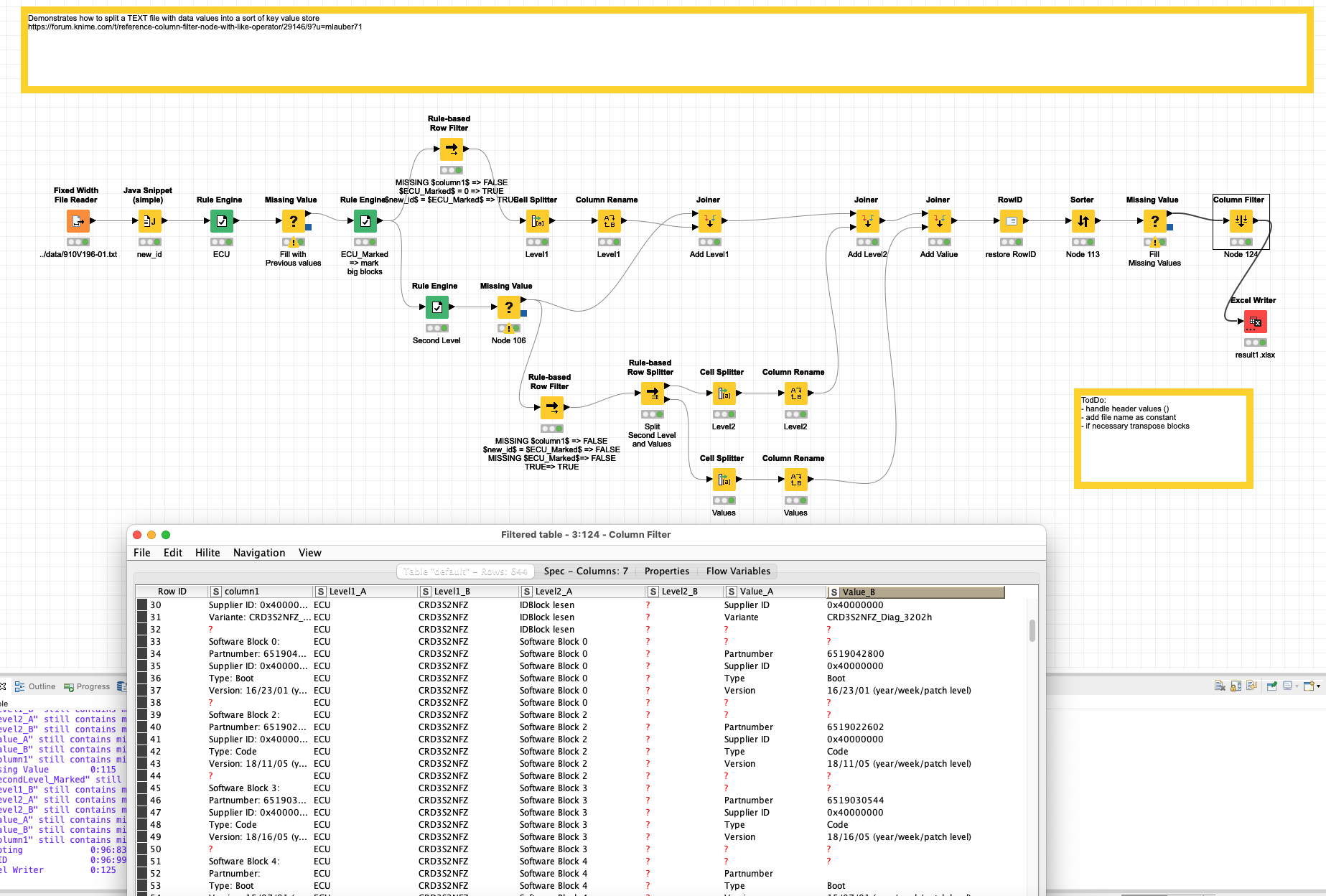
Some further cleaning and manipulation might be necessary. And you could now apply cleaning and word similarity approaches to the ValueA texts (or the LevelBs). The advantage would now be you have the data in a hopefully straight sort of database (or semi-transpose ![]() )
)
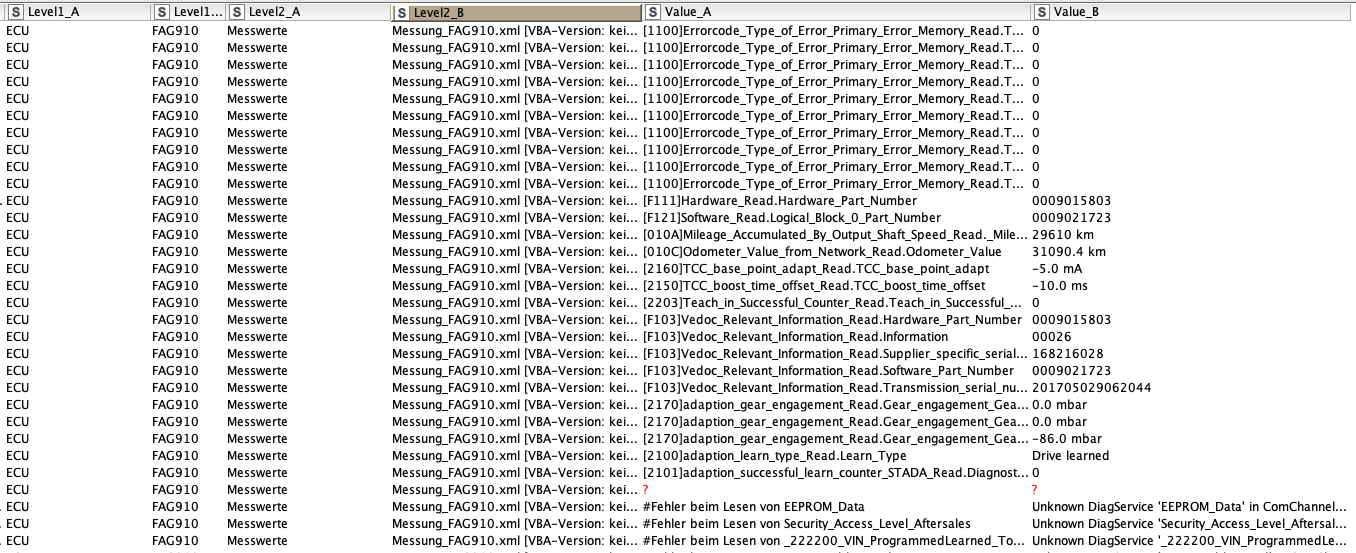
Here is the example - obviously some more work would need to be done (linke at the end there are some lines that do not fit the profile exactly):