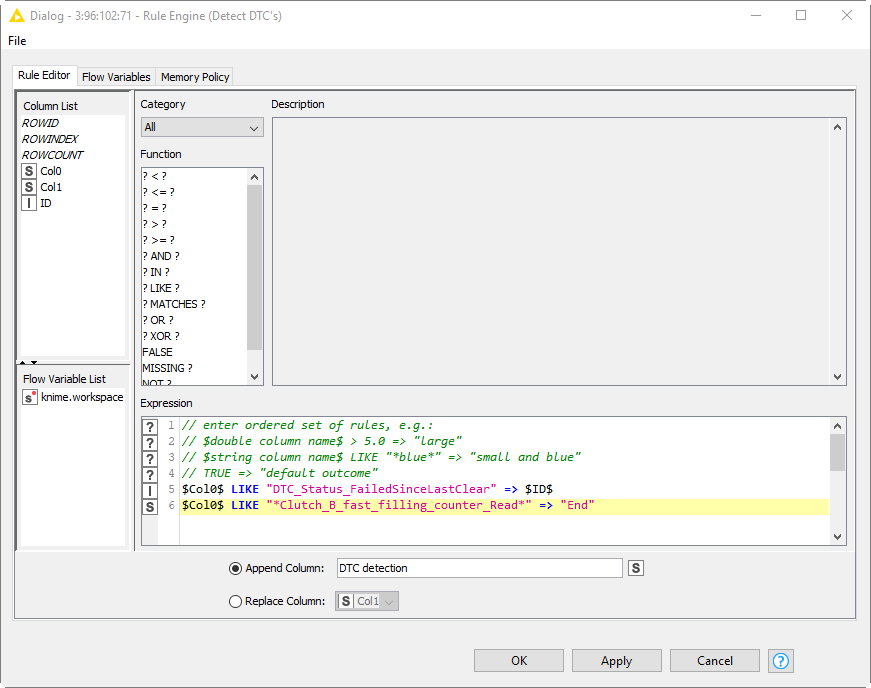
has anybody an idea how to use a LIKE operator in the Reference Column Filter Node?
I have the problem that my data columns have often an index or a dimension (e.g. “_1”, “[V]”, “[mbar]” or a combination) at the end of the column name. My references don’t have any index or dimension at the end of the string. In my workflow my refences are changing in every loop step so I load my reference table with a CSV Reader Node. The attached screenshot doesn’t work yet. It is only a actual development step.
I tried a nested loop with a Rule Engine Node. here I have the LIKE operator but my collected result is only the result of the last loop.
there is no LIKE operator in Reference Column Filter node but you can simulate one using regular expression in Column Filter node. For example if you would like to make sure to include columns where ID and Group words are part of column name you would use following regex: .*(ID|Group).*
Take a look at this example on how to build such a regex:
thx for the link! My problem is the very volatile data I need to process.If I look into my data manually the column headers are looking unique but they don’t. Sometimes there are “_” instead of " " in the column names or the ending for the name is like “_0”, “_1”, etc. That’s the problem I can’t check if my workflow filters the correct columns out of the raw data.
My hope was to make the filter comfortable with a reference filter and the LIKE operator. But unfortunately this doesn’t work as I imagined. Therefore also my other thread (CSV Writer Node hen egg problem).
I have set up a new workflow with a line reader node. Here I have the advantage for me that the input data are “static” and not processed in a loop.
I will have to filter a lot, manipulate and pivote strings, the usual one.
That‘s one of the big problems I have. No, they don‘t need to be in the same order. The data I read in are boring text files. One column at the beginning. My workflow creates out of this raw data several columns. Due to a lot of dependencies the column order can be the same but don‘t need to be. One reasons is the tool which creates these text files. Most of the time the running script works fine and I hope all data is collected. Sometimes how ever the script is crashing and the user dosen‘t recognize the crash or don‘t care about it an copy the not complete or Corpus files to the network drive I want to analyse.
I theoretically have the possibility to check the creates columns Boy a reference table but for this I need a Reference Column Filter Node with a LIKE operator.
@Brotfahrer from my perspective you would first have to formulate some sort of plan and maybe put your challenge into a sample workflow that would cover your whole set of problems as to ‘isolate’ them and help other people to understand what you want to do.
First not sure if it has been mentioned but there is a:
If you must use a function like LIKE you could try to restort to a small database and see if that does help (still the planning would be needed to extract the column heads and something like a positive reference of accepted/expected? column names).
This example uses H2 and BETWEEN but LIKE might also be an option.
Then of course there is a wide range of text analytics and similarity search functions and workflows in KNIME - but you might have to tread carfully how to employ such a thing.
And you will have to make certain decisions
my_column_1
my column_1
my column 1
MY_colmnn_a
Are they all the same, would you accept them oder would you just accept ‘extensions’ like _1 _a ? This very much depends on your data and your business case and again that would involve some planning ahead and formulating rules before resorting to some available technical solutions.
I have been thinking about how such an example workflow could look like. Since this doesn’t work, I share my entire workflow. Not with the expectation that someone in the forum will solve my problems, but to show the complexity. I hang a few shortened files with real data, because otherwise I cannot show the problems in a simple example. In the last Metanode “9HP48 DTC” there is another Metanode "DTC’s 2CSV ". Here I have all the described problems. To make sure that the workflow runs through to the end, I also attach the reference CSV files with them. DTC Extractor 2.knwf (237.2 KB)
@Brotfahrer I took a short look at the data and indeed this looks quite complicated and to be honest I still do not understand the role of the reference files. Are they supposed to match the data files (names?) in any way?
If I had to do this I would not try to solve everything in one big step but would try to approach it with some sort of data warehouse in mind (maybe using H2 or SQLite as local databases). Doing it all with Rulesets covering the variations might not be suitable.
The data files seem to have some sort of common structure with some unique information and then block of lines with information like the ones marked with brackets.
Also these blocks might have some common start and end block with Key Words. You might identify these key words and then proceed all of the information of one such block and put this in a database resembling a key value store
Database_performace_data
derived from block where you split the data by the information in the brackets [1101] and also a “:” and maybe some rules in addition with a Key indicator from a file name or some key from further up the file.
So you could identify and separate the information blocks and will be able to assemble them back later according to your needs, also such a construct would allow for some flexibility. You could start with some ‘modules’ and built from there.
You would identify the blocks with start and end RowID (by a certain keyword ) and process them into such small databases.
Data can later be aggregated (Min, Max, Sum), transposed into a flat table with dummy encoded variables, turned into arrays or just be kept as a data warehouse.
Obviously this very much depends on what you want to do with the data and how much you know about the variety of data that might come in.
Setting up such an import systems is very much doable in KNIME but as stated earlier it will involve some serious planning ahead.
Thank you for your patience and that you have taken a look at my data.
This is automotive data and especially diagnosis error reports.
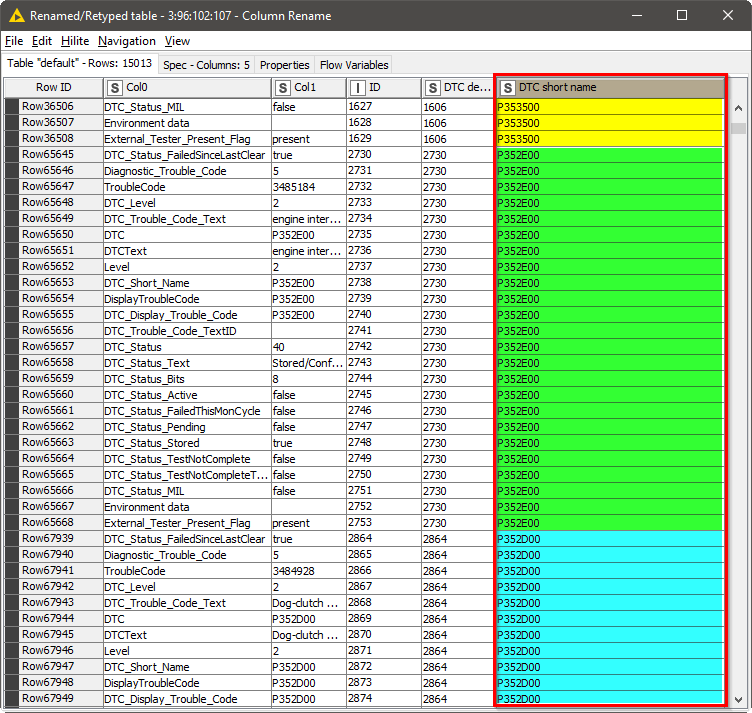
I would like to create dynamic tables from the “simple” raw data that are divided into a general part (the entries or rows with the square brackets) and the error report with fault freeze frame data. Exactly these fault freeze frame data prepare me for all the problems described above. If a fault is stored in a control unit, logging starts with the rows “DTC*” in which the respective error number is also referenced, e.g. “P353800” or" P07E700". Each of these faults (220 exists for the control unit considered here) has individual fault freeze frame data, which are each contained in the reference files. The challenge is to deal with the not always complete fault freeze frame data and write the data that is logged into the right column.
I thought, with the solution of the hen egg problem, I could have grasped sorting. Unfortunately, this is not the case. Therefore, my approach was to check the reference files for which environmental data may be relevant for the respective error.
I just look at the Similarity Search Node. It seems that this is exactly the missing link I have been looking for.
Basically, I will have to worry about a database structure. To do this, I first have to learn how my database makes sense. I will close the thread now and thank everyone (@mlauber71, @ipazin and @Daniel_Weikert ) who gave me valuable tips.
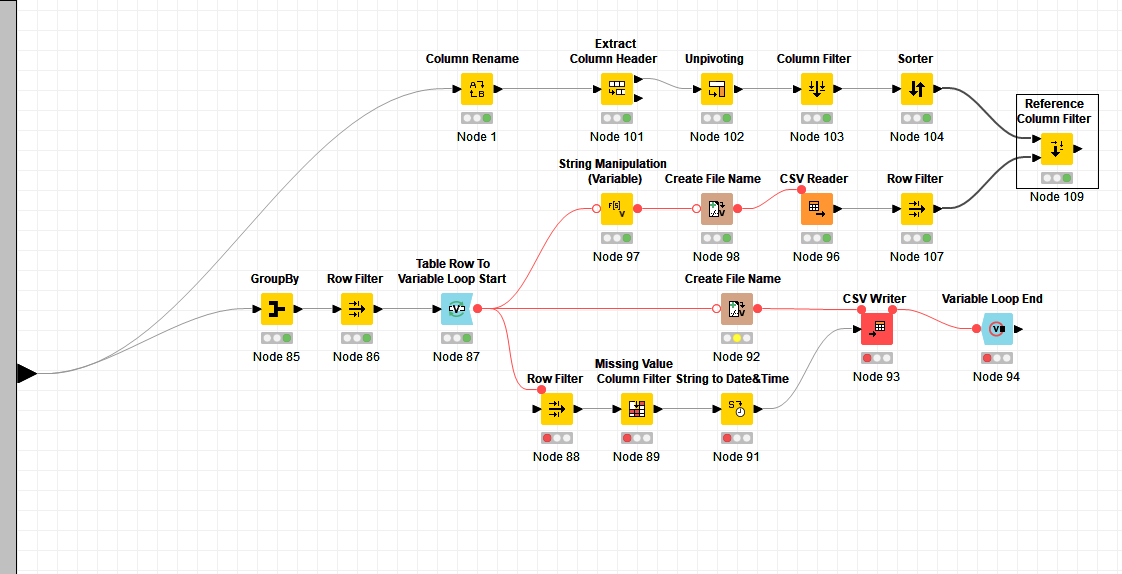
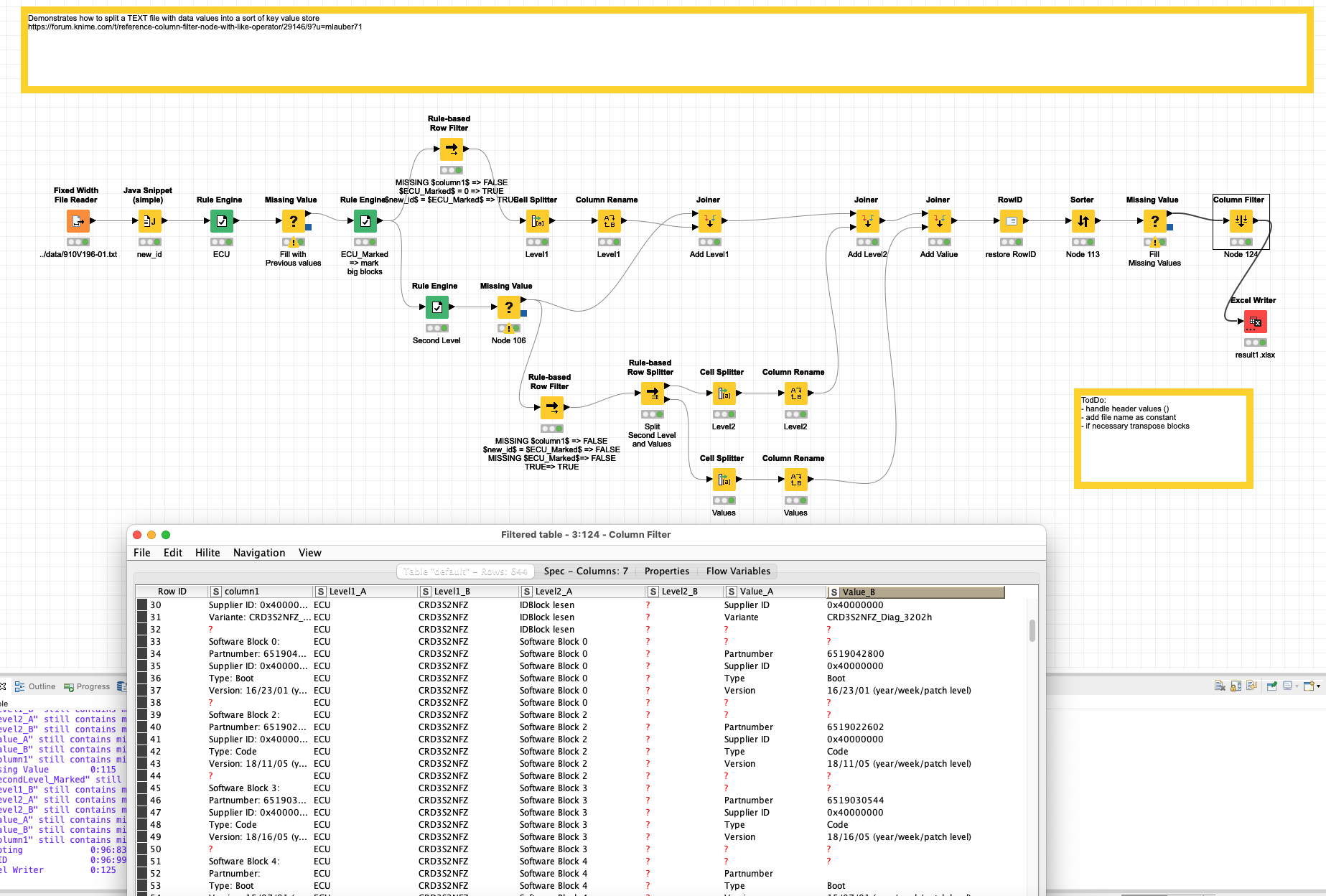
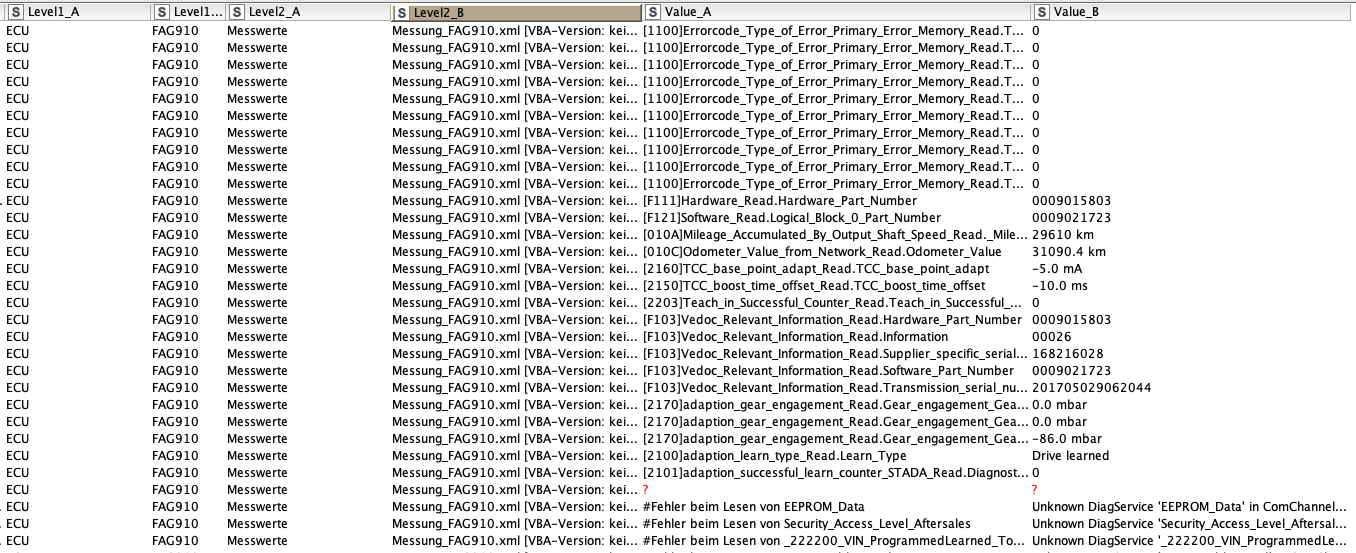
@Brotfahrer I had another look at the data and I would like to point you to another systematic approach. Using the underlying structure of the files to mark and split the relevant data.
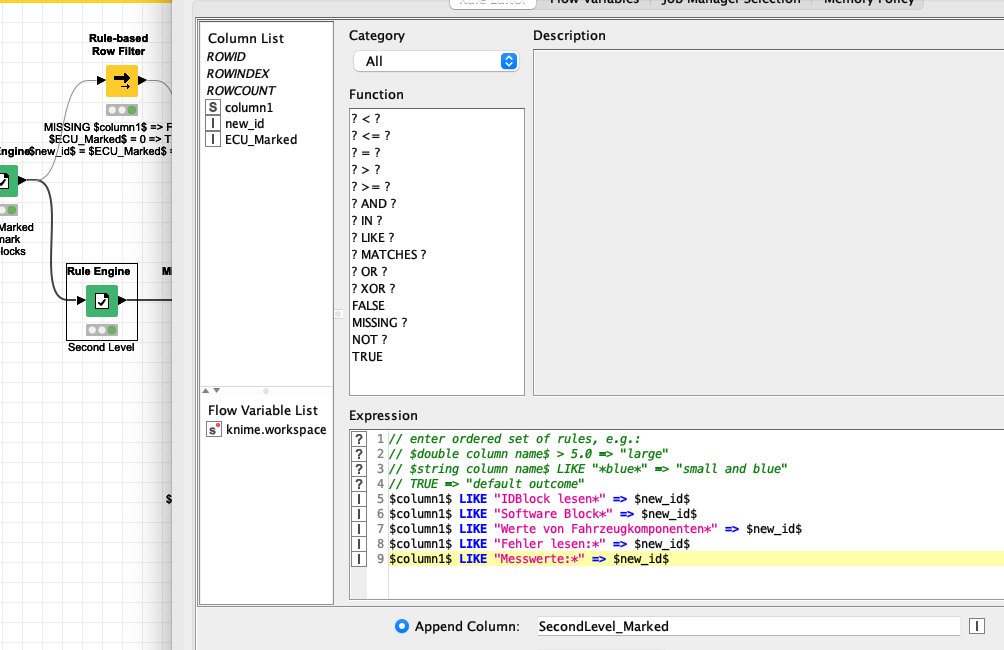
the big blocks seem to be defined by parts marked ECU. With the help of row numbers, you can identify and mark these blocks as “Level1” value pair. You would have to deal with the header values separately and maybe add the file name as constant column.
The new LevelB is formed by Blocks that can be identified by Keywords Like “Software Block*”
The result is some sort of a flexible hierarchy of 3 elements which you would now be able to further manipulate (extract numbers and dates based on keywords or something).
Some further cleaning and manipulation might be necessary. And you could now apply cleaning and word similarity approaches to the ValueA texts (or the LevelBs). The advantage would now be you have the data in a hopefully straight sort of database (or semi-transpose )
this approach to prepare data is awesome! Thank you for preparing and sorting the data differently. Above all, the first step to output the RowIDs in a new column opens up more flexibility. I will look closely at your workflow. It will take a few days but Christmas and Corona Lockdown are in front of the door. Then I’m not bored . I will definitely register, at the latest in the new year, how far I have come.
A question at the end: If I process my data according to the procedure you have proposed, and via the workflow, the corresponding columns with the logic key: Value, I then have the possibility to write the data later into a database (H2 or SQlite) and then use the keys as primary and secondary keys? Sorry but as already written I have no idea of databases .
Greetings, Merry Christmas and a good start to 2021 wishes
Brotfahrer
As a result, I was able to separate the fault codes from the rest of the data. With another Rule Engine Node and the Moving Aggregation Node, I could realize a negative lag and individually mark all relevant information on the respective errors. The additionally generated “DTC short name” column is used as group column in the pivoting node and the labels and value columns where previously processed.
If you want to use the vacation for some exploration into databases I have a collection with some examples ranging from simple to complex. If you need a primary key very much depends on your case. In a big data context you often just store the information without explicit key and later plan how to correctly aggregate the data to your desired ‘level’ (a key, an ID, a location, a product). That would typically involve some planning.
Merry Christmas holidays and happy KNIME-ing in the new year! @mlauber71

 . I will definitely register, at the latest in the new year, how far I have come.
. I will definitely register, at the latest in the new year, how far I have come. .
.