@Kazimierz I have built a demo that would illustrate how such a system could work. The interface of the component would look like this:
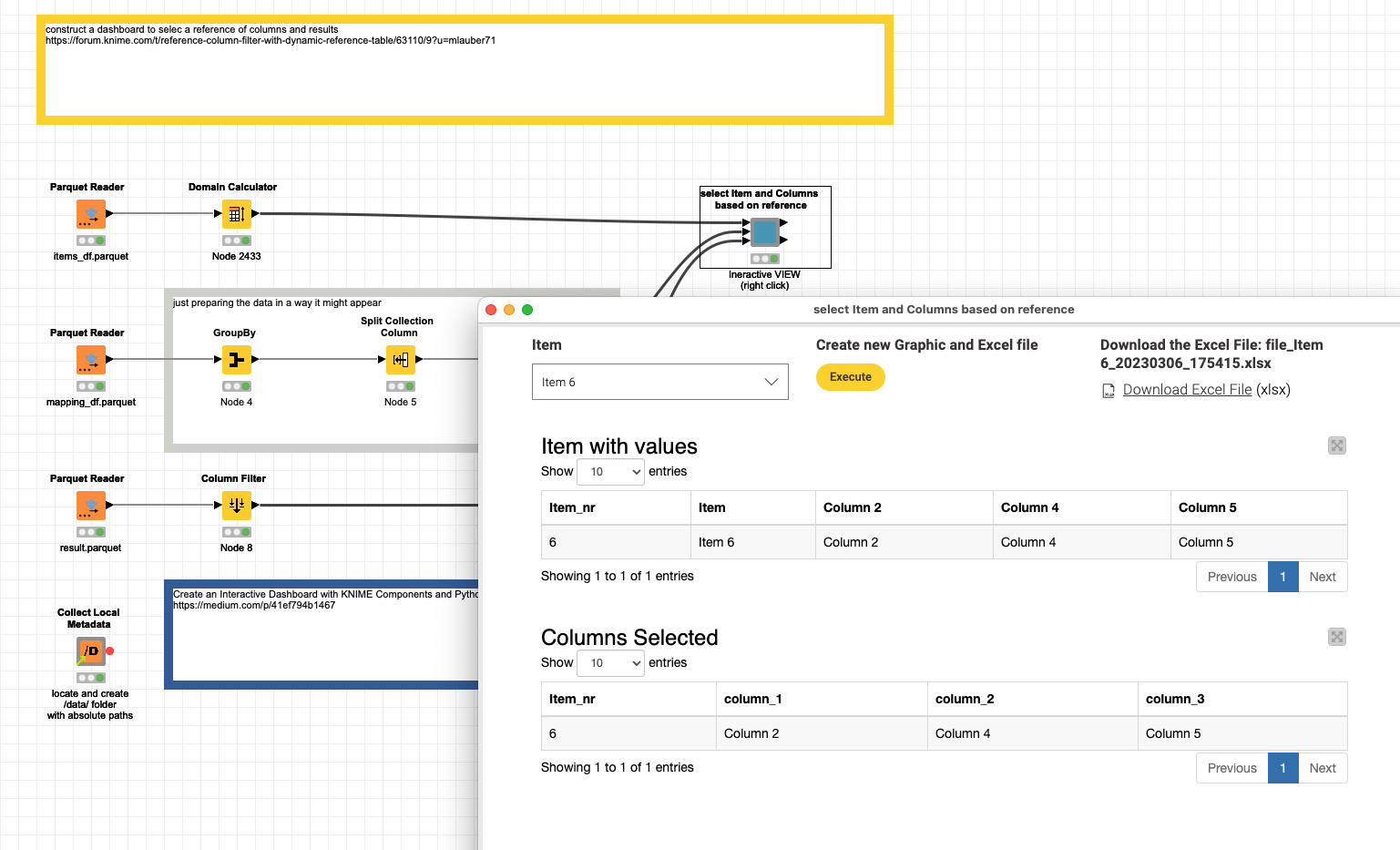
- you select the item
- the list of columns belonging to the item are dynamically selected
- the basic table is filtered by the Item and only the referenced columns are being selected
When you press the Execute button the select would happen. And an Excel file with the data and the selected columns would be prepared. Also the results will be available further down the stream.
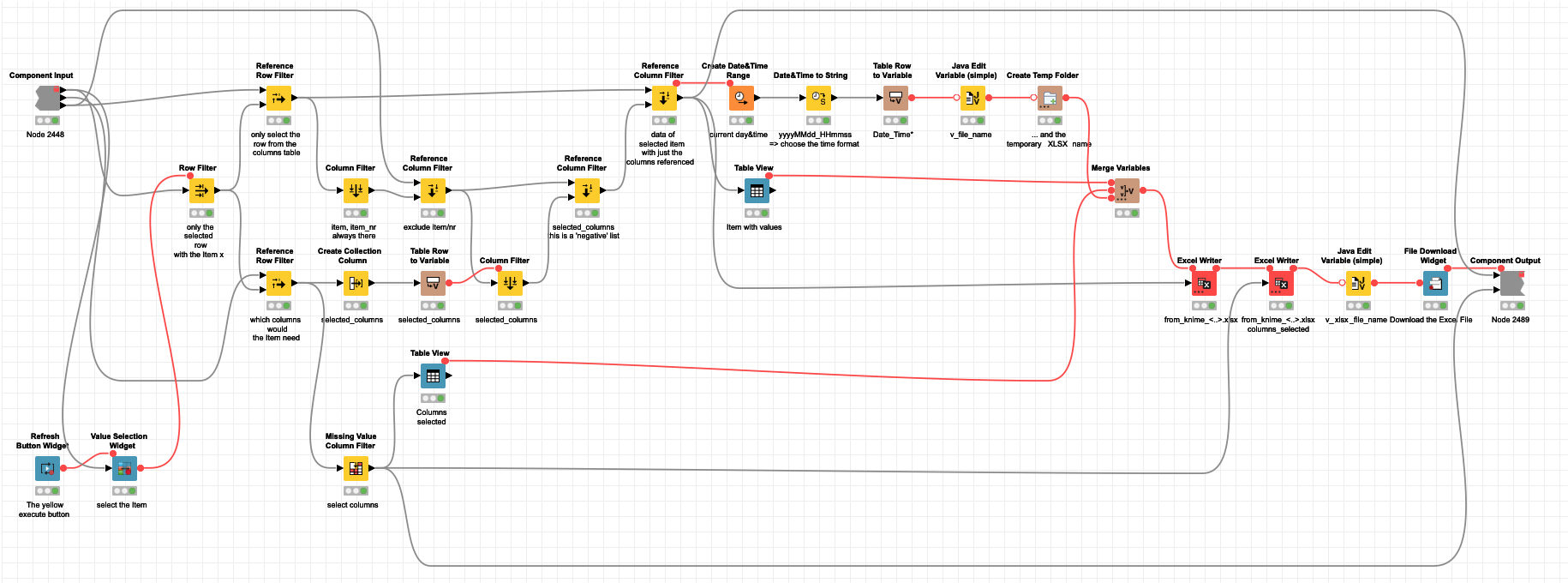
Maybe you check it out: