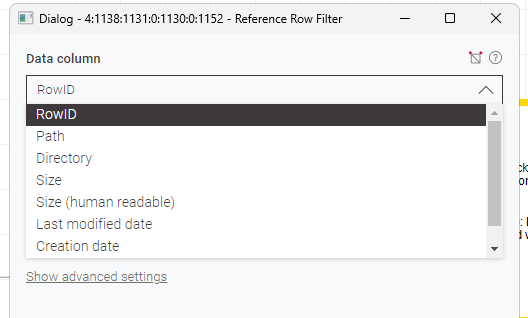
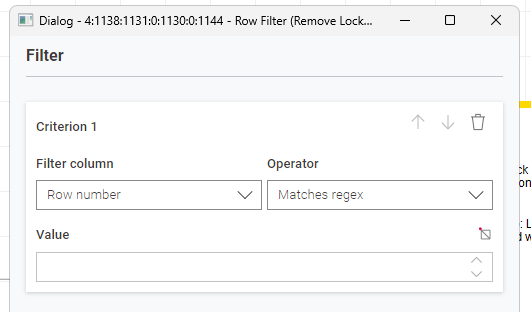
while working on an example workflow I encountered several issues when trying to filter by row index / number which required me, as the long value is required for filtering by row index / number, to explore other approaches.
I then realized the Reference Rowe Filter node RowID but not Row Number / Index which however the regular row filter does.
I’d like to suggest to keep all filtering options in a set of similar nodes fully aligned (if plausible).
Because Reference Row Filter is a quick way of joining and then filtering a table, I think constraining the node on RowID is okay, for it forces you to work with explicitly identified rows. That said, it does not hurt to have more options
I don’t get it Anyways, for consistency reasons and because a numeric filter is / can be more precise than a string based one, having row number based filtering is based on my experience superior.
That reminds me of several topics we exchanged about. In regard to the star alliance group, wouldn‘t it be a nice idea to collect limitations in one post?
I have a hard time understanding what you would want to achieve with “Row number” and “Row index” options in the Reference Row Filter. Both of these options are “virtual”, in the sense that they are not present in the data (so are not data columns) and are just a dense list of integral numbers starting at 1 (or 0) and going until the size of the table (or size-1). Would you expect it to work like a Table Cropper with maximum row numbers/row index configured as the size of the reference table? Or am I missing something?
The Row Index, now called Row number in the new Row Filter, serve many important purposes and provide a greater value that the RowID. For one thing, when add the row index as an actul column, do some transformations, unpicot, tranpose, sorting you name it, you can always return to your original row order sequence. With the RowID that is not that straight forward since it is a string.
About filtering, imagine you transform and filter a table per your liking, resulting in results you want to extract from your original table. You’d be requried to do a multi-match filtering. Using the row id, it is just one step.
Though, the question also raises, when RowID as a “virutal” option as you describe exsists, why not the row index? In generall I’d also stringly suggest to keep namings aligned. “RowID” was kept but Row Index became Row number and it all of a sudden starts at 1, not 0. These disjoints introduce unnecessary friction in many ways.
I understand the difference between row number (consecutive numbering of rows) and RowID (uniquely identifying a specific row). Maybe a bit of context/justification: for new nodes (or modernized ones) we use “row number” when the numbering starts at 1 and “row index” when it starts at 0. Old nodes may be inconsistent, but this is exactly what we’re trying to improve: to make it clear what the first value will be: 0 (index) or 1 (number).
Historically, index is used when an offset is specified: the first element is not offset (so index = 0), the next element is offset by one (index = 1), … and many languages use this “offset notation”. Though, we made the experience that 1 seems much more natural for many people, especially non-programmers. That’s why we focussed on using row number in the new Row Filter. But we also hear your feedback (and I think we got that feedback somewhere else already), that sometimes row index is more convenient, e.g. when you want to set it via a flow variable and want to avoid using an expression that does just -1 beforehand.
Regarding the original topic:
I was asking for clarification, whether I understood it correctly. I wanted to ask, and maybe expressed it not well enough, whether selecting the option “Row number” in the Reference Row Filter between the Filtered Table and Reference Table would work like you using a Table Cropper configured on Filtered Table with the maximum row number equal to the size of the Reference Table. If so, it is already possible to express this operation with existing nodes (Extract Table Dimension, Table Cropper). But on the other hand, adding this option to the Reference Row Filter should be easy and could be very convenient (although we would have to see how intuitive/understandable it turns out to be). I’m just trying to avoid that we have too many nodes that do almost the same thing, where it’s unclear which should be used, and where two workflows look almost the same but do totally different things :).
Catching up … sorry for the late reply. It wasn’t aware to me that it’s now differentiated between “row number” and “row index”. Row number wasn’t something available before and since row index seems gone, I concluded the later succeeded the first.
With that knowledge, I believe we found the cause of the misunderstanding. WDYT?
And we already heard that in some circumstances it would be useful to have both Row number and Row index (i.e. offset) available as options, since it sometimes removes the need for a +1 or -1 expression beforehand. But I think this discussion would derail the topic at hand (though we are welcoming separate feature proposals with use cases where it would be beneficial!).