Hi @Kazimierz,
as you have found, dealing with names dynamically isn’t a simple thing to do. I have some questions for you though as I am wondering how many “levels of dynamic” you have here, and maybe based on the answers, we can think up a way forward.
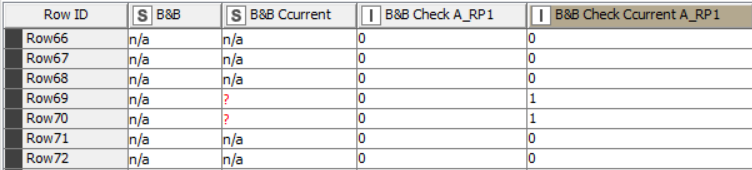
The obvious dynamic values is the column names, where you have varying prefixes.
The second “dynamic” appears to be that you have in each subset between 4 and 30 columns, and it appears (or I may be misunderstanding) that you also have dynamic “suffixes” too e.g. _RP1 ?
The only nodes that come to mind that can reference columns names dynamically “out of the box” are Column Expressions and Java Snippet, and I could include the python nodes too. Whilst both Column Expressions and Java Snippet have functions to access column names using variable strings, they don’t provide the ability “as standard” to dynamically create a column name. It would be possible in both cases though to have the output column name specified by a flow variable, to make this work dynamically. It isn’t necessarily pretty but it can be done.
Rule Engine doesn’t work dynamically “as standard”, and must be supplied the rules. However, the rules could be “crafted” dynamically using String Manipulation and passed in as a flow variable. Again, not simple, and you can spend a lot of time trying to get the string “just right” so that Rule Engine doesn’t complain, but it can be done. The Rule Engine (Dictionary) may be a little easier to work with “dynamically” because it takes its rules from a table, and the rules could be dynamically generated with other nodes, but you would need to pass in the name of the column to be appended dynamically, and so this would have to be done using a flow variable. The table of rules could be written in such a way that you could use string replacement to adjust the rules in a loop
e.g. the rules could be something like
$#prefix#_Check A_#suffix#$ = 0 AND $#prefix#_Check Ccurrent A_#suffix#$” = 1 => FALSE
TRUE => TRUE
and then in a loop (or loops) you replace #prefix# and #suffix# with the required dynamic values? I haven’t tried it, but it feels like it ought to be workable.
The above options, whether it be java, column expressions, a variety of “dynamically fed” Rule Engines would need to be put into some kind of loop to process all the subsets and columns. I’d need more information before I could tell whether any of these would be a suitable direction to try.
Thinking out loud some more, I would expect there to be loops involved here, one of which would be terminated a Loop End Column Append node.
Q. Do you know in advance all of the column prefixes and know all the columns that you will need to create?
Q. For any given “subset” of columns are you going to be creating just one additional column, or multiple additional columns?
Q. If adding more than one additional column, is there any “standard” to the rules you will need to apply? i.e. how do you know which existing columns are to be used in any given rule, or are these all pre-defined (know) rules?
Other thoughts, depending on how dynamic this all is… if you know in advance all the subset prefixes, you could probably use a loop that goes through the list of prefixes, and uses a column filter against the table to provide only those columns with the given prefix within the loop. You then perform a regex rename of the columns to remove the prefix, have a set of rules in Rule Engine or whatever that don’t have to know the prefix because you’ve stripped it off the columns. Then at the end, you regex rename the columns again to put the prefix back on. Finish with a loop end (column append) and “re-assemble” the table on the other side of the loop.
With this last thought, if you can deal with your columns one subset at a time within a loop like this and “temporarily remove” the dynamic prefixes for the subset, can any of those unpivoting ideas be made to work?