Hello all,
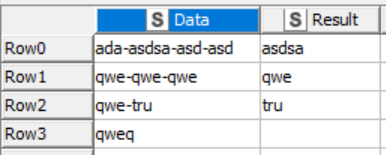
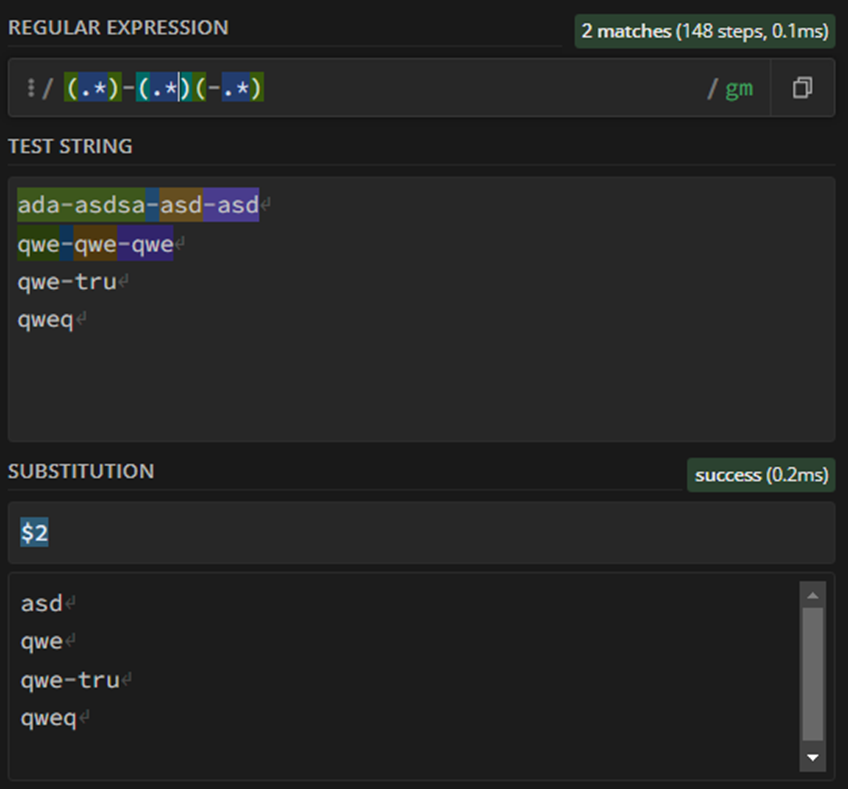
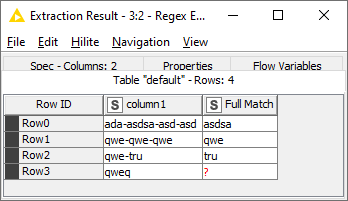
I have column “Data” from which I need only data after first “-”, but before second one, please see table. So my aim is to have what you see in the column “Result”
[^-]+ means “one or more times everything but the dash character” and so you have everything but a dash character one or more times, followed by a dash, followed again by a string of everything but a dash (captured in a group this time), followed again by a dash and then the rest, which we do not care about (.*).
Kind regards,
Alexander
Hey,
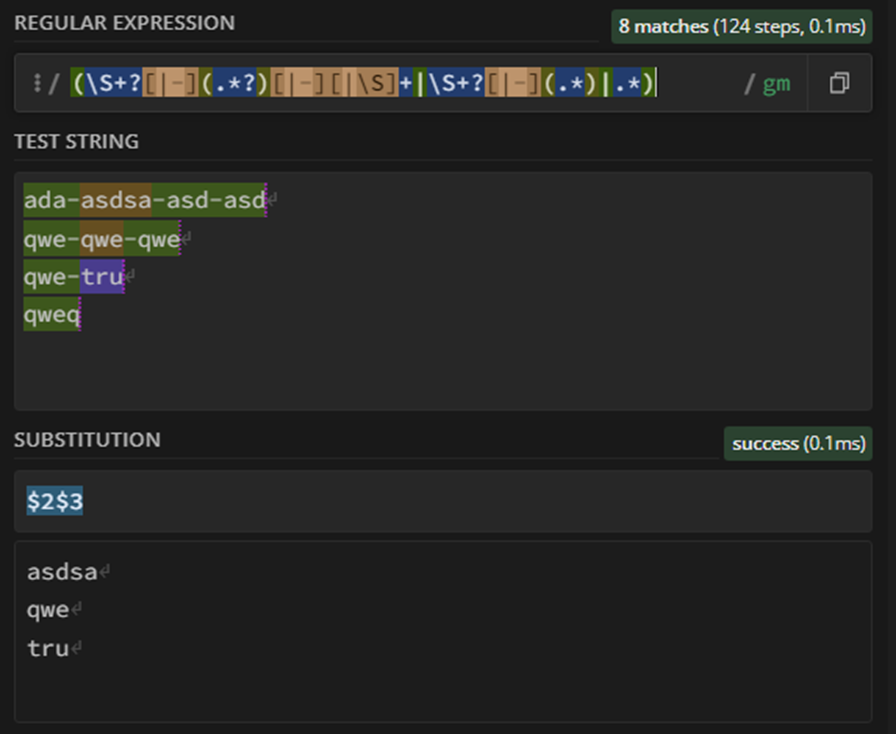
Good point! Now I think I have found a one-node-solution, but it is not very pretty. You can use this expression in the String Manipulation node to handle all 4 cases:
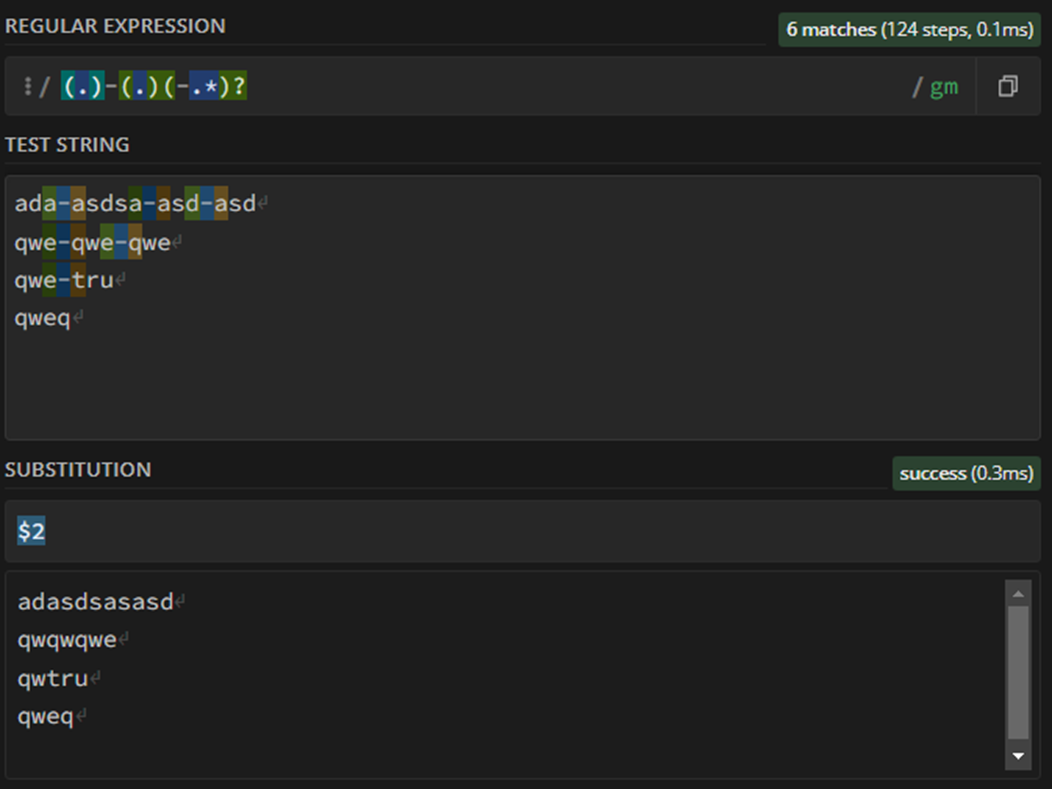
Hi guys… just use it to get the only second element:
regexReplace($column1$, “(.)-(.)(-.*)?”, “$2”)
I know that I have the first element until the first “-”, then you have the second with the same condition, BUT you can have or not something after that. the “?” was set to this propous. I delete the first and IF i’ve something as the third value, and get the second value only.
If you works with numbers, can use “\d+” OR “[0-9]+”
If you works with numbers, can use “\w+” OR “[a-zA-Z]+”
Use the “-” as separator between them and “()” to save as variables.
Hi,
The Cell Splitter approach could cause problems when none of the examples have a dash in them. Then the cell splitter will not create the necessary column and the workflow will fail, so you will need to check if the column exists with a Table Validator and handle the case.
Alexander
I’d use the Regex Extractor node with a positive lookbehind: (?<=^[^-]+-)[^-]+
Basically, it first looks at the beginning of the line and finds a string of letters that doesn’t contain a dash, but ends with a dash. Then it returns the subsequent string of letters that doesn’t contain a dash.