My mental approach . . .
(1) find the position of " - " because this is unique if it is between digits
(2) after knowing the position of (1) I need the position of the first alpha numerical character (in the example “N” but and then "X’ , “K” cq “Z” . . . important to know that that first alpha character varies from A-Z))
(3) insert a seperator (e.g. "; ') just before the position of (2)
P.S. Sequence explanation:
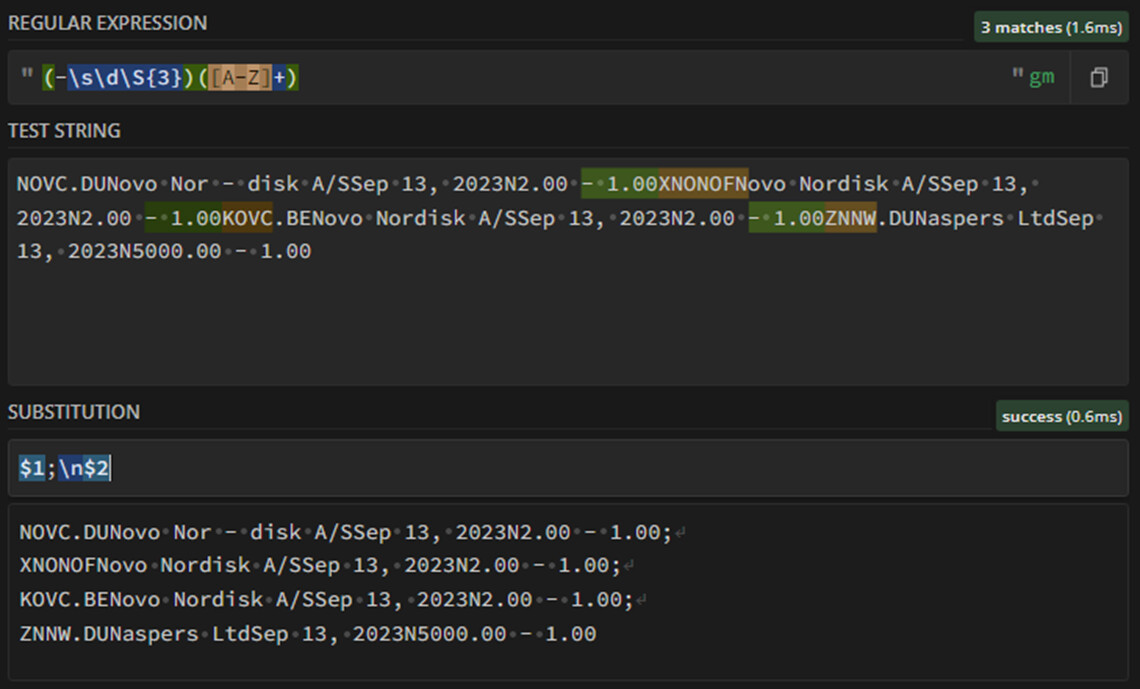
1st capturing group $1: one dash -, one white space character \s, one digit \d ,three non white space characters \S{3}
2nd capturing group $2: any sequence of characters in range A-Z [A-Z]+
It works in most cases but with “\S{3}” the script assumes that after " - " follows alway 3 non white space characters.
However, sometimes there follow 4, 5 or 6 non white space characters. The problem is that how many n-w-s characters follow.
(therefore I was thinking about rule (2) of my mental approch and counting the position of the respective characters)
So, could there be a general solution irrespective the number of n-w-s characters?
Or e.g. less than let’s say 10 characters
-Sander
= = =
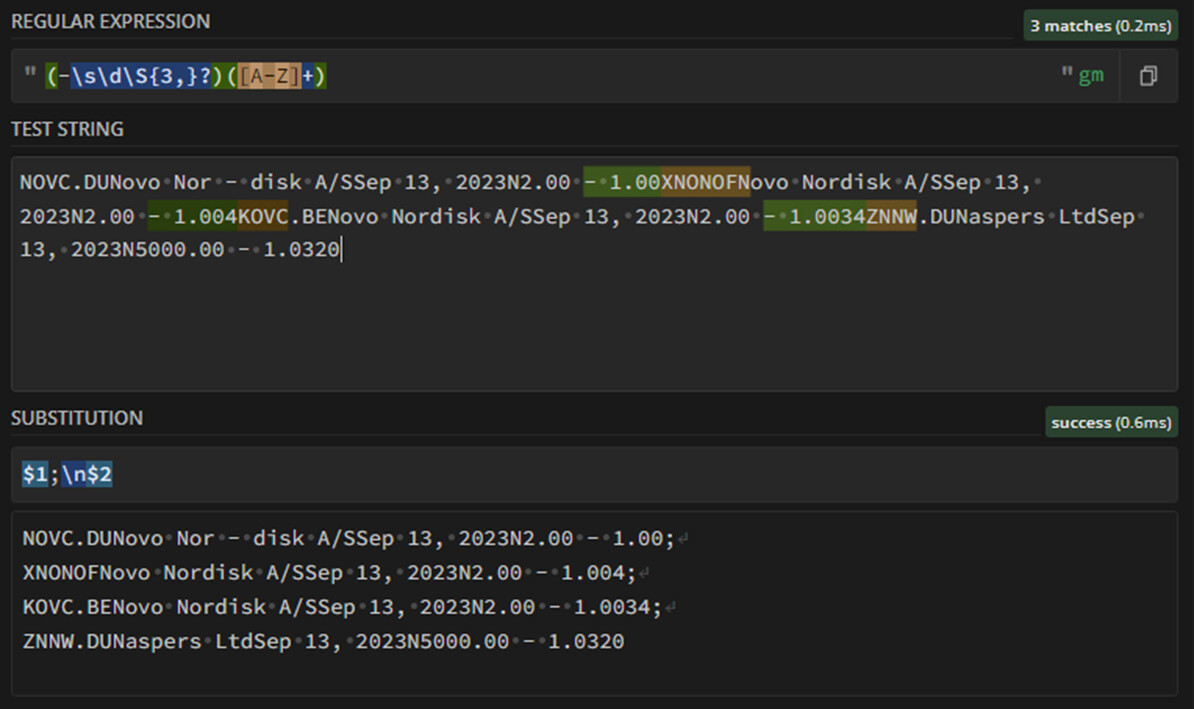
I modified the example a bit with dynamic n-w-s characters
Hello @sanderlenselink
I’ve modified the sequence by modifying the \S{3,}? quantifier adding a comma (3 or more of \S) and making it lazy with a ‘question mark’