I’m trying to check the source code of a bunch of web pages to see if they contain a link back to a specific domain. I think the best way to do this is to use the Rule Engine, and use the MATCHES operator with Regular Expressions, but I can’t seem to get the syntax right. Here’s what I’d like the REGEX statement to look for:
href=
Include a variable number of wildcard characters, maybe anything from 0 to 75
The only part that I’m struggling with is the part between “href=” and “example.com”. In this case, it matches anything that has a link anywhere before it mentions “example.com” in the source code. I actually figured out what I thought was the right answer, but I don’t understand why it isn’t working:
I thought that “[^>]+” would be better than “.*” because it basically says I’ll allow any character except for something that closes and HTML tag (>) between “href=” and “example.com”, but it isn’t working, and I don’t know why. I tried putting different sections in parenthesis, but that didn’t seem to help either.
According to me, the regex solution to find links on webpage is not a good approach.
The first problem is the presence of false positive cases (all above example would extract link in html comment, for example).
Regex cannot be know if a matched string is included in a javascript tag or an html comment.
So, the mental process to follow is:
“what I’ve to find?” Links.
“What is a link?” It’s a concept valid in html language.
So I’ve to reason with html (or xml) language.
You can apply an xpath query with XPath node
//a/@href
Now you can filter domain by regex.
(In XPath 2.0 you can include regex in your xpath expression but Knime Xpath Node uses Xpath 1.0)
Workflow I posted doesn’t match your last example.
In that example you are passing domain as parameter to another domain.
If you want etract all links where your domain is passed as parameter you can change regex according this rule.
.?-=(www.example.com)
I don’t really have any experience building my own web scraping tools, but your logic makes a lot of sense. I should look for links first, and then try to see if they contain links to the target domain.
I’m uploading an example workflow that I’ve failed at 3 times. The first method is the path I started down initially. The second and third methods are trying to use XPath, but they’re both not working for some reason. Any chance you could take a look and help me figure out what I’m doing wrong?
great to see that you’re using the Palladian nodes! I totally agree to @pigreco, you should not do this through regex (this is way too error prone), but with a proper DOM parser. The HTML Parser is the right tool for this.
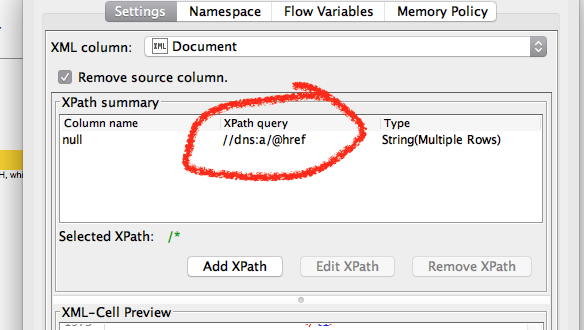
I had a look at the workflow, and the reason why you see no results in the XPath node is simple and easy to fix. The XPath expression should be //dns:a/@href (note the dns: prefix). This is a peculiarity of how KNIME handles XML, but once you’re aware of it, easy to remember (for more details, check the “Namespace” tab where you can see the document’s namespaces and their prefixes – basically, the prefix needs to be prepended to each element name in your XPath query)
I’ve put the fixed WF on my NodePit Space, you can get it from:
Thanks Phillip! This works great! I was having an issue with the HTTP retriever not working on all my input sites, until I checked the box to “Accept all SSL certificates (only enable this if you understand the implications”
I’m not really sure I do understand the implications, and I tried Googling it, but I wasn’t very successful. It’s hard for me to see how checking for backlinks like I’m doing now, would be a very risky task. Can you envision any reason why I should be cautious about accepting this?
You should however be careful when you use the HTTP Retriever for submitting sensitive information (e.g. login data, personal information, etc.). In this case, an HTTPS error might indicate that something’s wrong – a Web browser would warn you in this case with a “This connection is not private” or similar that your personal information could be stolen.
Again, for just checking the backlinks, you’re fine with enabling the checkbox.
 (for more details, check the “Namespace” tab where you can see the document’s namespaces and their prefixes – basically, the prefix needs to be prepended to each element name in your XPath query)
(for more details, check the “Namespace” tab where you can see the document’s namespaces and their prefixes – basically, the prefix needs to be prepended to each element name in your XPath query)