You’ve got to properly prepare the Tika output before you can use it. You’ll have to adjust the file paths for your system.
Is there anyway to just past the file paths in table creator node and then parse them using the Tika Parser URL input node with this workflow? It is much easier to do it that way when dealing with thousands of pdf’s. @rfeigel
Without some sample URLs I can only make an educated guess. Try this workflow. It should loop through your list.
1 Like
Did the last workflow work for you?
just tested it now, i basically just created another dummy file with the name on the same line. and parsed the two files one with the name on the same line and one with the name under. and it managed to extract both, ill keep testing it with different names! But thank you so much !!! @rfeigel
If it works, please mark “Solved”.
2 Likes
So i have been playing around with it, and I did find some issues. It only works if the name im trying to extract (John Doe) is the only text on the line under the keyword “Name:”
i tried another case scenario if i have
Name:
John Doe 293847298347 9993289830
when i run the work flow it extracts the “9993289830” instead of John Doe or even the whole line would be okay and i could just then separate it or clean it up in excel. Is there anyway you can modify the workflow. I can send another dummy file with numbers or text after the “John Doe” @rfeigel
You would have saved us both a lot of time if you had supplied a complete set of variations at the outset. I can’t continually guess what your data looks like. Send a COMPLETE set of variations and I’ll take a look.
1 Like
Which workflow are you using? I don’t understand why it would extract the last series of numbers. Based on my testing it should extract the name and the following numbers. I’ve added some regex to remove the numbers.


I can’t test the Tika Parser URL node since you haven’t supplied any URLs. To test the mechanics of removing trailing numbers, I edited the hard copy PDF you sent me with the following name configurations in four separate PDFs:
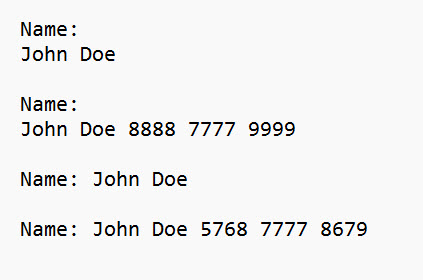
The new workflow seems to work properly. Here’s the output:
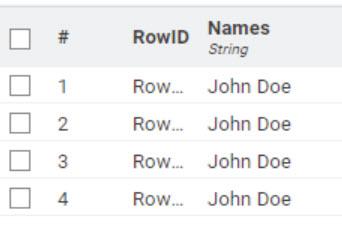
i was using the last workflow “Name Extractor Tika Parser URL”
Here is a dummy file i made, that i also used with the last workflow you sent, i know it might be a slightly different pattern but basically it is like
Name: DOE,
John
the same file also has the regular pattern which is
Name: Doe,John
is there a way you can change the workflow a little to adapt to these patterns
here is the dummy file
Untitled 3.pdf (12.8 KB)
You’re driving me crazy. This format is totally different than the previous ones. Its going to take some serious surgery. In this file “Name:” is entirely capitalized as “NAME:” Is this correct? Do the actual files have both formats? Are the changes ever going to stop?
1 Like
actual files have the last two formats i have just sent today. I can always use different workflows depending on format. Yes correct in the workflow in my workspace i changed all the regex nodes to have the word “Name” capitalized
So you don’t have any data formatted like this?
Why did you capitalize “Name”? Is this the way the actual PDFs are formatted? Otherwise it seems like an arbitrary change which requires unnecessary changes to my workflow.
I’m quoting you: “actual files have the last two formats i have just sent today.” Any more changes you’re on your own. I’m worn out with your constant changes. Here’s the input from the PDF you sent:
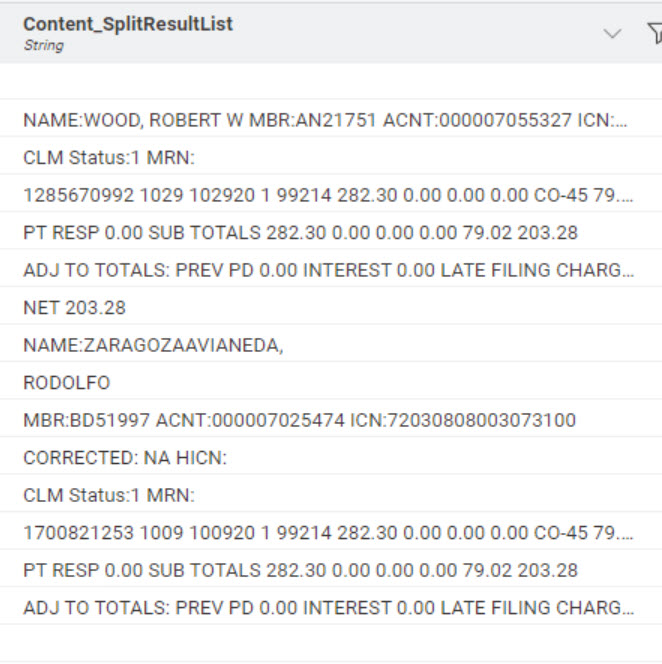
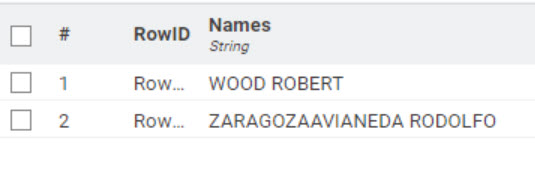
Can have either name order you want:
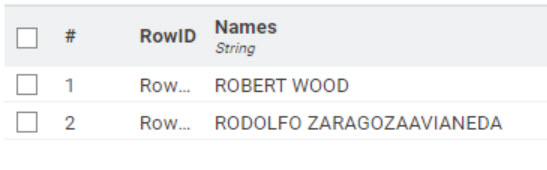
1 Like
@rfeigel no more changes, i just thought the workflow would still work. and I would like to take the name as it is. so it would be WOOD ROBERT, and ZARAGOZAAVIANEDA RODOLPHO
The last data set you sent is very different from any of the earlier ones so the previous workflows obviously wouldn’t work. Here’s a new workflow which works with your last data configuration.
Here’s a workflow with the Tika Parser URL node. I can’t test it since you won’t share any URLs.
1 Like
Okay thank you again! Sorry I was not clear initially, I will try these workflows
The name convention can be tricky, with the different types of patters. Now will these workflows work if i just change the keyword in the nodes. So if i have for example
Member ID:
9999919999
All i have to do is just change the “NAME” or “Name” to “Member ID” and it should extract whatever is under it using your previous workflows. but the most frequent one you sent should extract for example
(“Name” or “NAME”) Depending on what is actually configured in the node but either way,
Name: John
Doe.
@rfeigel
Where did Member ID come from all of a sudden? You said “actual files have the last two formats i have just sent today.” I configured every workflow based on the data you gave me at that point. Its pretty obvious that you don’t have a solid understanding of your own data so how do you expect me to stare into a black hole and guess what’s there? “The name convention can be tricky, with the different types of patters” is of no help at all.
1 Like