Hello all, i was wondering if anyone has any input on how i would extract text under a keyword using regex extractor or any other nodes that are able to do so. for example if i have the keyword “Name:” and one line under it has the actual name i want to extract how do i get that. In a scenario where there is no other keywords to use that are on the same line as the actual name.
Is what you’re calling “keyword’” actually a column header? Also, do you only want to extract the first data element (name) after the column header or everything in the column? If you post a small data set and explain exactly what you want it would help.
1 Like
No so basically if i have a medical bill or invoice, and i only want the name and no other text i usually use a regex expression to extract the text after the word “Name:” because the text is on the same line as the keywoord. Which is the keyword im using for the regex expression in regex extractor. For example if i have a medical bill, and the name i want to extract is printed like this “Name: John Doe” i want John Doe and nothing else out of the page. i use a regex expression to extract text after the word “Name” i have no problems with that but now i have an issue where it is printed like this
“Name:
John Doe”
so the actual name of the person is under the keyword “Name”. How could i use the keyword “Name:” and extract under it to get “John Doe”
Hope this is a better understanding
@rfeigel
It would be a lot easier if you provided some sample data.
1 Like
It is confidential or else i would, for any instance i’m wondering how can i extract a line of text under a keyword, the keyword is always the same in every document. In python I will use a function to get text after 2 lines or 3 or whatever the case may be but im trying to figure out how to do that in knime using the regex extractor. I’m not sure if a lag column node will shift the regex down or im pretty confused how this would work as i entered this regex to extract one line under the word “Name” in the regex extractor but it didnt seem to work. Regex I tried was = (?<=Name:\s*).*$
@rfeigel
Share some dummy data with the format you have.
2 Likes
Since you won’t share any sample data, I’m doing some guessing. This workflow is pretty crude but works with both: No Regex.
Name:
John Doe
Name: John Doe
Name Extractor.knwf (86.6 KB)
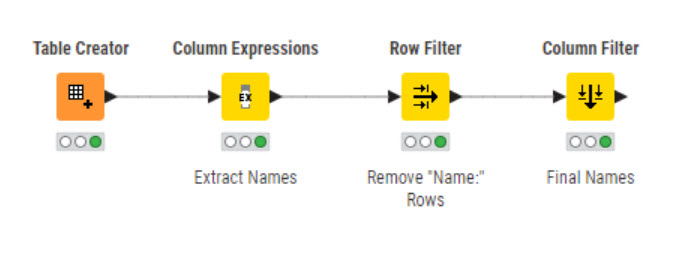
Input
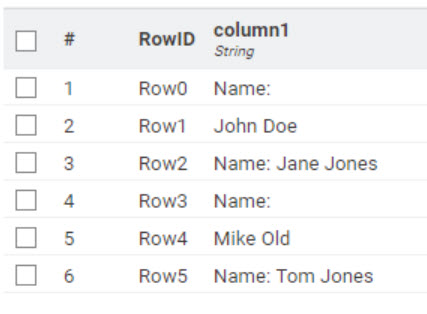
Output
4 Likes
im not sure how to make some dummy data. But the workflow would need regex because the name of the person im trying to extract may not be on the same line everytime… Is there anyway to use my regex to extract everything on the same line after the word “Name:” but to also take the exactly 1 line under the word “Name:”
Have you looked at my workflow? I think it does what you want. I can’t understand why you’re insisting on regex.
3 Likes
Yes, because what if i have a bunch of files and the word “Name” is in a different row for each file.
I can’t help you without some sample data. Your description isn’t clear enough. What happens when you run my workflow?
The new expression node does have Regex extraction functions. With knime you will have to double escape \ backslash.
One example in this workflow:
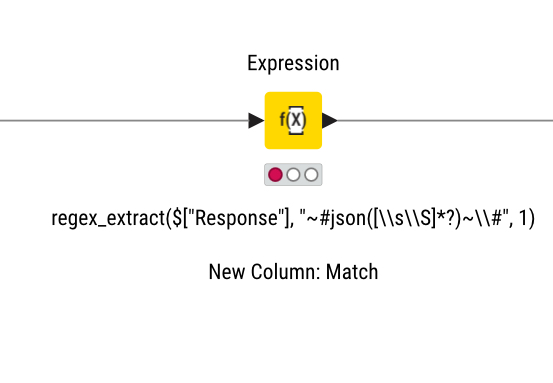
Regarding the syntax you could employ ChatGPT and also may want to think about edge cases.
2 Likes
Here’s a workflow with Regex. I don’t think it does anything that my first workflow didn’t. I still don’t completely understand your data configuration.
Name Extractor rev 1.knwf (99.7 KB)
2 Likes
@mlauber71 is there a regex expression that will extract 2 lines of text after a keyword?. the texts I’m trying to extract are in a line, but not always on the same line. and not in a column. @rfeigel.
Sorry about not providing dummy data, i can give you a better example.
Med Facility
ibfaiuwebflwaiuf
Name:
John Doe
Now if i were to paste that text in table creator then it would be easy to just extract by row filter, but i have to parse the pdf files. So im pasting the file paths in tablke creator and then outputing to tika by url. Then parsing the file, so i would then need regex expression, because the name im trying to extract out of every file may not be on the same line. Unless there is another way. Let me know when anyone gets a chance, thanks for your contribution/help so far!
Do you still have cases where the name is on a line like this “Name: John Doe” ?
@rfeigel yes correct
when its like this “Name: John Doe” i use this regex “Name:(.*)” which works but then when the name is like
“Name:
John Doe”
it wont extract it because the regex is to extract everything on the same line.
@rfeigel
Try this. The bottom workflow handles both single and two line names.
1 Like
Untitled 1.pdf (17.2 KB)
I have attached a dummy file here. Now just a reminder, this file can easily be done with just row filter to extract the name. But I have a lot of files where the name is not on the same row. I tried your workflow, it does work when you just paste the text in the table creator but i couldn’t get it to work when i added a file path and tika by url to parse it. See if you could access the dummy file, it has the keyword “Name:” and then “John Doe” under it, when you get a chance see if you can extract the “John Doe” with regex.