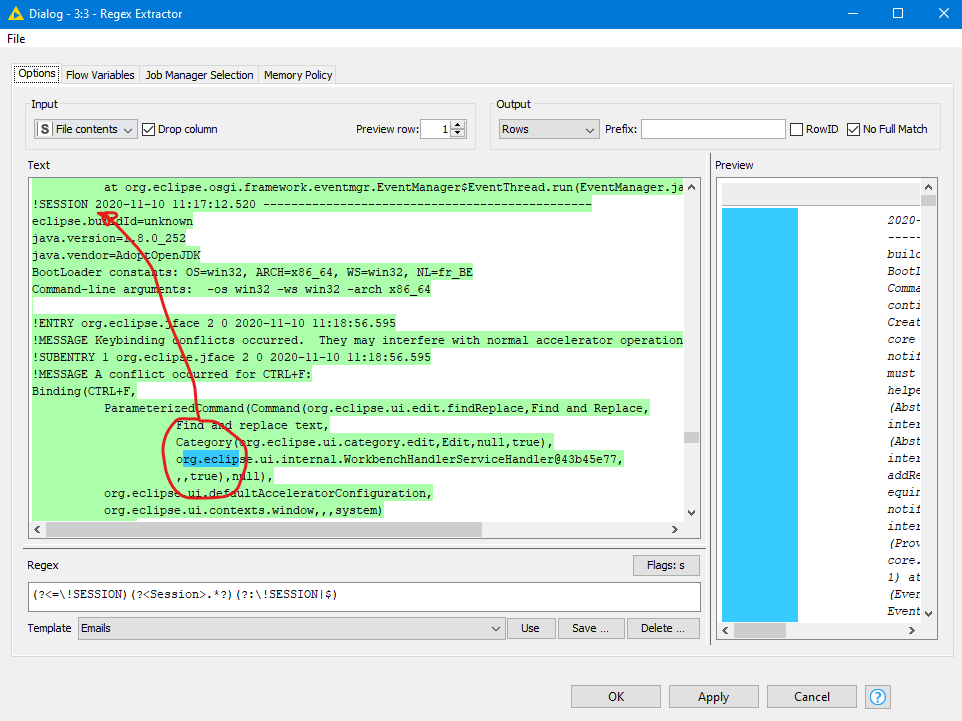
With extraction of “session” from a log file (enclosed file) ,“Regex Extractor” take a long time to open the configuration window and a lot of memory to parse the log file and the configuration window doesn’t show correctly the parsed groups (see the red arrow in the snapshot)…
Generally, the Regex Extractor is not intended for huge texts. This is more a limitation of regular expressions in general (and specifically the kind of regular expression which you use – some expressions are “cheaper” to evaluate than others).
We have a timeout built in to avoid locking up the UI with “expensive” REs and/or long texts.
Still, I would like to take the time to investigate if there’s something to improve on our end. Could you please post an example workflow which shows this issue?
I send you the workflow and data related (file “new 13.txt”) here under…
The workflow runs fine (even with larger log files at light speed )
The problem is the parsing during the configuration step (very slow to open and high memory usage even with “small” log file) but mainly the visualization of the groups (not at the right place as shown in the original message).

 )
)