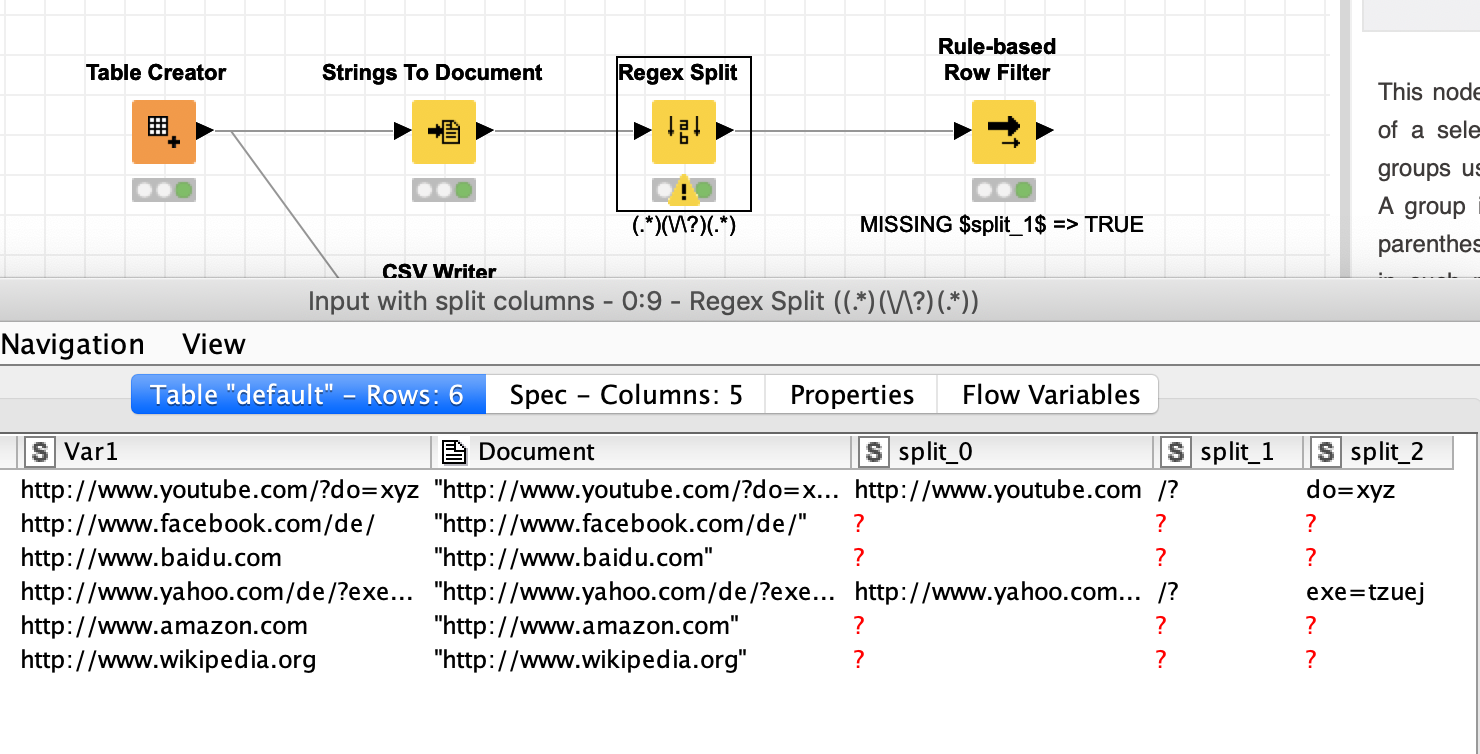
I am new to KNIME as well as to REGEX, but I am fighting my way through. I need help though, because this dirves me crazy and I do not know where my mistake is:
I have 5 Mio. urls in a csv uploaded
I want to filter out all urls that contain parameters that can be identified by containing /?
I came up with this idea, split the columns and the ones that do split are the ones you want. I tried it with the RegEx Filter and Documents but the filter does not work the way I would expect it to work.