can anybody give me some hints to solve my little (?) regex problem . . .
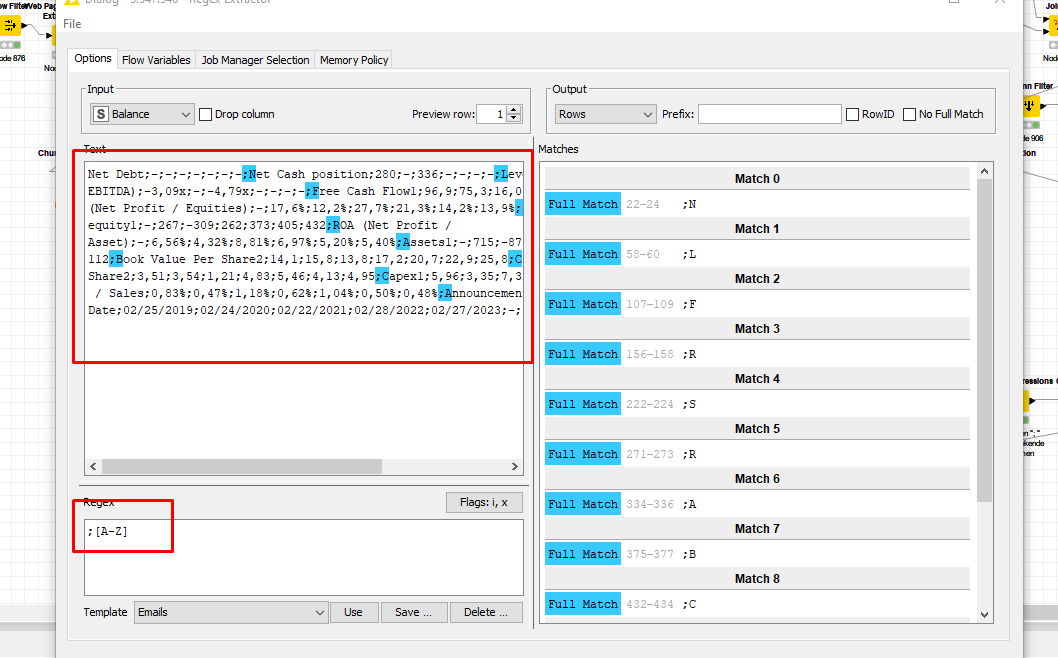
I have a string like this: Net Debt;-;-;-;-;-;-;-;Net Cash position;280;-;336;-;-;-;-;Leverage (Debt / EBITDA);-3,09x;-;-4,79x;-;-;-;-;Free Cash Flow1;96,9;75,3;16,0;265;108;79,1;95,3;
I test the string with regex (e.g. String Manipulation node): “;[A-Z]”
So, if it matches the regex condition (e.g. “;N” or “;L” or “; F”) I want to insert a seperator e.g. “###” just before the capital N, L and F (the real dataset many capital characters)
Output must be: Net Debt;-;-;-;-;-;-;-;###Net Cash position;280;-;336;-;-;-;-;###Leverage (Debt / EBITDA);-3,09x;-;-4,79xx;-;-;-;-;###Free Cash Flow1;96,9;75,3;16,0;265;108;79,1;95,3;
I tried regexReplace but (of course) it replaces e.g. “;N” by my seperator (I must keep “;N”).
With the Regex Extractor I get an extra column with the relevant character combinations. I can take that for further manipulation but it’s a bit cumbersome
So, is there a direct method to realised my wished output?
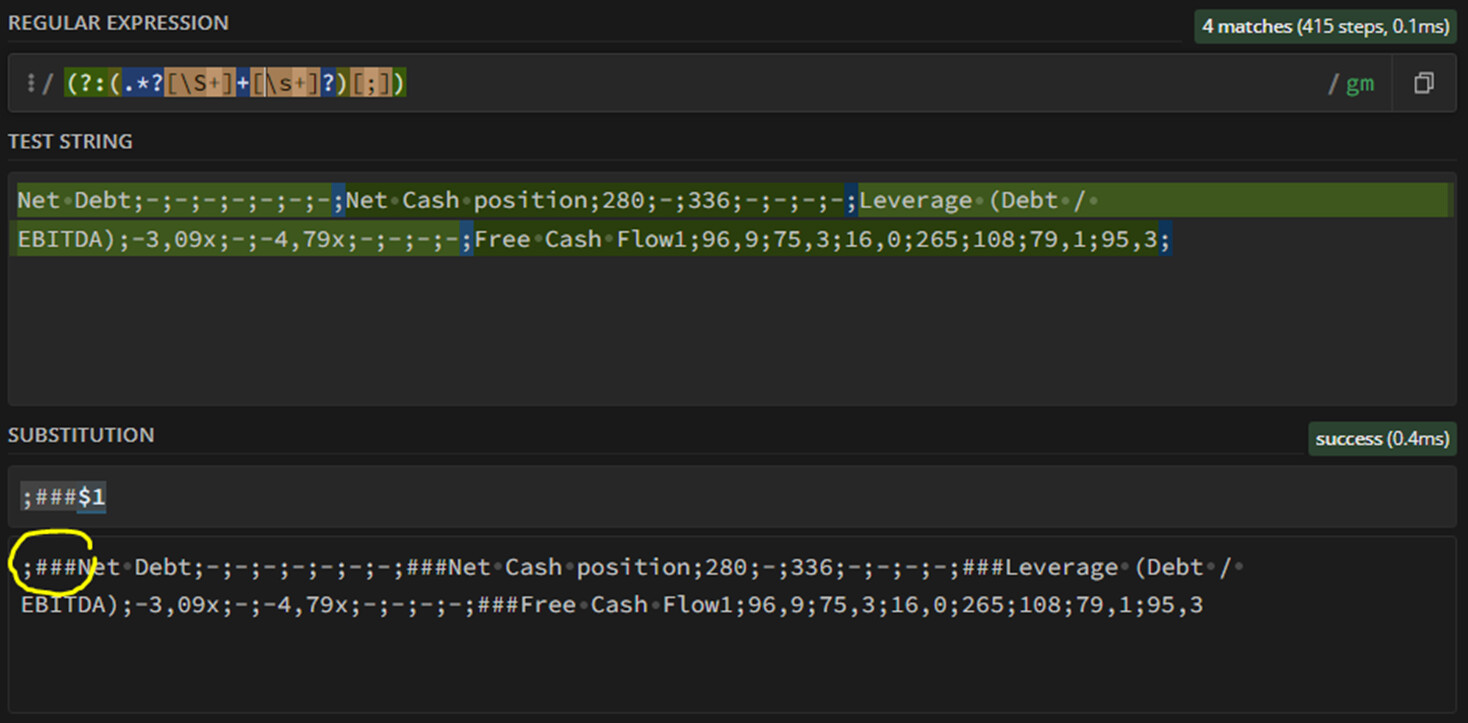
Regarding Daniels’s solution I modified it a bit regexReplace($column1$, “;([A|B|C|D|E etc …|Z])”,“###$1” ) A bit quick & dirty but as a non-programmer it covers all possible situations.
Gon’s solution is more sophisticated but the result is the same as my (quick & dirty) ABCDE . . . XYZ modification.
A little additional question . . .
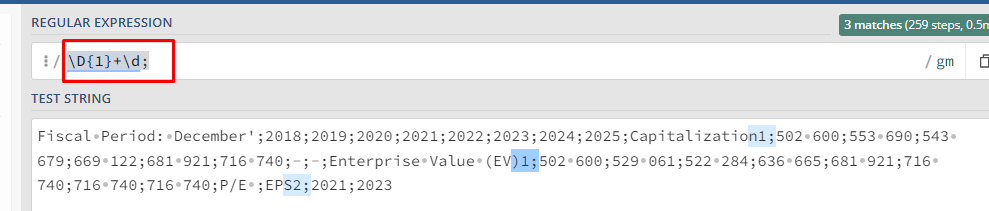
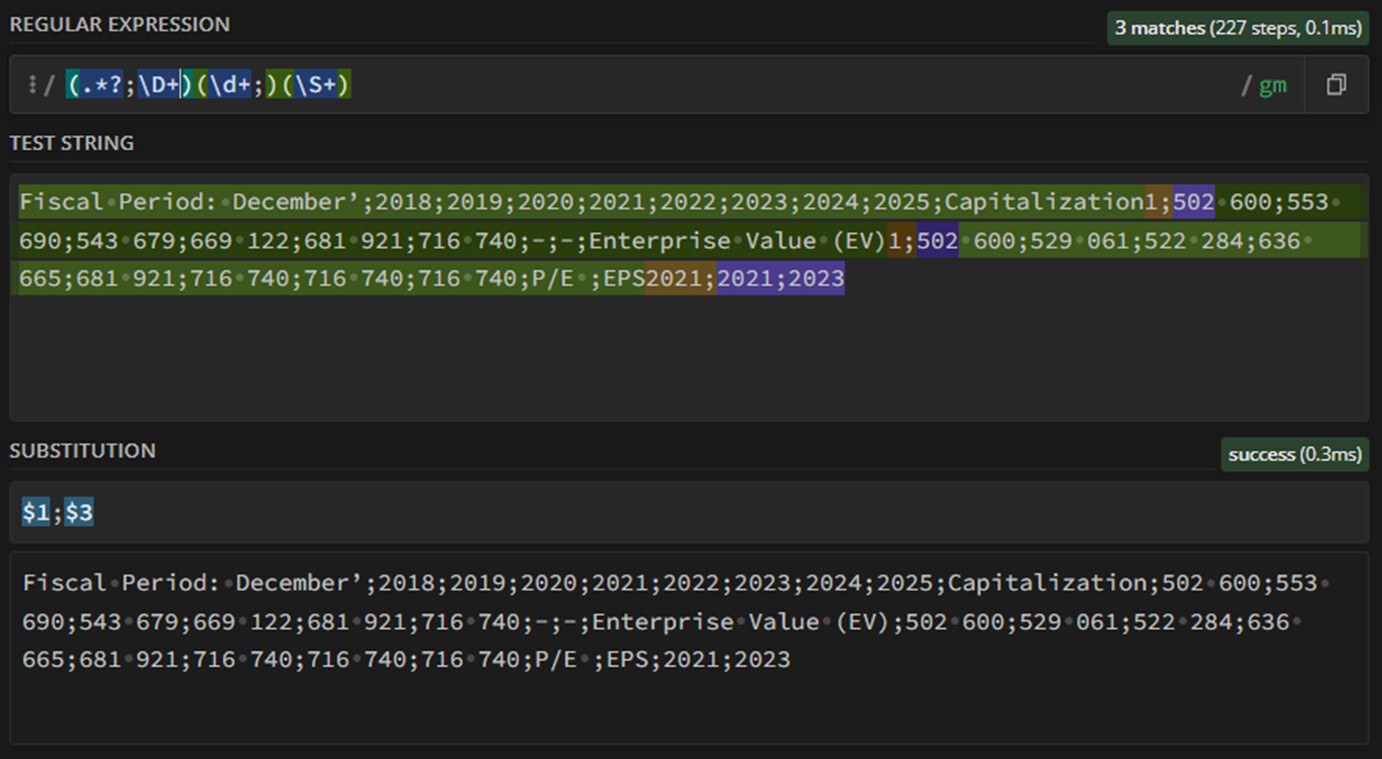
For testing Regex I use https://regex101.com/ . . . see screenshot 1. The code \D{1}+\d; matches partly what I need. However in the String Manipulation node KNIME doesn’'t find “EPS2”.
Any idea why?
To be clear, what I need exactly is that if text precedes “2;” the “2” will be removed.
The difficulty is that the string contains also values like “2022”.
So, EPS, Share and XYZ will be produced instead of EPS2, Share2 and XYZ2
Because of my lack of Regex . . . knows someone a good website or book/handout to understand (learn) Regex much better. Or is it just practice, practice and practice
Hello @sanderlenselink
The best solutions for me are the ones that i understand the better, to feel comfortable with it. So in your case it is logic your choice.
Say so and generally speaking, when growing into complexity (not the case), too much literality drives into a less robust solutions…
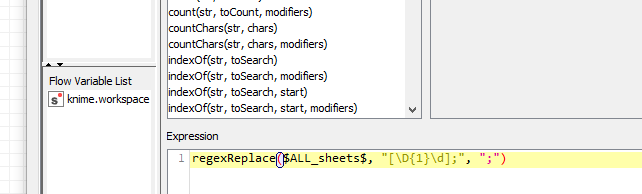
Moving into your last challenge, I’m not sure if I fully understand it. Would this coding match your expected output? You want to remove only the last digit at the end of the string. Even if there are more than one digit it has to work. Is it?
I’ve replaced EPS2 with EPS2021 as you see in the picture…
Sometimes It si more about isolate wat you want to keep $1 and $2 (middle group $2 is replaced with ‘;’); Then you need to make groups with the whole text. Once in String Manipulation, regexReplace works like intra-cell ‘split and merge’ loop function Does it make sense?
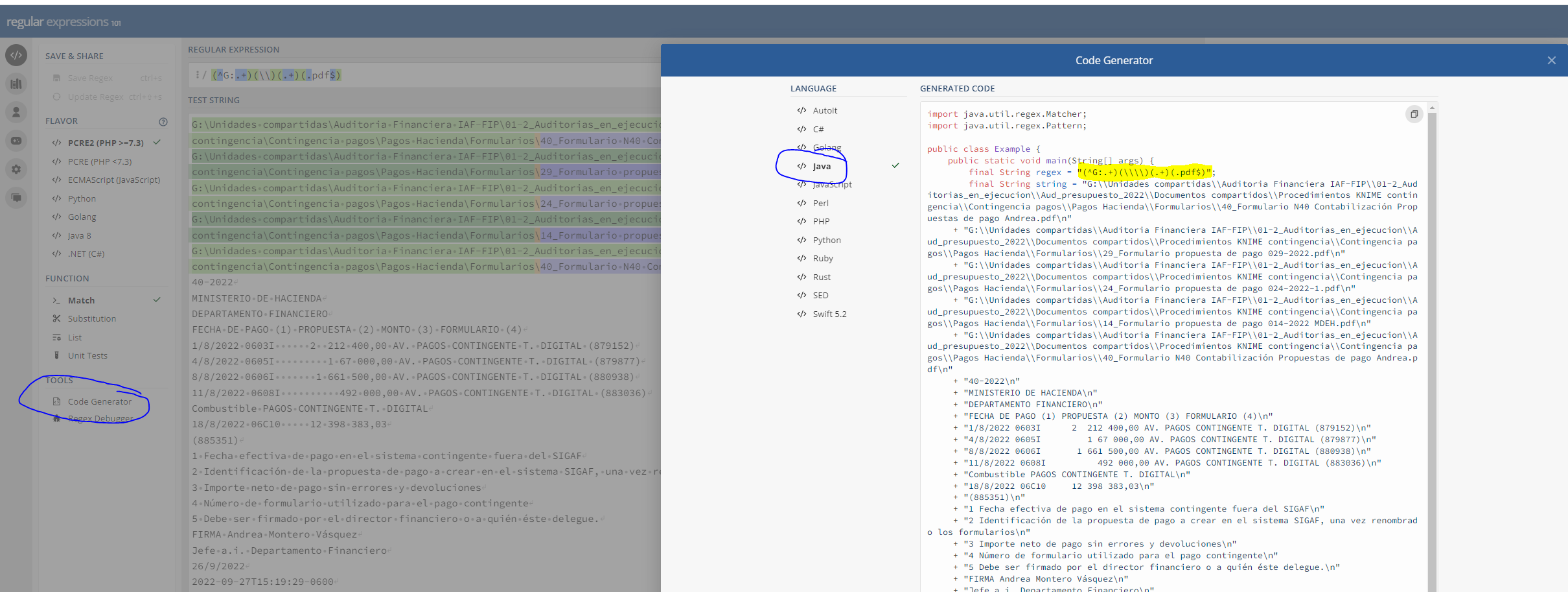
Next question is regarding the translation from regex101 to KNIME. Aiming to make it work, as you are coding java into ‘String Manipulation’ node; you need to add scape bars for the reverse slashes, otherwise they are interpreted as scape bars. The code text turns into magenta once validated within String Manipulation node; as you see in your picture, text color is in grey.
Regarding the translation, on the website you can also click on Code Generation, select Java and copy the content of final String regex. That is directly compatible with KNIME.
There is a kind of name followed by (in this example) 3 values. Sometimes (but not always) a digit is connected to the name and even a digit with parentheses. I want to get rid of those numbers and parentheses as you can see in the Target string.
I doubt whether I understand what you would like to say . . . I’m sorry
Data:
Company ACTUAL String
Period;2021;2022;2023;EPS2;15;16;16;PE;2;3;4;EV(1);500;600;700
Period;2022;2023;2024;EPS;12;16:13;EV(2);1000;2000;3000
Period;2020;2021;2022;EPS1;9;8;7;EV:300;200;100
\d+ means digitals numbers with 1 or more numbers…
\w+ means words/letters -_ with 1 oir more chars…
in your case, you have both together… \w+\d will wait some letters and numbers combined…
BUT I go a step before…
If you have this information from a file, use de CSV to bring it as columns, it can solve a lot of problems about it and you can see a specific column from a value or test it better…
OR can use the Cell splitter node to break it with the “;” as separator too…