Regex expressions in KNIME do not seem to follow the conventions such as those in regex101.com. Is there are particular “flavor” of regex used in KNIME that can be referenced?
Thanks
1 Like
Hi @acito,
For the most part I would assume that the Java implementation is used. I use regex101 quite a lot to test the regex I’ll need using in KNIME.
The main difference between what you’d type into KNIME and what you’d type on regex101 is where regex is being used in scripting nodes such as String Manipulation, Column Expressions or a Java Snippet. Here you will find you have to use double backslashes instead of single backslashes as otherwise they will be misinterpreted, but this is common to most programming languages where often you have to escape characters that would otherwise have special meaning, for example when you are trying to put the regex into a string.
Regex101 deals with the pure regex flavours but doesn’t make any allowance for how you have to enter the regex into your desired platform or programming language.
If you have any specific regex in mind that you are finding differs in the KNIME implementation, please feel free to post an example here as there may be special cases that I’m not aware of.
5 Likes
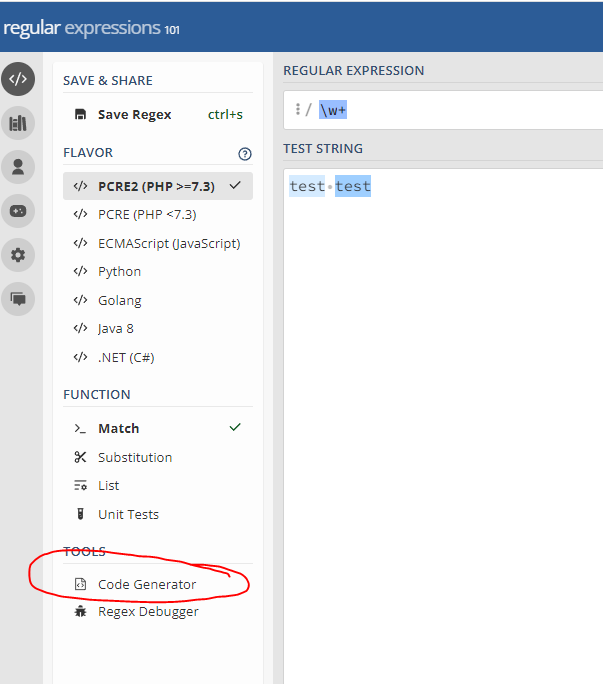
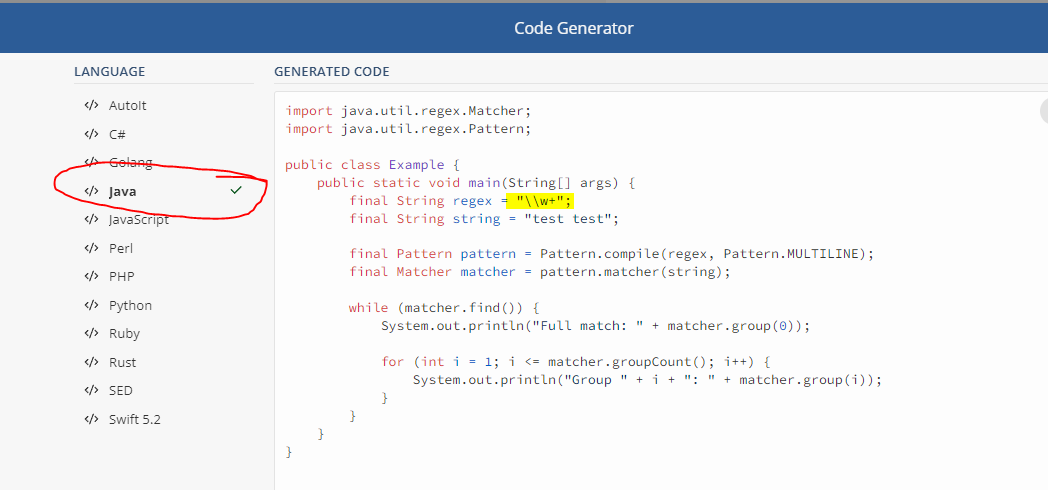
To add,
Regex101 can do this for you.
-
Enter a Regex as desired.
-
Click on Code Generator
-
In the pop-up, select Java.
-
Copy the contents of
final String regex
-
Use this in your KNIME node of choice
4 Likes
This workflow is a simple example of what works in regex101 and does not seem to work as expected in a KNIME Column Filter. I want to select only column names containing an “a”. “[^a]” works in regex101 but not Knime.
TestRegex.knwf (11.8 KB)
if you add a plus symbol it picks up the names and by the way in brackets it maches everything except columns containing a
br
1 Like
Hi @acito, I think in this case it is ascertaining what regex101.com is telling you, vs what the Column Filter is looking for that is the issue.
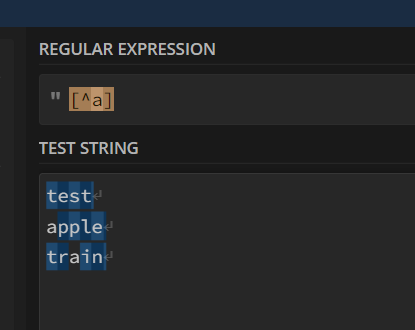
This screenshot from regex101 is saying that [^a] is indeed matching individual characters within the string, but it isn’t saying that the whole string matches the pattern.
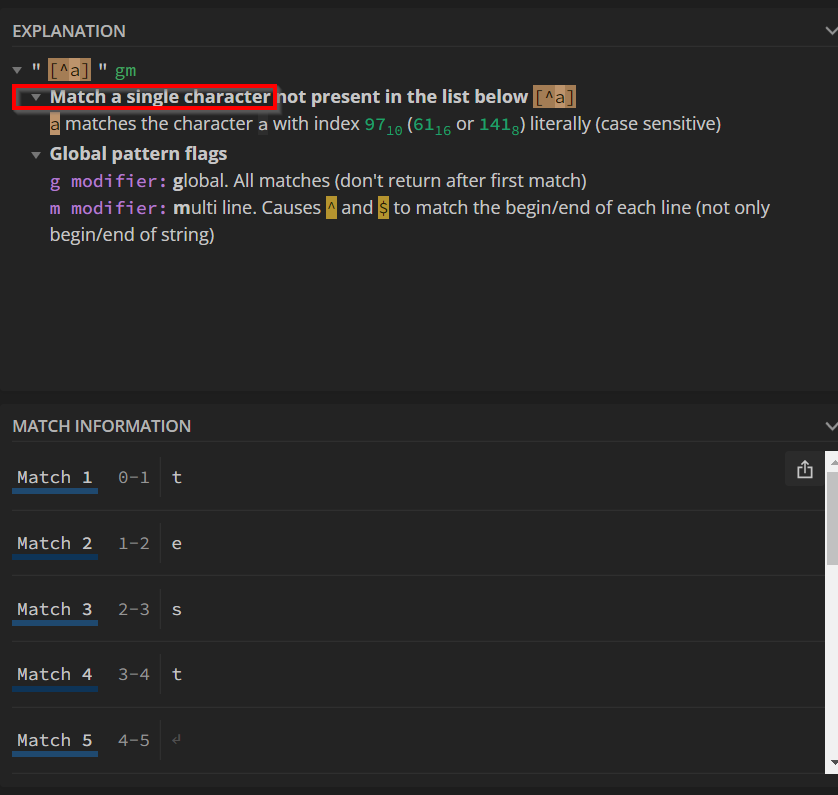
So [^a] would match to a column with a single-character-name that isn’t “a”
e.g.
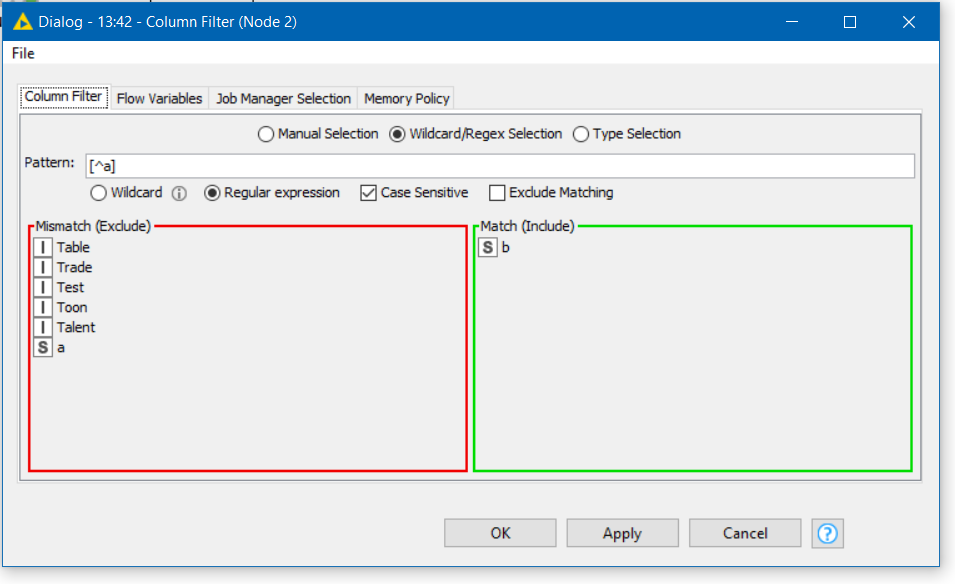
whereas by placing the + after, as @Daniel_Weikert mentions, this is now saying that the column name consists of any number of characters, none of which are “a”.
And you can see the subtle difference in what regex101displays. It is now highlighting “test” in totality rather than as individual letters.
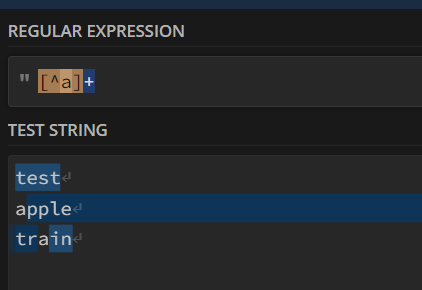

I can understand the confusion, and the “fun” with regex here is probably not so much which “flavour” it is using, but what the intended meaning is in any given usage. In java regex, the pattern [^a] without any + or * modifiers matches “b” but it doesn’t match “bb” because it is trying to match with a string consisting of only a single character that isn’t “a”.
The column filter is trying to match the entire column name with the regex pattern, however I think there are some places in KNIME where there is a different context and possibly return a match if the string contains any substring which matches the regex.
2 Likes
Thank you very much! I have been writing a book on analytics using KNIME and wanted to include an appendix with examples using regex, but I could not figure out how to reconcile KNIME’s version with regex101. Your explanation helps a great deal.
Frank
1 Like
I checked the Column Rename (Regex) and it works like Java regex. Strange.
Frank
Hi @acito
I see what you are saying and yes the Column Rename (regex) works on finding substrings that match the specified regex. So this is an example where the context of what the node is looking for is different to the Column Filter.
I don’t think it is “java” vs “not java” regex, but more a case of knowing which nodes use regex patterns to match against entire strings (e.g. whole column name as in the Column Filter), and which is trying to match against substrings (e.g. substring of the column name as in the Column Rename (Regex).
That is probably the list you need.
I can see why those two nodes might be coded to look at it from different perspectives although it could perhaps be argued that the decision is a little arbitrary.
In the case of Column Rename (regex), you’d probably want to search for substrings because the purpose is often to replace only a part of the Column name rather than the entire column name.
For the Column Filter, I feel it could probably be argued either way. Maybe the decision was that people would most likely be filtering whole column names, and if it matched substrings they’d be forced to keep adding ^ and $ on the end, or something like that. I’m just randomly guessing here; I don’t know whether it was an active decision for them to be different…
…but I look forward to reading your book! ![]()
2 Likes
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.