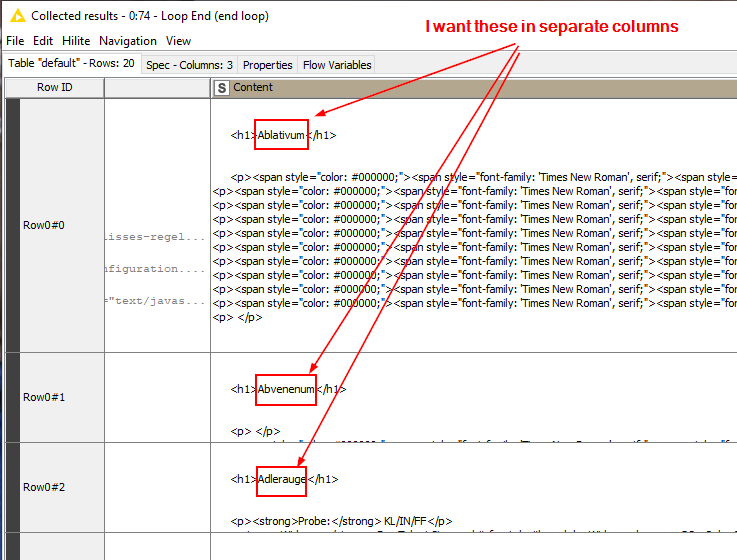
I have selected a few lines of data through webscraping (see screenshot). Now I want to extract certain HTML entitities and I though regex would be the appropriate way here. I chose Regex Split Node because the HTML extract I have crawled is badly coded, sometimes you have a paragraph before a certain tag, sometimes you don’t. So I thought regex would be the appropriate way here.
The regex I developed should basically take everything after the opening <h1> tag and before the closing </h1> tag and put it into a separate column. The regex I created (using regex101) is this
(<h1>)(.*)(<\/h1>)
but it throws an error.
I assume it has to do with whitespace and multiline (I checked the multiline checkbox in the Regex Split Node).
ps. By the way, if the regex creates more split columns, I don’t really mind because I could easily delete them afterwards with a Column Filter Node.
Hi it probably creates more split columns because you do not catch all the data in the column (e.g. everything after the closing h1 tag)
maybe you can also post the error message.
bR
Instead of the Regex Split Node I used the Regex Extractor Node from the Palladian extension package.
I just split the column by the word (term) that appears in every occurrence. Then I deleted the unnecessary split column and “finetuned” the remaining column with the String Manipulation Node and the regexReplace function to get rid of all the html tags.
To do that (if anyone is interested) I used the following regular expression
alternatively you can use following regex in Regex Split or in regexReplace() function (in String Manipulation or Column Expressions node) to do the job: