Hi aseeber,
this is a perfect case for the brand new Regex Extractor node in Palladian 2.0 – especially if you’re used to more intuitive tools such as Regex101 you’ll feel right at home. See here for the announcement:
You can find an example workflow on NodePit: regex-split-question-20968 — NodePit
Here’s the node configuration for your data:
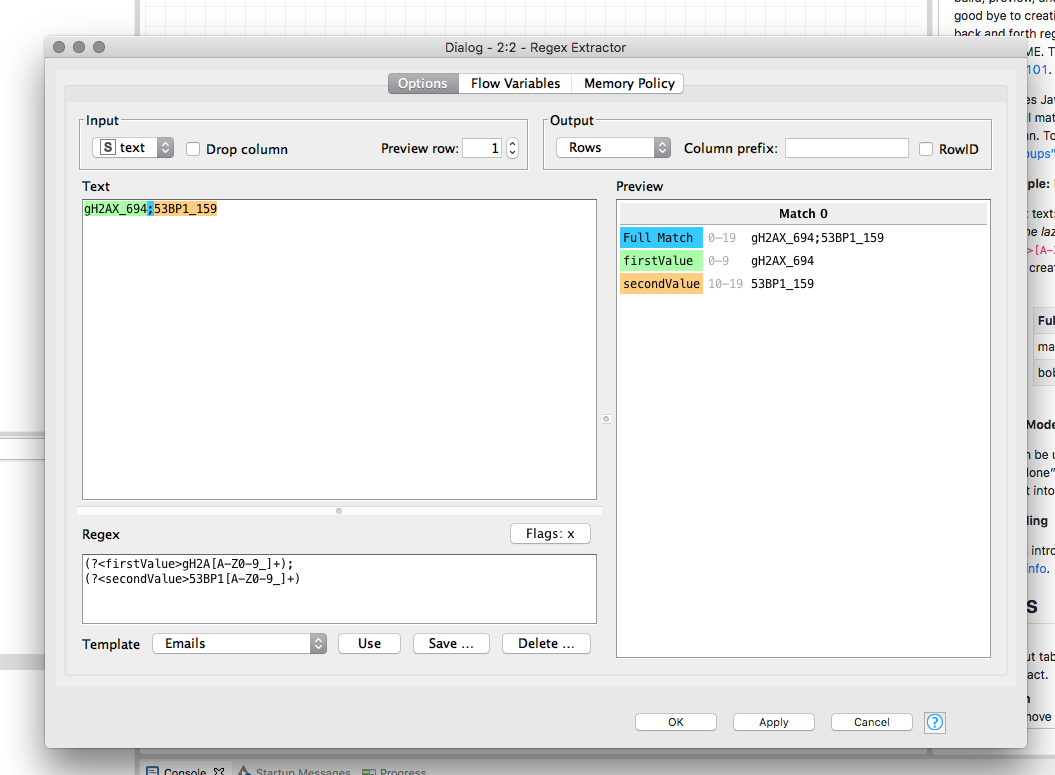
I used the following regex:
(?<firstValue>gH2A[A-Z0-9_]+);
(?<secondValue>53BP1[A-Z0-9_]+)
It uses the “named capture groups“ firstValue and secondValue which give the name of the output columns. Any way, when editing the expression you’ll always see a preview of the results as you’re used to from Regex101.
Any feedback welcome!
– Philipp
PS: An alternative approach could be to define a “tokenization expression”. This makes sense, if you have a variable number of items separated with a ;
(?:\w+|[^;]+)
It will basically create a match for each value between the semicolon:
