Hi @J_Knime_Work ,
From your list, the regular expression “a” will only match “a”. It won’t match “apple” because it contains other characters.
When I tried this on regex101.com, it showed the regular expression “a” as matching only the “a” in “apple”, and not the entire string. Since it doesn’t match the entire string, regexMatcher will also return false for your other strings.
A regular expression to match “a plus other characters” would be “a.*”.
With reference to your first example, where you expected matching results for “[^a-zA-Z0-9]” to be as follows:
“This field 1234” → false
“This - field” → true
Your statement is incorrect.
– That regular expression is looking for a string that is a single character that is not alphanumeric. Therefore it will return false because neither of those strings matches that pattern. (i.e. they are both multi character strings, and they also both contain spaces, which aren’t alphanumeric.)
To find strings that ARE alphanumeric (and include spaces), you could use the following:
[a-zA-Z0-9 ]+
which would return true for the first and false for the second.
To return true where the string contains at least one character not in the required set, you could write logic (e.g. with an If statement) in Column Expressions to return the opposite.
or you could use the following:
regexMatcher(column("column1"),".*[^a-zA-Z0-9 ].*")
which returns true if the string consists of any number of characters (including zero characters) followed by a character that is not in the required range, followed by any number of characters. This would return true if the string is anything other than “AlphaNumeric or Spaces”
In terms of chatGPT being “adamant”… it is never adamant about anything  and it can and will often make mistakes. It probably depends on the specific wording of the question posed to it, and of course its response is based entirely on statistical analysis of its training model, so whilst it is a very useful guide, it is not guaranteed to be factually accurate and can often “hallucinate”.
and it can and will often make mistakes. It probably depends on the specific wording of the question posed to it, and of course its response is based entirely on statistical analysis of its training model, so whilst it is a very useful guide, it is not guaranteed to be factually accurate and can often “hallucinate”.
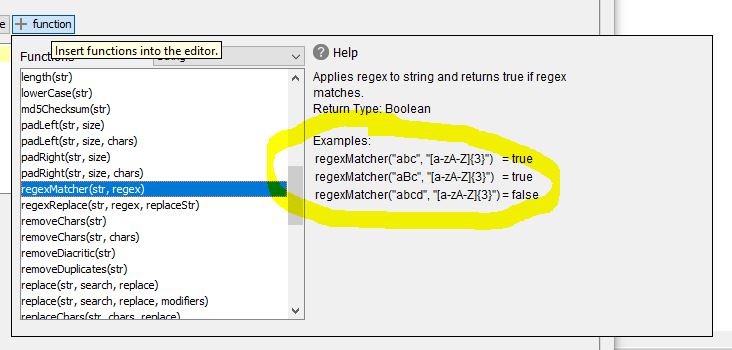
For regular expression matching though, the whole point is that you write a regular expression to match the entire string. I would be disappointed if I wrote a regex match expecting a string sequence to match [A-Z]{3} (i.e. exactly 3 capital letters) and discovered that it also considered ABCD to be a match for that simply because it found 3 capital letters somewhere in the string.
Regular expression matching is different from regular expression replacement. With regex replacement, tools may replace subsets of regular expressions found within a string, and therefore not have to match the entire string.