Hi there,
I am trying to fit a regression model in knime. I have several questions for you. I am very confused.
My model have independent values of:
-Vehicle Type: Categorical(5 category)
-Company Type: Categorical(6 category)
-Volume: Numerical
Dependent value is:
-Unloading time per volume unit (Numerical, EXPONENTİAL Distribution)
I may use random forest etc. but my priority is getting a polynomial regression with coefficients. And I have these questions for you
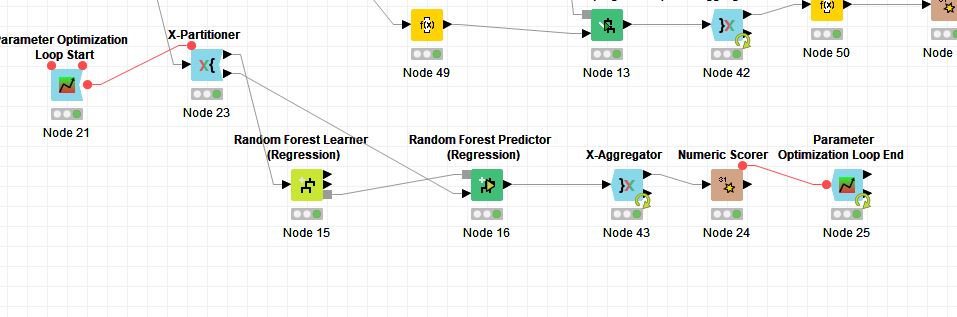
1-I used X-partitioner for partition, and at the end I want to see model coefficients of aggregated data. But I think if I right click on Polynomial Regression Learner node, it only shows the last partition coefficients, not the aggregated model. How can I get the coefficients of the aggregated model, is it possible?
2-My dependent variable is distributed with an exponential distribution. Shall I transform it using LOG transformation, the MATH modules are for that task in the image.
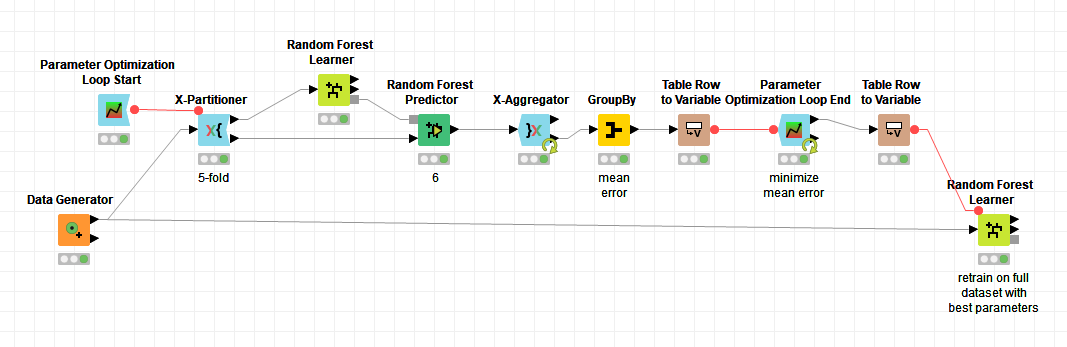
3- Also I have problems with parameter optimization and x-partitioner. I want to optimize parameters of random forest but x-partitioner recursion interferes with loop I think. It always says “Wrong Loop Start Node Connected” or “Can’t merge flowvariable stacks(likely a loop problem)” according to orientation of variable ports.
4-) Moreover, even if the 3rd one works, there is a big question. Parameter optimization must increase variables after x-partition complete 10 partitions.
In summary, after 10th partition ends, parameter optimization node shall be triggered.
Actually, x-aggregator sends it back to beginnning each time, and do not let flow continue till last partition I think. But optimization start node is a problem, where and how shall I place it?
Thanks for your help, have a nice day
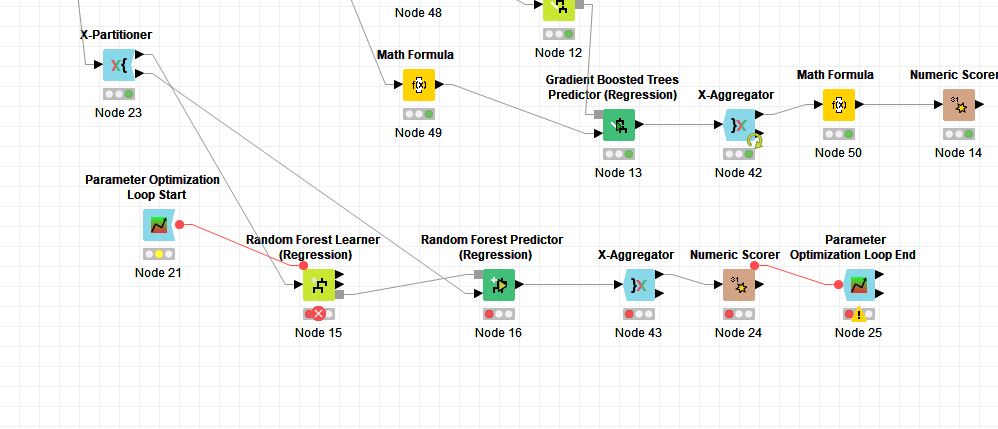

Thanks for your help