Hi Team,
I am trying to do monthly volume forecast by customer with kind of regression models by using historical monthly vol (2022-07 ~ 2023.12). The model test and predict result is: R^2 is 0.8-0.9 but MAPE is always 0.56-0.9. However, when i implemented the trained model with new data (2024-01), the predicted volume vs 2024-01 actual volume has quite huge gap, which is not acceptable.
I have preprocessed my historical data to get customer monthly volume, past one month, past 2 month, past 3 month till past 6 month vol, also get past 1 year vol. Besides, i sum holiday# per month as an impacted feature
I am not sure where i can improve and how i can improve my model. Can anyone have such experience to improve my model accuracy.
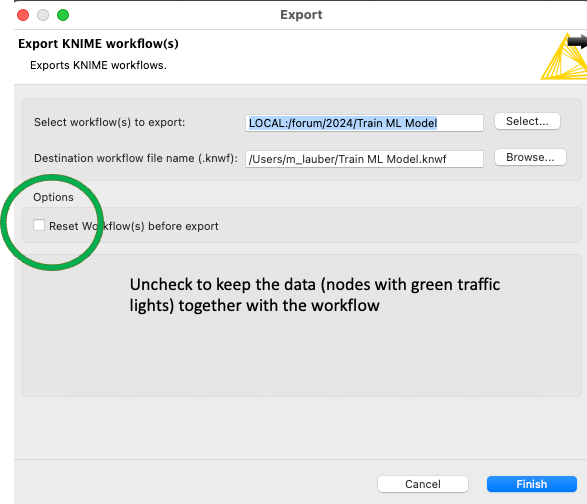
@Joey666 you sample workflow does not contain any data. Maybe you can save it again with the data in a /data/ subfolder or when saving it uncheck the Reset option:
Thanks a lot for your guidance ! I have reexported the workflow without reset. But when i am going to upload here, it is saying the flow is over it’s max size (4M), anything i can do to successfully upload to community?
Thanks for sharing this. i have question how i can save this workflow to my local space? when i drag to my local workspace, seems the flow is not shown there still.
Also, regarding the partitioning, it is a must to use partitioning to split data to train& test data set in a ML model? can i use row splitter node to split test/train data if i have to choose some specific data as a test data (actually i managed to split exact same data with Row Splitter and Partitioning, but the scorer shows very strange result if i use row splitter to split data)
Thanks for your guidance on downloading workflow. I have question about Data split for test and train data below. Could you pls help me ? Thanks so much
Also, regarding the partitioning, it is a must to use partitioning to split data to train& test data set in a ML model? can i use row splitter node to split test/train data if i have to choose some specific data as a test data (actually i managed to split exact same data with Row Splitter and Partitioning, but the scorer shows very strange result if i use row splitter to split data)
[/quote]
I don’t know anything about your dataset, i.e. how balanced it is. I would recommend that you use the Partitioning node. Using the row splitter can result in unintended “data drift.” If your data is very unbalanced check out resources such as SMOTE to manage it.