I’m pretty new to KNIME and not a coder at all. I started using it because Excel just couldn’t handle the size of my data, mainly doing Excel-like transformations and some basic automation.
Initially, I used the ‘Missing Values’ node to copy down ID number numbers, which worked. However, a new dataset with invalid data in an ID number field required me to split the data into two tables for cleanup.
Now, I’m having trouble rejoining these tables. The Joiner node won’t allow me to use the original RowIDs (due to potential duplicates, which do not exist as the data was originally a single table). Creating new RowIDs changes the original row order, which is necessary for the ‘Missing Values’ copy down operation.
Is there a means to rejoin these tables while maintaining the original row order? Any suggestions would be greatly appreciated or any advice on how to better do the data cleanse so I am not faced with this issue would be amazing.
I assume the “ID number field” was generated by you and is not the KNIME RowID. If so it may be possible to correct the problem in your original table. Without knowing the specific nature of the issue, its difficult to offer advice.
@WL_Loqbox welcome to the KNIME forum. You could take a look at this example how to preserve RowIDs when joining. But you will have to come up with a concept/idea what a unique ID will mean and how you can handle them. If you use the joiner to join 1:1 you have the option to keep the RowIDs if they are identical and unique in both tables.
Hi @WL_Loqbox , if I am having to split my data into separate tables and then reassemble it later, maintaining the original row order, I usually throw in a Counter Generation node before splitting, so that each row contains a sequential number. After all the transformations and manipulations, and I’ve brought the rows back together into a single table, I then sort on the Counter column that was generated at the beginning.
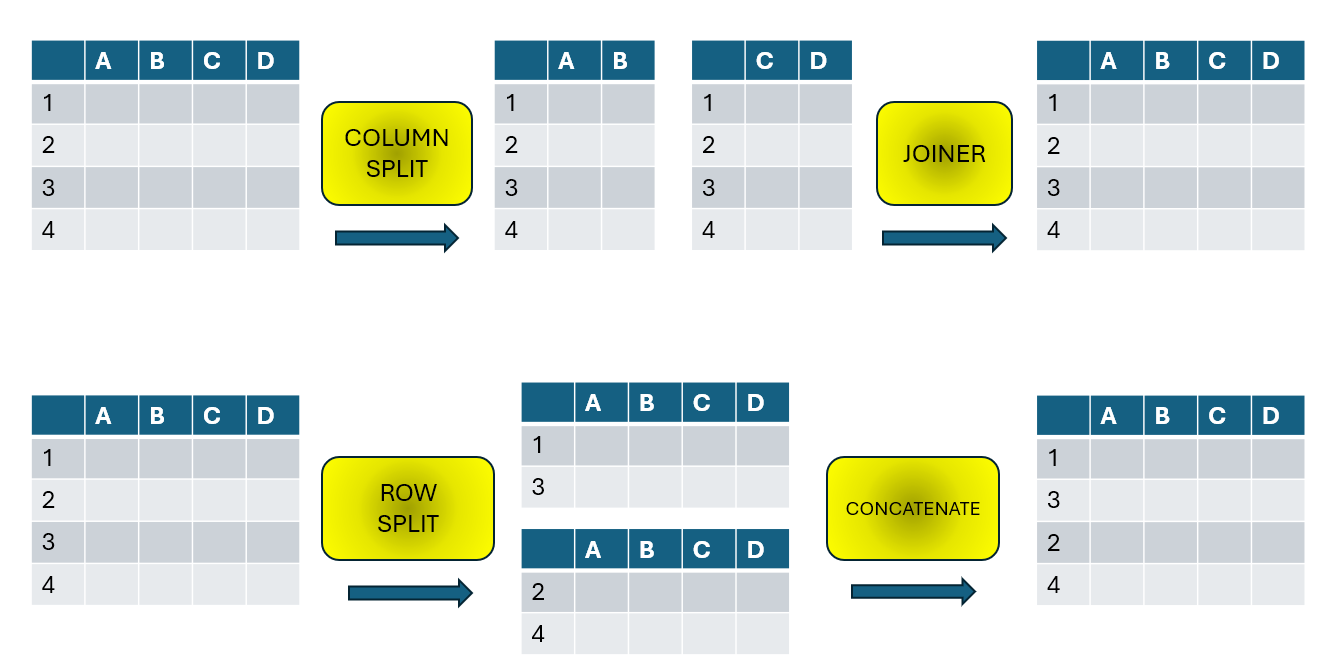
By the way, did you mean Joiner or Concatenate for “joining” your data back together? In general Joiner re-assembles data where the tables being joined each contain “matching rows” and each has a subset of the columns required in the final table, whereas Concatenate assembles data where the tables being concatenated each contain a subset of the rows required in the final table, but contain all of the columns. Just checking my understanding, as from your initial description I was expecting that you’d split the original data into two subsets of the rows (rather than columns) for the data cleanse activity.
If you are still stuck, and have a small sample workflow that can give a better understanding (demonstration) of exactly what you are doing, feel free to upload it, but make sure it contains no sensitive data. It’s often best to put together a small mockup with demo data, as this makes it easier for people to give specific help.
Also I suspected that Joiner wasn’t the right one but being someone who operates primarily in Excel I would not have thought concatenate be the one to use.