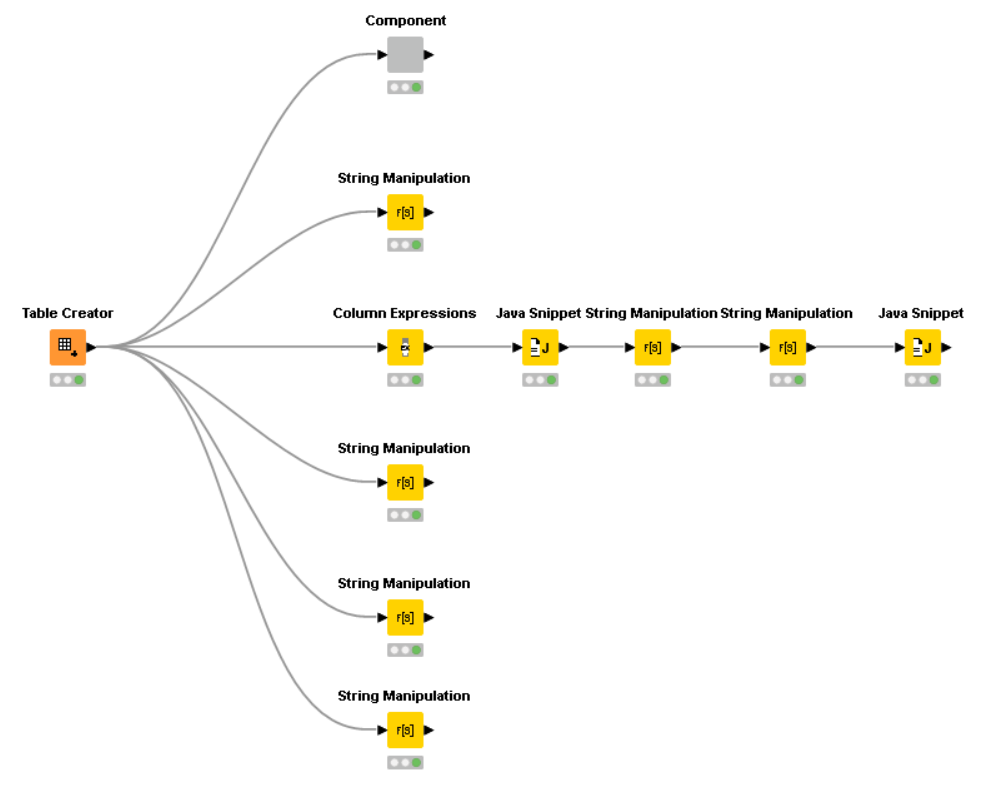
Hi, I’m trying all six regex or nonregex methods I know of from the forum. I am trying to remove all the substrings that start with a backslash. The simple ones like \n is of course possible but for the longer ones, let alone being written next to one another without spaces, are difficult. Please have a look:
Other than the methods above, I also came up with the thought to enlist them, then to remove them using rules or cell replacers - or something to that effect. Considering most of them are of 6 characters including the backslash, I tried:
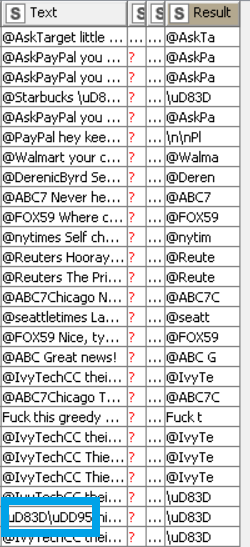
which, as you can see, only worked for the first occurrence. It also has an undesired effect, whereby for cells that don’t have any, it will return the first few characters!
Anyone can share tips to improve this concept further? Or a totally different workaround altogether?
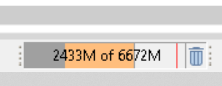
I tried to take the Strings to Document route today, where I created a Bag of Words to then follow up with Cell Replacer. But going even halfway of this route takes that much memory (orange in color). And this is for a new session (which doesn’t include the memory usage from downstream & upstream tasks).
As the usage of \n\n appears to be consistently, it should work out but a sample of 10 rows is only so much. Maybe some other cases are uncaptured but should be manageable with additional OR statements.
That sounds great! I’m trying it out now, will update here. Meanwhile, can you explain the multiple backslashes in the script? I notice that there is a \b in there too, which although I never used it, but based on what I’ve read on the forum on other people’s posts, it’s for boundary right? What’s the difference between putting just one \b (like you did here) and putting two of them (like the ones I’ve read on the other forum posts)?
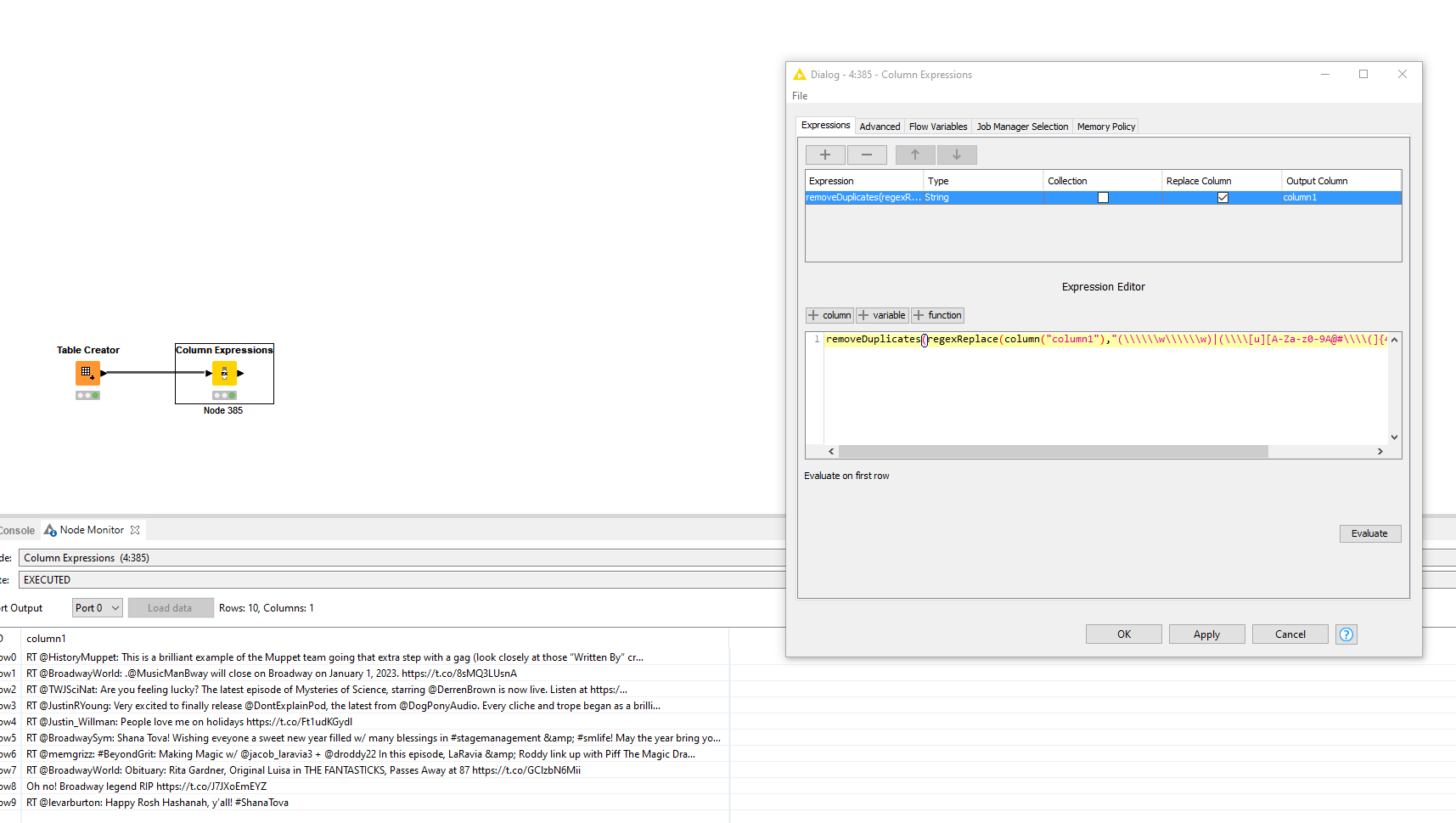
Update: I’m getting this error when applying the script:
ERROR at line 65
The method column(java.lang.String) is undefined for the type Expression26
Line : 64 public java.lang.String internalEvaluate() throws Abort {
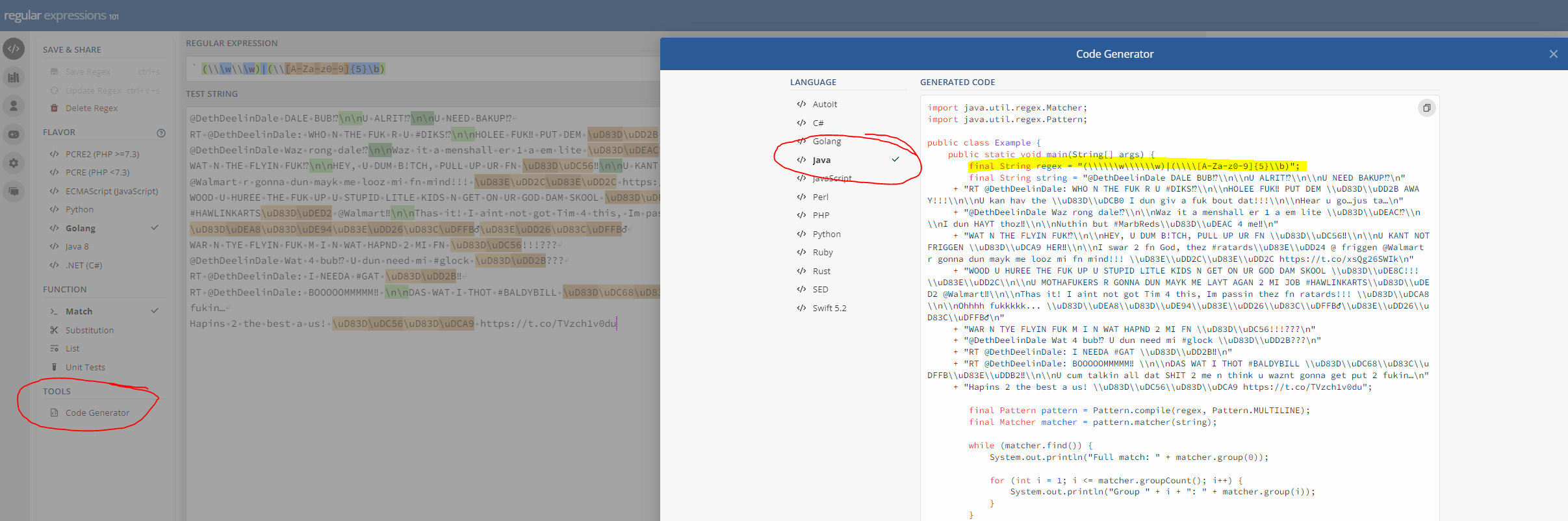
Line : 65 return removeDuplicates(regexReplace(column(“Column0”),“(\\\w\\\w)|(\\[A-Za-z0-9]{5}\b)”," "));
In KNIME, you have to escape certain special chars of which the slash is one of them. Hence all the slashes to escape \w, and \
See the Regex in action here:
To get the KNIME equivalent of this Regex, click on Code Generation, select Java and copy the final String regex from the code block and paste it in whichever node you’re using.
@ArjenEX Thanks for this attempt. It seems that the script works in Column Expressions but not in String Manipulation, but that’s fine with me. It’s just that it’s weird why that happens.
Anyway, I would like to adopt this solution since I’ve tested it on my real dataset and it seems to be working. I like that it’s a one-node solution and it’s a straightforward automatic task.
But I just have to optimize one more thing. Can you modify it a lil bit such that it also detects the unicode substrings that were attached to a non-unicode? In the dummy workflow, I guess this example wasn’t included, hence your script did not detect this. Here’s an example:
And here’s the new dummy dataset: CleanUp.knwf (9.5 KB)
Other than starting with alphanumeric characters, the non-unicode word may also start with these 3 characters: ( @ #
(the examples for @ and # are not included in this new dataset as I’m having difficulties to locate the examples due to large volume of text.)