Hi all, I am working with multiple files, and I need to first remove the duplicate values of each file and next merge them into a CSV file. How should I do? Thanks.
Hi @soon_98 and welcome to the KNIME community
You are not giving details on your problem and the casuistic can be very broad like:
- i have repeated files in the same folder (mounting path) with different names
- i have repeated file names in different folders (mounting paths)
- i have repeated files with different names in different folders
- …
then the work approach may be completely different.
For the most simple case same files in a folder, ‘String Manipulation’ node to remove the final brakets of repetition (1), (2)… and then a ‘Group By’ node will do the job for you.
For more details please provide a dummy file list with paths that represents your problem, and we will be able to provide a more accurate help.
Regards
2 Likes
Hi,
Actually there are duplicate values in each fie and I have total of 40000++ files need to work with, it will be time wasting if I need to remove the duplicate value of each data one by one before merging them. Besides, the size of file is too big, it will be trouble if I need to combine all the data first before removing the duplicate values. Is there any other solution?
Thanks and Regards.
Well, this is my view: the point of using KNIME is to bring data to be analysed in KNIME, so basically the workflow would be read all the files in a loop and aggregate the transformed data by collecting all at the end of the loop…
If the problem you are describing doesn’t fit or scale in this type of approach, I would rather code it in R (Py… optional); where you can access or bring the information without opening the files. Then if you still want to run some processing in KNIME, you can do both: import your processed data in a unique file or run the R Script from KNIME.
Hi,
You can read all the csv files with the “CSV Reader” node and then use “Duplicate Row Filter” node
regards
Andrej
2 Likes
Hello Soon_98,
Do your files have the same columns ? For all of them ?
If so, you just could :
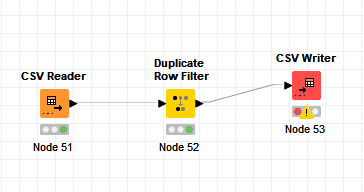
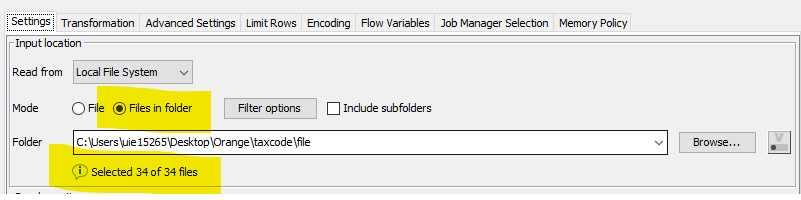
- load your CSV files with “CSV Reader” node from folder, it will compile them as one
- remove duplicate with the “Duplicate Row Filter”
- write your compiled file with “CSV Writer” node (check ss below)
Best Regards,
Samir
3 Likes
Hi, it works well. Thank you so much for your help.
2 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.