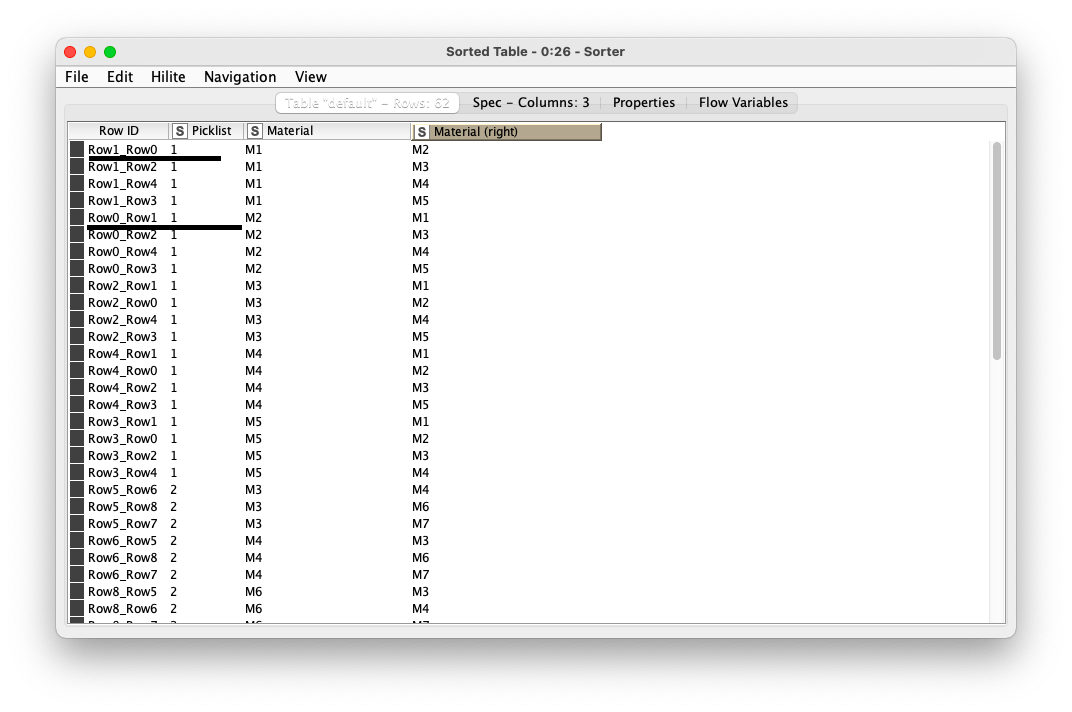
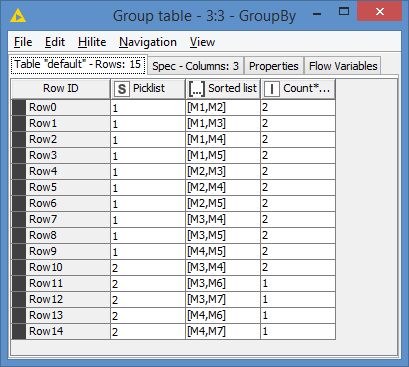
I have two columns in a table, the first is the pick list ID, the second the material column.
I would like to anyhow count how many times was the materials pairs on common picking list?
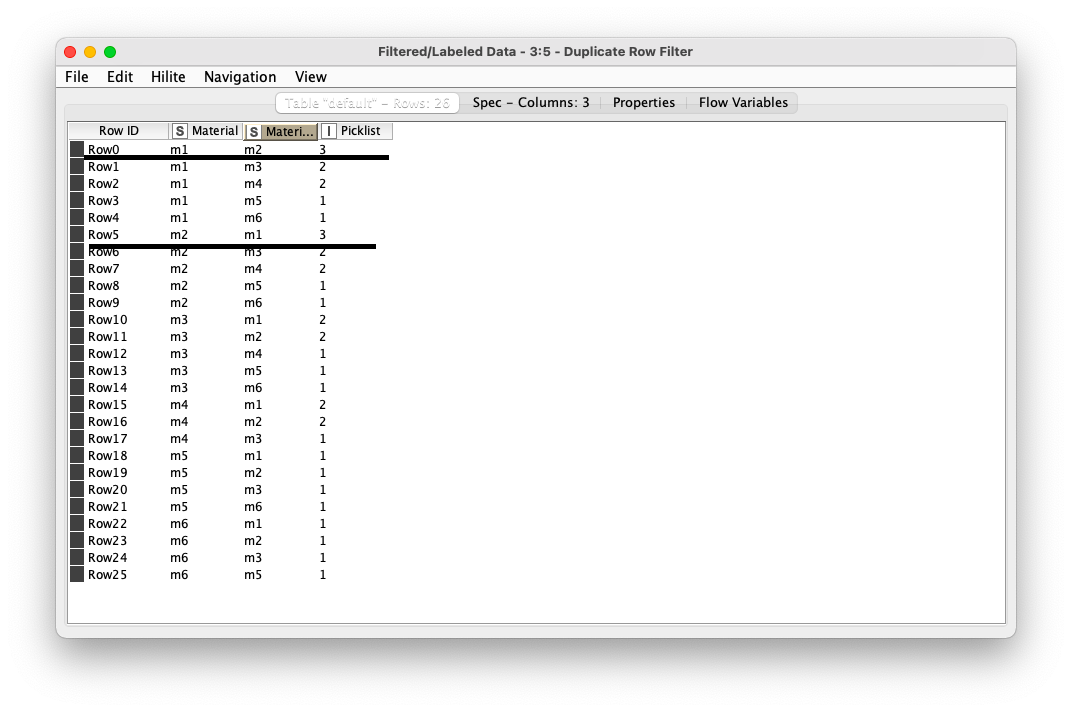
I could generated the material pairs, I would like to remove duplicates, for example, the underlined rowIDs mean the same:
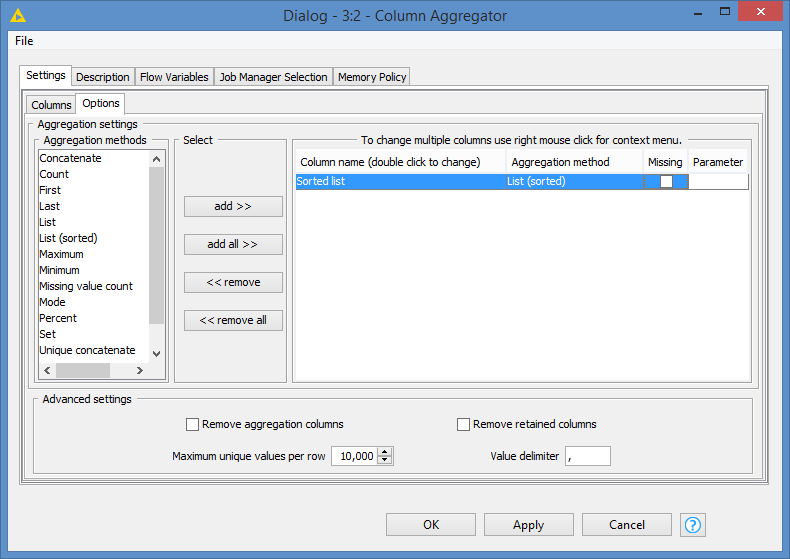
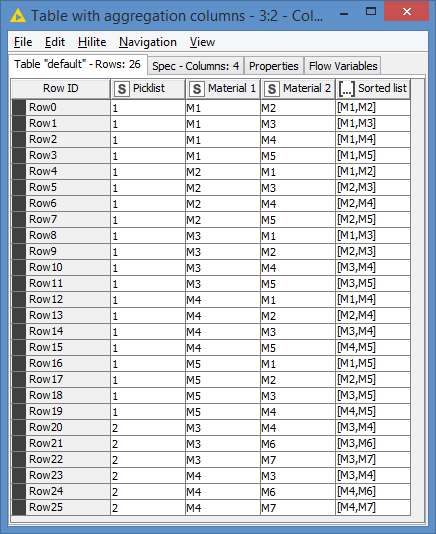
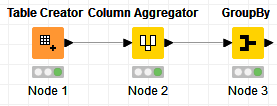
For counting use GroupBy node, group by key columns, and in aggregation tab add count on some other column.
For removing duplicates there is Remove Duplicates node.