Hi @kennywp, it depends on whether the “rules” remain constant with different data.
If I can assume that the file name part of the path always starts with a number followed by a period and potentially one or more whitespace, and then you want to capture everything after that, then this could work:
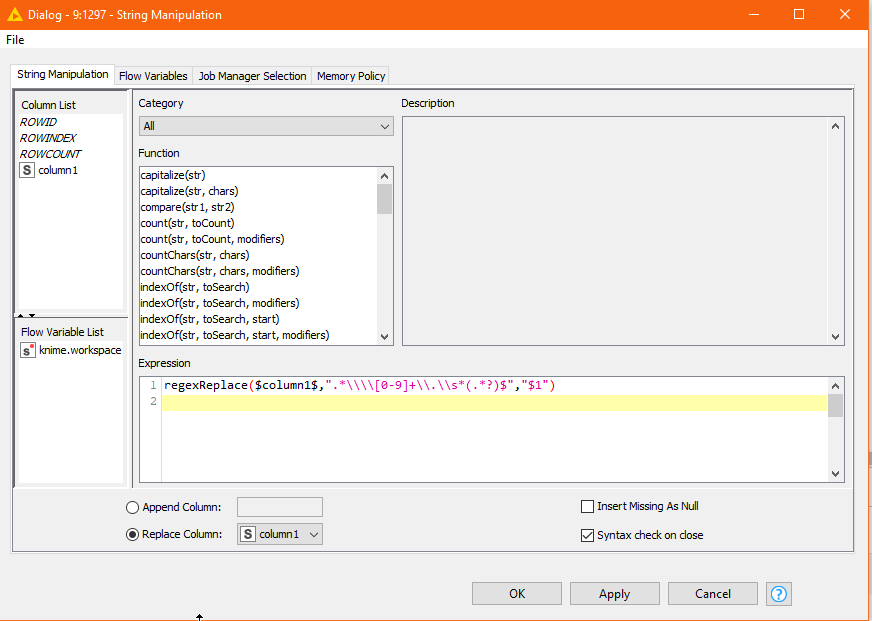
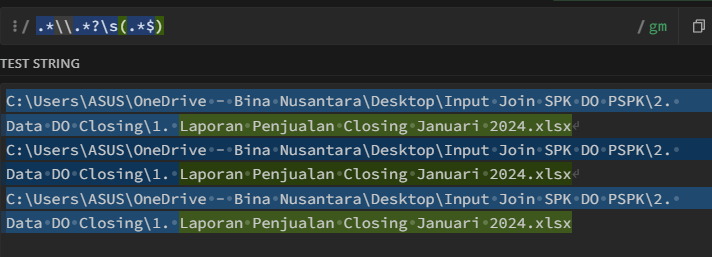
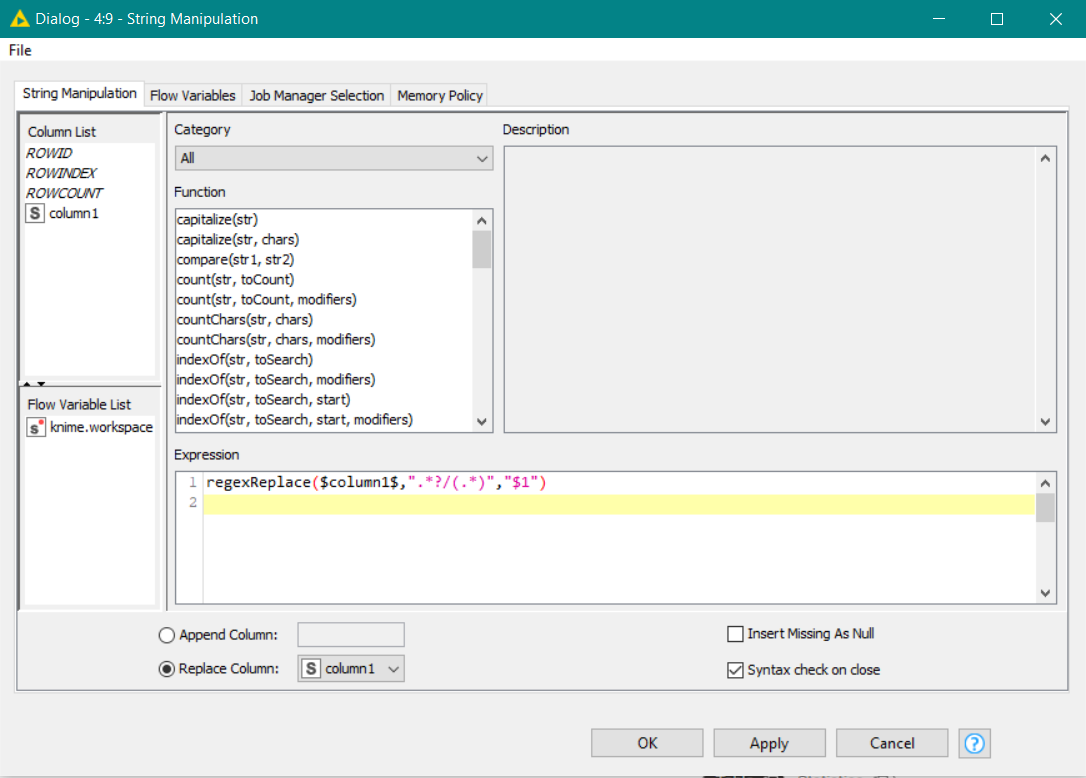
regexReplace($column1$,".*\\\\[0-9]+\\.\\s*(.*$?)","$1")
The actual regex pattern to match (without additional “escaping backslashes” required by String Manipulation) would look like this:
.*\\[0-9]+\.\s*(.*?)$
which means:
| regex pattern |
written in String Manipulation as |
meaning |
.* |
|
any number of characters (“greedy” as many as can be consumed while still matching overall pattern) |
|
|
followed by |
\\ |
\\\\ |
a single backslash |
|
|
followed by |
[0-9]+ |
|
one or more digits |
|
|
followed by |
\. |
\\. |
a period |
|
|
followed by |
\s* |
\\s* |
any number (or no) whitespace characters |
|
|
followed by |
( |
|
capture group 1 |
.*? |
|
Any number of characters (? = “(non-greedy) as few as can be consumed that still matches overall pattern”) |
) |
|
end of capture group 1 |
|
|
followed by |
$ |
|
end of string |
This then gets replaced by “$1” which means the text found in the first “capture group”
You will see that in the regex pattern given to String Manipulation, every \ in the actual regex needs to be prefixed by an additional \, in order for it to be interpreted correctly and passed on to regex by the node.
Alternatively, if it is always from “Laporan” onwards, after the final backslash, you could use this:
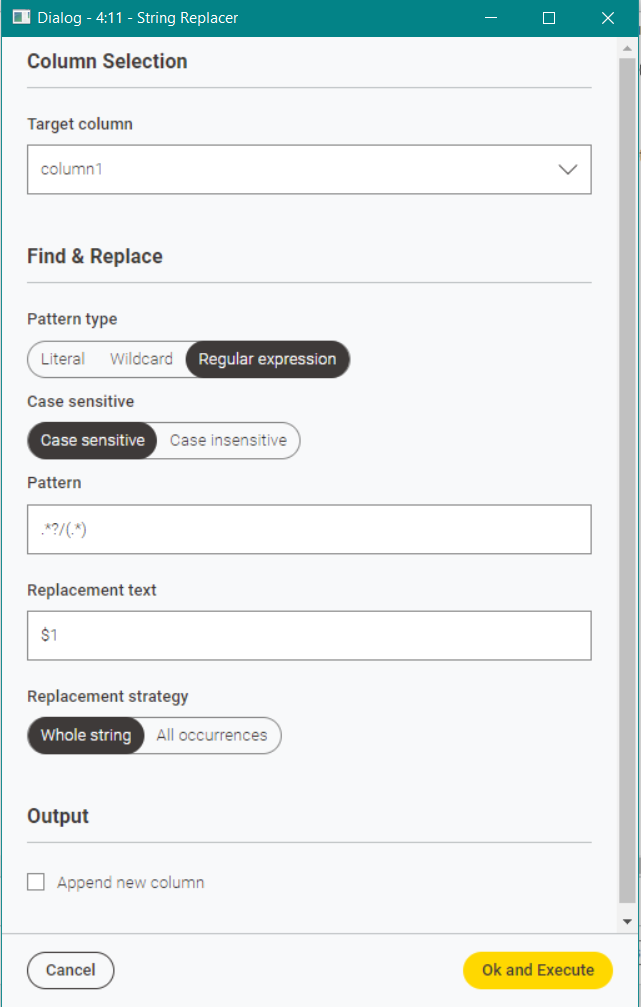
regexReplace($column1$,".*\\\\[0-9]+\\..*(Laporan.*?)$","$1")
or to capture from the first occurrence of “Laporan” onwards, regardless of backslashes:
regexReplace($column1$,".*?(Laporan.*)$","$1")
or from the last occurrence (change which “.*” is “non-greedy”, by moving the “?” )
regexReplace($column1$,".*(Laporan.*?)$","$1")