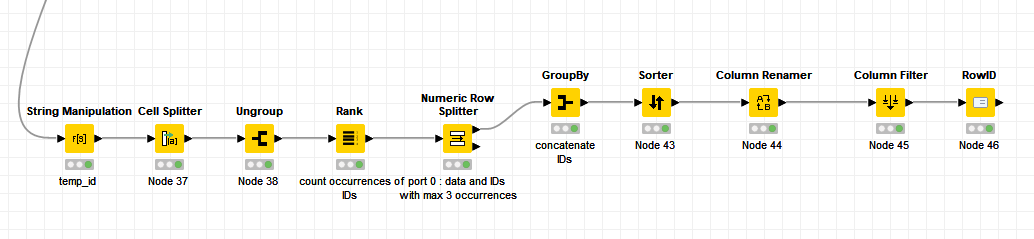
Hi, I’m really confused on how loops work here or if I even need a loop to get the output I need.
I have a column that has delimited values of IDs, sample:
row IDs
1 one1;two2;three3;four4;five5
2 one1;three3;four4;five5;six6
3 one1;seven7;four4;eight8;nine9
4 one1;two2;three3;nine9
5 one1;two2;four4;ten10
I want my output to be:
row IDs
1 one1;two2;three3;four4;five5
2 one1;three3;four4;five5;six6
3 one1;seven7;four4;eight8;nine9
4 two2;three3;nine9 --------------------------> removed one1
5 two2;ten10 --------------------------> removed one1 & four4
My goal is to have only 3 at max occurrences of an ID for all of the rows of the data table.
Help me please!
#loops #ruleengine