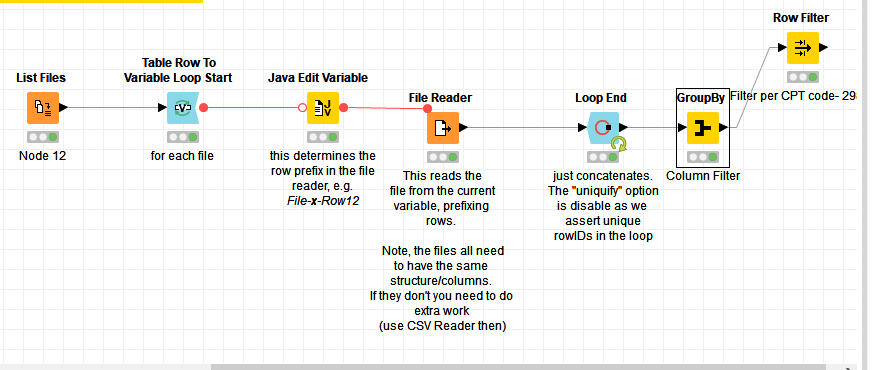
Hello, Everyone
Yesterday I posted about needing to join 12 files together to create one large file, my question is this:
I am aware of what the statistics Node can do, is there a way that before connecting to this node, set up a node to remove all the outliers from the data? Say the top and bottom 25% for any given statistical category then have the Statistics Node run off the “Middle” 50%?
I ask because the data set has so many outliers that any stats derived from it are not accurate. My Objective here is to produce a reasonable price for a procedure given past payment data the has a wide range of prices.
Here is my current workflow -