I am trying to remove all beginning rows from a column. All rows must be removed until there’s a specific string (I already have the regex set for it and I have already found it on the rows), I have also used the Lag Column Node according to this post , however in the same post it also says to use the Rule-Based Row-Filter which I am confused how can I use that in my case.
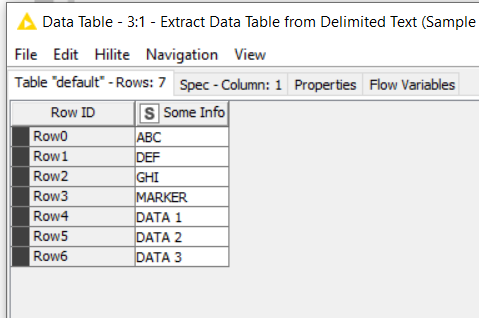
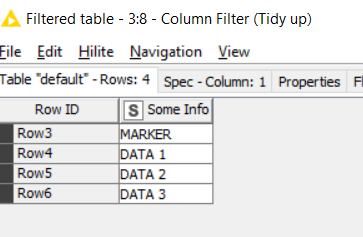
I guess I may need a loop that stops based on a certain condition lets say, if “Column1” is < true > & “Column1(-1)” is < false > then STOP. In the example below I would like the row removal to stop at the first hostname row (not counting that row) I am not sure how to make that happen.
Column0
Column1
Column1(-1)
:
false
false
: Serial Number: ABCDEF
false
false
: Hardware: 8192 MB RAM, CPU 2400 MHz, 1 CPU (8 cores)
false
false
: Written by enable_18 at 09:51:45.292 EST Tue Nov 8 2022
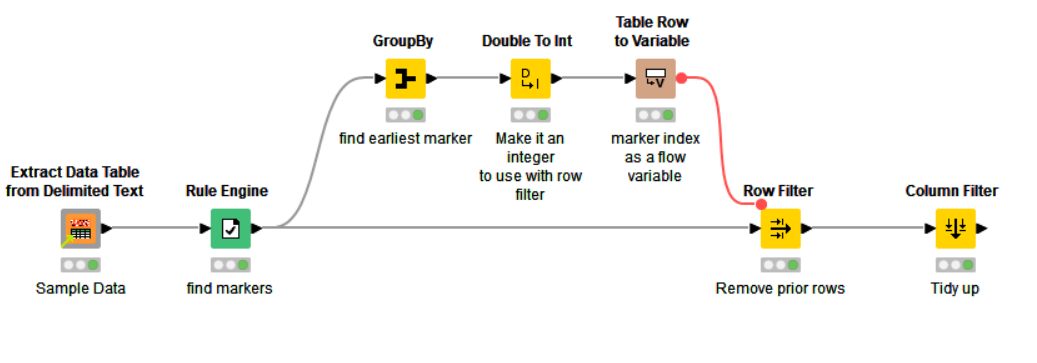
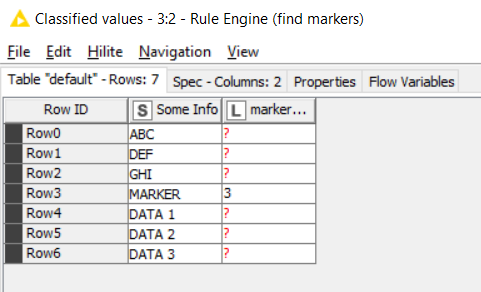
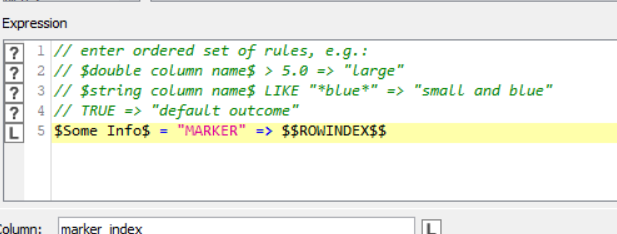
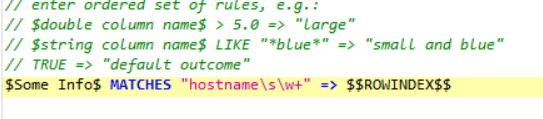
Use a Rule Engine to create a column setting the value to the Rowindex whenever the “marker” string appears in your source column.
Then find the lowest rowindex that has been found.
Put that into a flow variable and pass it to a Row Filter filtering by row number, as the first row to keep.
Be careful to note that in the Rule Engine, rowindex starts at zero, whilst the config of Row Filter uses 1 as the first row number, so there may be times when you need to adjust the number up by 1 with a Math Formula if it is a problem.
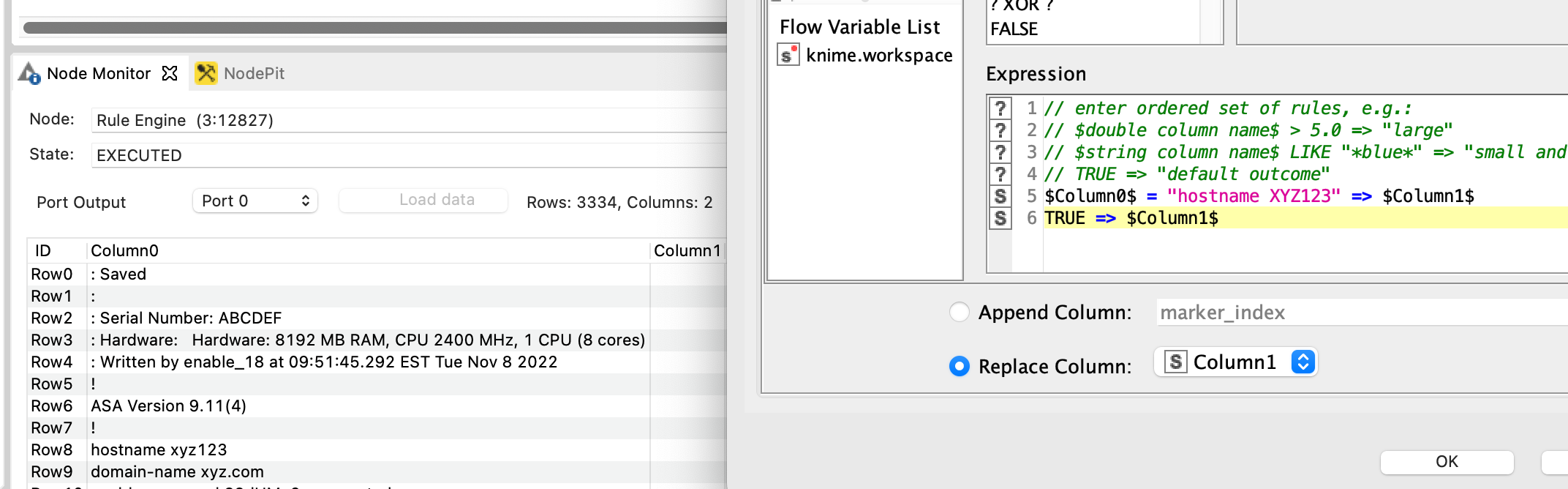
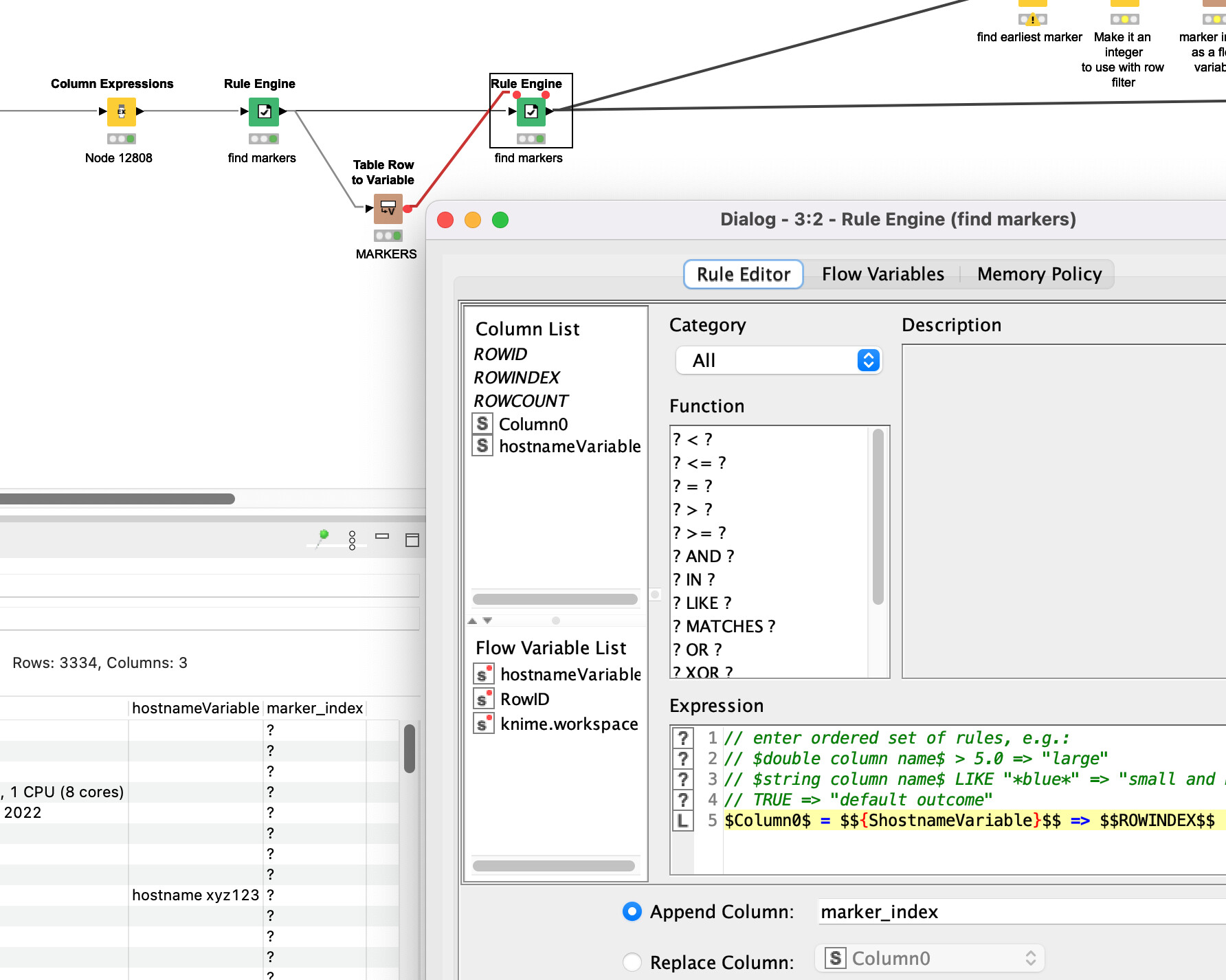
Thanks for helping me. The value you set on your example on the ‘Rule Engine’ ie: MARKER, will constantly change on mine, so I decided to create a variable there, output to a new column, and from there, start the new rule engine importing that variable just created. However, I cannot seem to be able to output the ‘hostname xyz123’ of my example to the Column1.
Hi @jarviscampbell , yes it is case-sensitive so it will need to be the lower case variant, but your rule, if you are following my example should by outputting ROWINDEX for the matching value
e.g. my example
Or am I misunderstanding what you are doing at this point?
No, @takbb I don’t think you understood me. My idea is to first, create a variable, on the first ‘Rule Engine’, the variable will output in this case < hostname xyz123 >.
On the next Rule Engine, the one like yours, instead of MARKER, I will add the newly created variable on the previous step, does that make better sense?
Ok, I may still not be understanding what you are doing. (I understand the kind of problem, but maybe I’m not understanding the approach) because it seems to me that you are still hard-coding the value that you are going to be using as the “marker”, and there is no difference here to simply hardcoding it in the second rule engine. But you may have a plan, and I may be wrong
But anyway what that rule says is this:
If value of Column0 is “hostname xyz123” then output the value of Column0
Otherwise output the current value of Column1
and because it says at the bottom “replace column Column1”, the value that is output from this rule will be put in Column1
I’m getting slightly lost, without being able to really see the workflow and the data.
OK taking a step back, the first rule engine you have added is going to create a column called Column1 and currently it will attempt to put a value in every row based on the rules given.
But you are wanting to then create a variable. Unfortunately you can’t simply create a single variable in the way that I think you want, that is based on that column’s data.
This is maybe where I am not understanding what you are doing here because I don’t know what value you are expecting the variable to contain? You could have 100 rows, but the variable will simply contain the value of row1, unless you can aggregate the column’s data down to a single value…
EDIT: You could add a group by on Column1 and collect the concatenation of all rows, ignoring missing values, if that is maybe what you are thinking? Then the Table Row to variable would work, if applied to that?
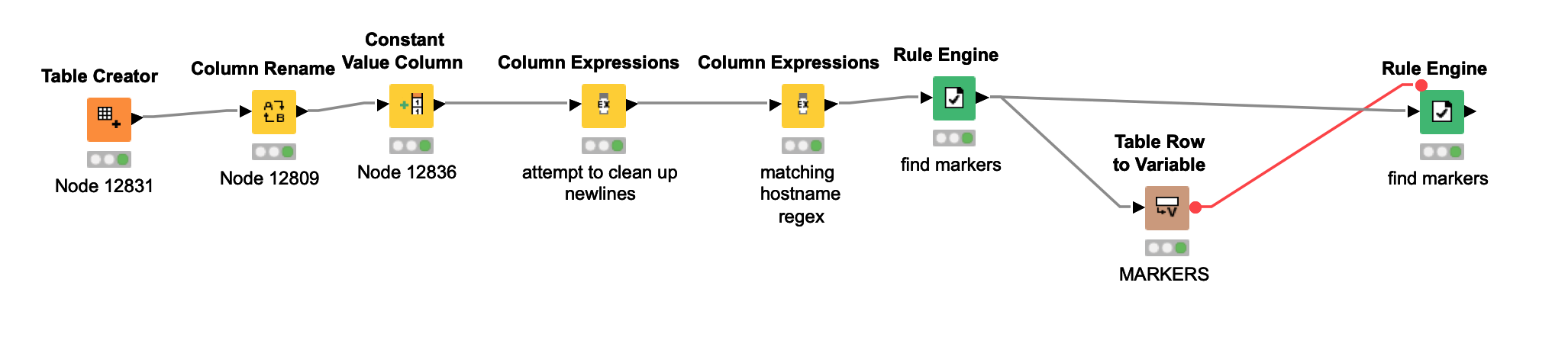
Hi @takbb , sorry it took a little bit, I’ve created a table and pasted in some rows from excel. Then it created a \n or a \r at the end, I spent sometime trying to clean it up but was not able to, hence you’ll see a couple prior steps for that.
I am also adding a spreadsheet w the end solution.
As you can see on the spreadsheet, the intent is to eliminate anything prior to the when I find the regex that will match the < hostname xyz >
Then after that, I will have a table w strings as variables, these strings are what will the ‘keywords’ that initiate the lines. I need to break it into chunks and position in each column. Now, everything else that is not in the keyword variable list, will be discarded.
As you can see, a lot of the data within chunks do repeat themselves. That’s okay. They all must be together.
Another tips about it is that some of the code has I believe, not sure if they’re tabs in the beginning, it’s an indentation at least. That makes them sort of a ‘block’, but they all must stay together in the chunk as shown per column in the spreadsheet. Does that make sense now? I asked about the beginning, I know, but I guess the continuation may be sort of the same, or not. Idk. Thanks a lo.
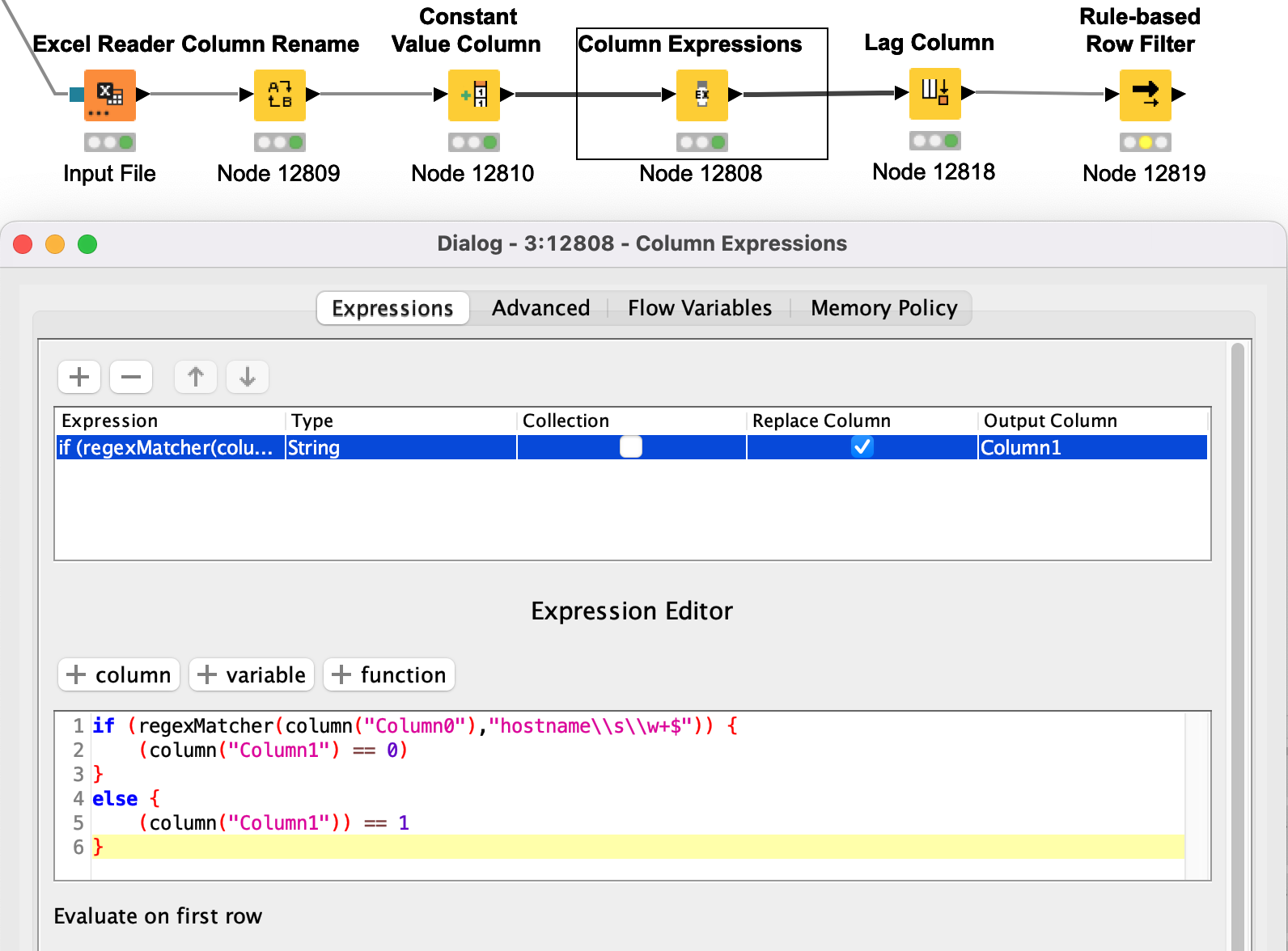
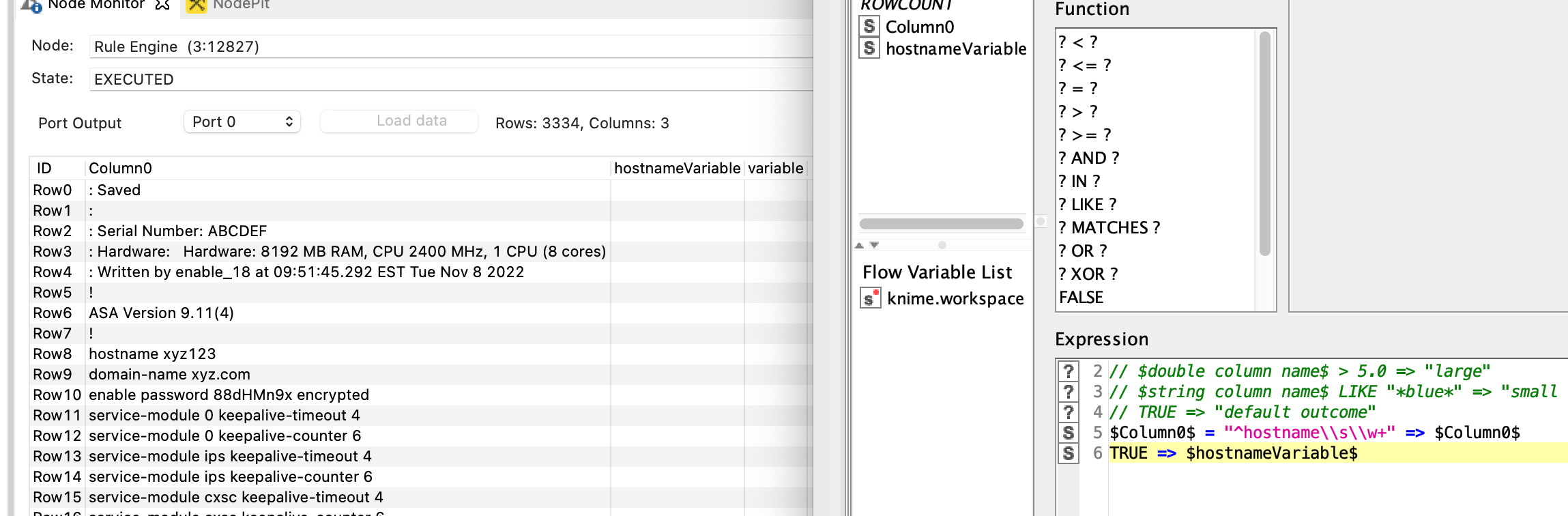
@takbb I was able to make the original portion work but only adding the < hostname xyz > manually, no regex, I have used the following expression “hostname\s\w+$” , I have also tried “^+hostname\s\w” & “^+hostname\s\w+”
Hi, so I see that a lot of your problem stems from needing to clean the data, but there were a couple of small errors.
I replaced the Column Expressions for cleaning the newlines with a String Replacer using Regex. That was showing a simpler alternative - and it replaced the Column Rename.
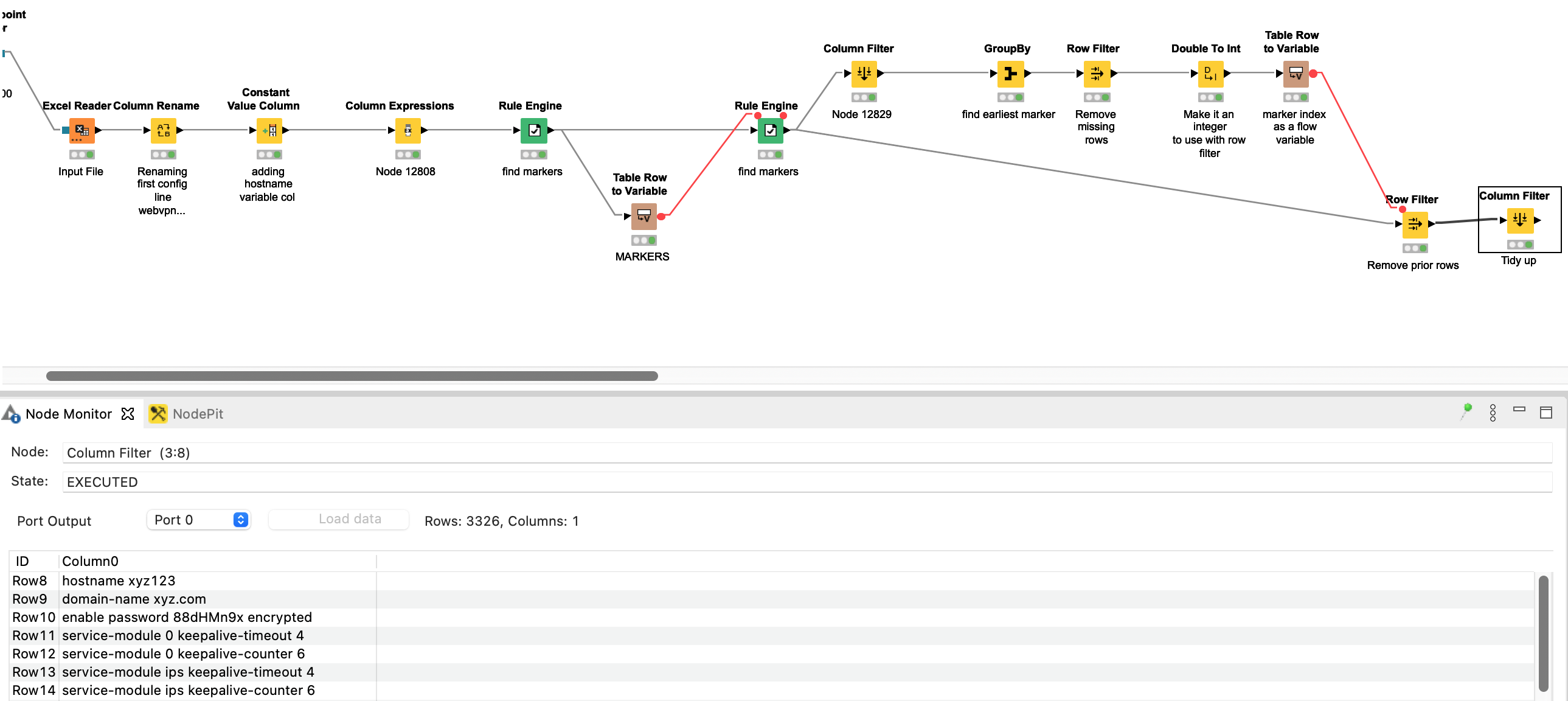
The attached makes the regex works both in your column expressions (which had a bug… but not in the regex ;-)) and with the Rule Engine, so you might want to see what the changes were… forum - Remove Rows Up to Specific Row 1a.knwf (29.5 KB)
@takbb Perfect. You showed me in a couple different ways of doing it. I appreciate it. I also got introduced to the String Replacer of new lines, I didn’t know that one, Thanks for that too.
This gets me to the code cleanUp portion. How should I approach the groupBy chunks using a ‘dictionary’ perhaps? Which is where the spreadsheet takes me after the clean up?
Going back to the original… the only actual difference between this and the end result is that you needed to clean the data for regex to work, but apart from that to use a regex pattern in the Rule Engine it is
instead of
hope that helps
EDIT: and the other thing to note is Rule Engine is one of the places in KNIME where you DON’T double-backslash in Regex…
@takbb it definitely does. I saw where I made the mistake on the Rule Engine. Cool. Bet you I won’t be making it again. I can try to open a new Threat about the Group in Chunks, would that work better?
If you have additional stuff here that needs resolving, but is effectively a new task then yes I’d say start a new thread posting up some data from the END of this workflow as the Starting point (i.e. maybe post that as a table) and explain in simple terms what you are now wanting to do with it. I’m not sure I’ve understood what it is that you are now wanting to do, and nobody is going to want to go wading through 16+ posts here in this topic to try to work out what is going on
So if you are happy that you have a means of solving this particular issue (ie remove rows prior to a specific row) then I suggest marking this as “solved” so people don’t keep coming in here to help!
After that, yes fire away with a new question on a new topic (giving as much detail as possible, but without adding to people’s confusion