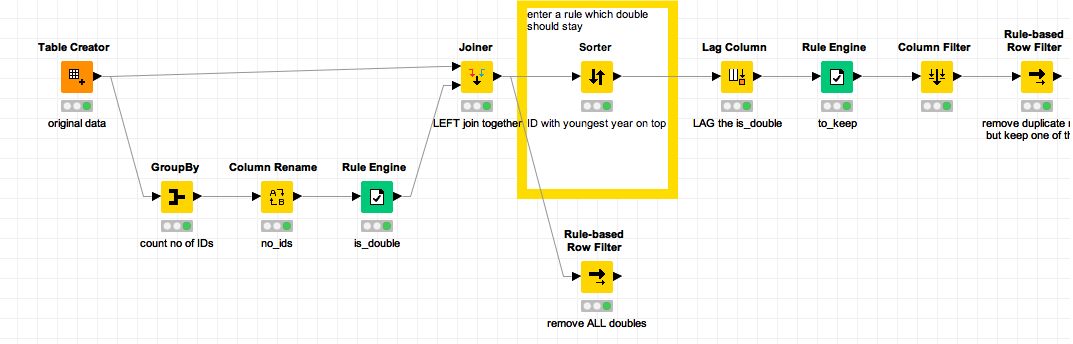
I set up a workflow to demonstrate how this could be done
- use group by to calculate how many duplicates there are (note: KNIME should introduce a generic COUNT(*) function - I had to use a variable)
- if the count is larger then 1 it is a duplicate
- left join it back to the original data
- sort the data by ID and other variables if you want to keep one of the duplicates
- use the LAG column to identify which line is a 2nd, 3rd occurrence of a duplicate
- make a rule to keep just a single line of each ID
- alternative: just remove all duplicates
before
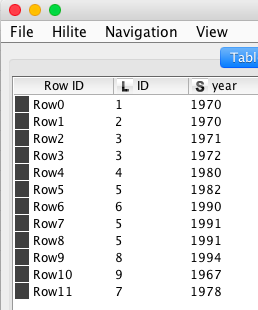
after
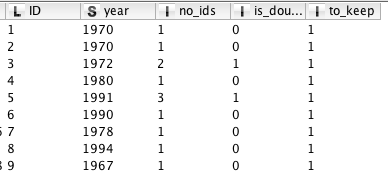
kn_example_duplicates.knwf (44.9 KB)