Hi Together,
i am quite new in the Knime world and would need your help to create a logic with specific rules for a “simple” duplicate row removal.
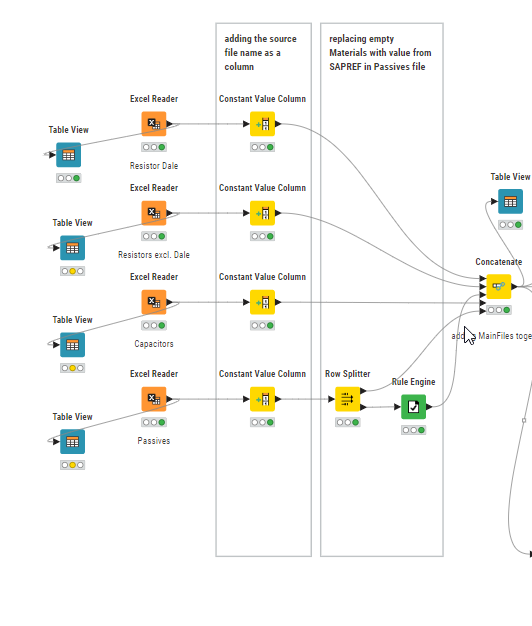
I have 4 excel files (Resistors, DaleResistors, Passives and Capacitors) that hold a material column and other columns like MOQ, Pack, Leadtimes etc.
With
Excel Reader Node
Constant Value Column Node
(to add a “Sourcefile” column with the name of the file like “Resistors”)
and Concatenate Node
i combined those 4 files together.
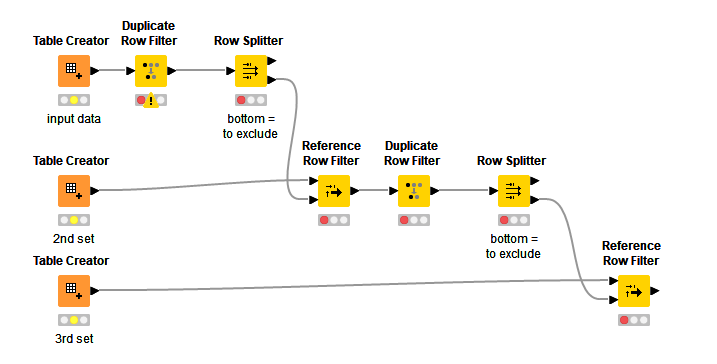
With a Duplicate Row Filter i would be able to identify all duplicated lines by column “Material”.
Now the question is:
I need a way to say
if a duplicate line is from Sourcefile “Passives” use that line and skip the other duplicated lines for that Material.
Else
if a duplicate line is from Sourcefile “Resistors” or “Capacitors” or “DaleResistors” use the first line found and skip the other duplicated lines for that Material.
As i have no clue which nodes are the best to use for that, are you able to help me?
I thought of an Rule Engine Node but i have no clue of programming really.
Thanks.
the Concatenate file has 1,5 Million Lines so probably not a good idea to share and even confidential. But i will try to give you at least some feedback:
and the data would look like that. Conc File.xlsx (10.6 KB)
So based on column Z “SourceFile” i need to identify that the duplicated line comes from file Passives and this line stays, all others should be removed.
If there are duplicates based on the other files, example line 1 (Capacitors) and Line 2 (Resistors), then the “First Line” should be the chosen one and the other deleted.
In Excel i would just do a split in sheets for each Sourcefile and vlookup the Materials, if found, delete from all the others then Passive and if Passive is not involved keep one of the Sourcefile.
So not so complicated, but of course i would like to do that in Knime
thanks a lot for your help,
i did it now with a “DuplicationPriority” 1,2,3 and 4 by adding the numbers as a “constant value column”
and
took the Duplicate Row filter Node with the -Row chosen in case of duplicate- by “Minimum Of” and as selection the column “DuplicationPriority”.