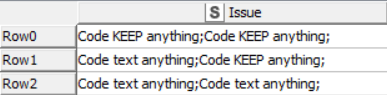
and I would like to:
a) keep all strings betwen semicolons ‘;’ that contains ‘KEEP’ word;
b) remove (make blank) all other strings that don’t contain ‘KEEP’ word.
The expected outcome for the above example would be:
There might be dozens of semicolons in my real data.
I’m applying ‘Cell Splitter’ node (works OK) and trying ‘String Manipulation (Multi Column)’ however I’m not sure how to build an expression with the following meaning:
if CURRENTCOLUMN contains KEEP then do nothing,
else remove CURRENTCOLUMN.
Inside the node, you’ll be able to choose to tick the option to ‘Include TRUE matches’ which will keep the rows containing KEEP and remove the rest.
There’s also another option, which is to use the Rule Engine – KNIME Community Hub Node but this one doesn’t automatically remove rows for you, and the script needs to be adjusted a bit.
@badger101 , @Kazimierz probably regex might be better here if the requirement is to look for the word “KEEP”. A LIKE "*KEEP*" condition will not look for the word “KEEP”, but rather any string containing “KEEP”. For example, “KEEPING”, or “KEEPER” (BOOKEEPING, BOOKEEPER, GOALKEEPER, HOUSEKEEPING, HOUSEKEEPER, PEACEKEEPING, PEACEKEEPER, etc) would qualify for LIKE "*KEEP*", but they’re not supposed to qualify as “KEEP” as a word as per the request
And if you are going to use regex, you may not need to split the strings into cells, you can come up with a regex that will look for the word “KEEP” between the colons “;”.
That’s correct! The exact solution will depend on what the real phrase is, and what word morphology exists in the corpus for that phrase. I suspect that @Kazimierz is using a dummy phrase KEEP just as an example.
Hi @badger101 , indeed you have a very valid point there. Since they’re dummy data (as they look like now that you mentioned it), it might not show all the cases, whether they’re restricted to word or substring of a word.
Based on the presumably dummy data provided, (looking at the semicolons and the the word ‘Code’) one thing that struck my mind was that it looked like @Kazimierz is looking for a signature in a javascript file/web source code. An example of that would be finding the Google Analytics info via the phrase “gtag.js” or “analytics.js”
Hence I suggested the simple script that doesn’t really need the considerations like one would normally think of in a typical English-language text processing task (e.g. spaces, decimals, morphology). I was expecting them to try it out on the real data and provide feedback so I could have the opportunity to know more about the ACTUAL data so as to provide a better solution if needed.
Thank you very much for your responses and suggestions.
You are right: data and ‘KEEP’ words are dummy data/string. In fact, more complex data is behind data shown, and there string is managed by variable.
I will play with your suggestions and come back with my findings.
@badger101 Rule-based Row Filter works on entire rows, while I need to work on cells only. However, if I would like to proceed with rows than your suggestion could be OK.
@bruno29a As I wrote above, dummy ‘KEEP’ string is in reality controlled by variable, thus I haven’t tried your suggestion. However, I’m sure it might work OK as takes into account the context.
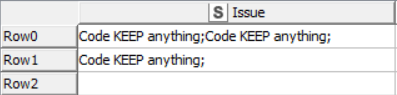
@HansS Your suggestion is what I was looking for! Here is the prove: input vs. output columns based on dummy data:
Of course, I’ve modified your workflow to match my workflow, but the outcome meets my expectations.
Thank you All very much again, and special thanks go to @HansS!